Spring Boot集成sharding-jdbc实现分库分表
一、水平分割
1、水平分库
1)、概念:
以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中。
2)、结果
每个库的结构都一样;数据都不一样;
所有库的并集是全量数据;
2、水平分表
1)、概念
以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中。
2)、结果
每个表的结构都一样;数据都不一样;
所有表的并集是全量数据;
二、Shard-jdbc 中间件
1、架构图
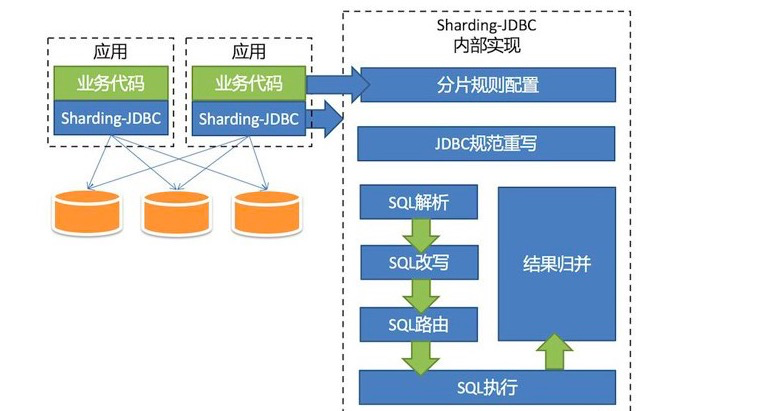
2、特点
1)、Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零。
2)、适用于任何基于Java的ORM框架,如Hibernate、Mybatis等 。
3)、可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
4)、以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖。
5)、分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
6)、SQL解析功能完善,支持聚合、分组、排序、limit、or等查询。
三、项目演示

核心代码块
数据源配置文件
spring:
datasource:
# 数据源:shard_one
dataOne:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_one?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_two
dataTwo:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_two?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 数据源:shard_three
dataThree:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/shard_three?useUnicode=true&characterEncoding=UTF8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: 123
initial-size: 10
max-active: 100
min-idle: 10
max-wait: 60000
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
max-evictable-idle-time-millis: 60000
validation-query: SELECT 1 FROM DUAL
# validation-query-timeout: 5000
test-on-borrow: false
test-on-return: false
test-while-idle: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
数据库分库策略
/**
* 数据库映射计算
*/
public class DataSourceAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(DataSourceAlg.class);
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分库算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "ds_" + ((hash % 2) + 2) ;
}
}
数据表1分表策略
/**
* 分表算法
*/
public class TableOneAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableOneAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_one_" + (hash % 5+1);
}
}
数据表2分表策略
/**
* 分表算法
*/
public class TableTwoAlg implements PreciseShardingAlgorithm<String> {
private static Logger LOG = LoggerFactory.getLogger(TableTwoAlg.class);
/**
* 该表每个库分5张表
*/
@Override
public String doSharding(Collection<String> names, PreciseShardingValue<String> value) {
LOG.debug("分表算法参数 {},{}",names,value);
int hash = HashUtil.rsHash(String.valueOf(value.getValue()));
return "table_two_" + (hash % 5+1);
}
}
数据源集成配置
/**
* 数据库分库分表配置
*/
@Configuration
public class ShardJdbcConfig {
// 省略了 druid 配置,源码中有
/**
* Shard-JDBC 分库配置
*/
@Bean
public DataSource dataSource (@Autowired DruidDataSource dataOneSource,
@Autowired DruidDataSource dataTwoSource,
@Autowired DruidDataSource dataThreeSource) throws Exception {
ShardingRuleConfiguration shardJdbcConfig = new ShardingRuleConfiguration();
shardJdbcConfig.getTableRuleConfigs().add(getTableRule01());
shardJdbcConfig.getTableRuleConfigs().add(getTableRule02());
shardJdbcConfig.setDefaultDataSourceName("ds_0");
Map<String,DataSource> dataMap = new LinkedHashMap<>() ;
dataMap.put("ds_0",dataOneSource) ;
dataMap.put("ds_2",dataTwoSource) ;
dataMap.put("ds_3",dataThreeSource) ;
Properties prop = new Properties();
return ShardingDataSourceFactory.createDataSource(dataMap, shardJdbcConfig, new HashMap<>(), prop);
}
/**
* Shard-JDBC 分表配置
*/
private static TableRuleConfiguration getTableRule01() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_one");
result.setActualDataNodes("ds_${2..3}.table_one_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableOneAlg()));
return result;
}
private static TableRuleConfiguration getTableRule02() {
TableRuleConfiguration result = new TableRuleConfiguration();
result.setLogicTable("table_two");
result.setActualDataNodes("ds_${2..3}.table_two_${1..5}");
result.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new DataSourceAlg()));
result.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("phone", new TableTwoAlg()));
return result;
}
}Spring Boot集成sharding-jdbc实现分库分表的更多相关文章
- Sharding Sphere的分库分表
什么是 ShardingSphere? 1.一套开源的分布式数据库中间件解决方案 2.有三个产品:Sharding-JDBC 和 Sharding-Proxy 3.定位为关系型数据库中间件,合理在分布 ...
