[swarthmore cs75] Compiler 6 – Garbage Snake
课程回顾
Swarthmore学院16年开的编译系统课,总共10次大作业。本随笔记录了相关的课堂笔记以及第9次大作业。
- 赋值的副作用:循环元组

下面的代码展示了Python3是如何处理循环列表(print和==):>>> x = [1, 2]
>>> x[1] = x
>>> print(x)
[1, [...]]
>>> y = [1, 2]
>>> y[1] = y
>>> x is y
False
>>> x is x
True
>>> y is y
True
>>> x == y
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RecursionError: maximum recursion depth exceeded in comparison
- 内存管理(Memory Management):维护一个free list数据结构,或者将元数据存储到堆中,用来标记空闲的空间。

- 自动内存管理(Automatic Memory Management)
维护引用数