- spring boot:shardingsphere多数据源,支持未分表的数据源(shardingjdbc 4.1.1)
一,为什么要给shardingsphere配置多数据源? 1,shardingjdbc默认接管了所有的数据源, 如果我们有多个非分表的库时,则最多只能设置一个为默认数据库, 其他的非分表数据库不能访问 ...
- Spring Boot中整合Sharding-JDBC单库分表示例
本文是Sharding-JDBC采用Spring Boot Starter方式配置第二篇,第一篇是读写分离讲解,请参考:<Spring Boot中整合Sharding-JDBC读写分离示例> ...
- Spring boot项目集成Sharding Jdbc
环境 jdk:1.8 framework: spring boot, sharding jdbc database: MySQL 搭建步骤 在pom 中加入sharding 依赖 <depend ...
- 分库分表技术演进&最佳实践
每个优秀的程序员和架构师都应该掌握分库分表,这是我的观点. 移动互联网时代,海量的用户每天产生海量的数量,比如: 用户表 订单表 交易流水表 以支付宝用户为例,8亿:微信用户更是10亿.订单表更夸张, ...
- 分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html 为什么分库分表后不建议跨分片查询:https://www.jian ...
- 【大数据和云计算技术社区】分库分表技术演进&最佳实践笔记
1.需求背景 移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的.比如 用户表:支付宝8亿,微信10亿.CITIC对公140万,对私8700万. 订单表:美团每天几千 ...
- java 取模运算% 实则取余 简述 例子 应用在数据库分库分表
java 取模运算% 实则取余 简述 例子 应用在数据库分库分表 取模运算 求模运算与求余运算不同.“模”是“Mod”的音译,模运算多应用于程序编写中. Mod的含义为求余.模运算在数论和程序设计中 ...
- spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现
分布式读写分离和分库分表采用sharding-jdbc实现. sharding-jdbc是当当网推出的一款读写分离实现插件,其他的还有mycat,或者纯粹的Aop代码控制实现. 接下面用spring ...
随机推荐
- hibernate 中持久化标识 OID
OID 全称是 Object Identifier,又叫做对象标识符 是 hibernate 用于区分两个对象是否是同一个对象的标识的方法 标识符的作用:可以让 hibernate 来区分多个对象是否 ...
- P1014_Cantor表 (JAVA语言)
题目描述 现代数学的著名证明之一是Georg Cantor证明了有理数是可枚举的.他是用下面这一张表来证明这一命题的: 1/11/1 , 1/21/2 , 1/31/3 , 1/41/4, 1/51/ ...
- LayUi表单模块无法正常显示
问题: 当我们再使用LayUI的Form表单模块时,我们会把自己需要的表单赋值到我们的页面中,但是会出现无法正常显示的问题,如下: 出现原因: LayUI官方文档也明确表示:"当你使用表单时 ...
- Ceph 14.2.5-K8S 使用Ceph存储实战 -- <6>
K8S 使用Ceph存储 PV.PVC概述 管理存储是管理计算的一个明显问题.PersistentVolume子系统为用户和管理员提供了一个API,用于抽象如何根据消费方式提供存储的详细信息.于是引入 ...
- Java中的equals()和hashCode() - 超详细篇
前言 大家好啊,我是汤圆,今天给大家带来的是<Java中的equals()和hashCode() - 详细篇>,希望对大家有帮助,谢谢 文章纯属原创,个人总结难免有差错,如果有,麻烦在评论 ...
- java面试-JDK自带的JVM 监控和性能分析工具用过哪些?
一.JDK的命令行工具 1.jps(JVM Process Status Tools):虚拟机进程状况工具 jps -l 2.jinfo(Configuration Info for java):Ja ...
- SQL必知必会,带你系统学习
你一定听说过大名鼎鼎的Oracle.MySQL.MongoDB等,这些数据库都是基于一个语言标准发展起来的,那就是SQL. SQL可以帮我们在日常工作中处理各种数据,如果你是程序员.产品经理或者是运营 ...
- SQL Server CDC配合Kafka Connect监听数据变化
写在前面 好久没更新Blog了,从CRUD Boy转型大数据开发,拉宽了不少的知识面,从今年年初开始筹备.组建.招兵买马,到现在稳定开搞中,期间踏过无数的火坑,也许除了这篇还很写上三四篇. 进入主题, ...
- IdentityServer4+OAuth2.0+OpenId Connect 详解
一 Oauth 2.0 1 定义 OAuth(开放授权)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表),而无需将用户名和密码提供给第三方应用. ...
- 按照自己的思路去研究Spring AOP源码【1】
目录 一个例子 Spring AOP 原理 从@EnableAspectJAutoProxy注解入手 什么时候会创建代理对象? 方法执行时怎么实现拦截的? 总结 问题 参考 一个例子 // 定义一个切 ...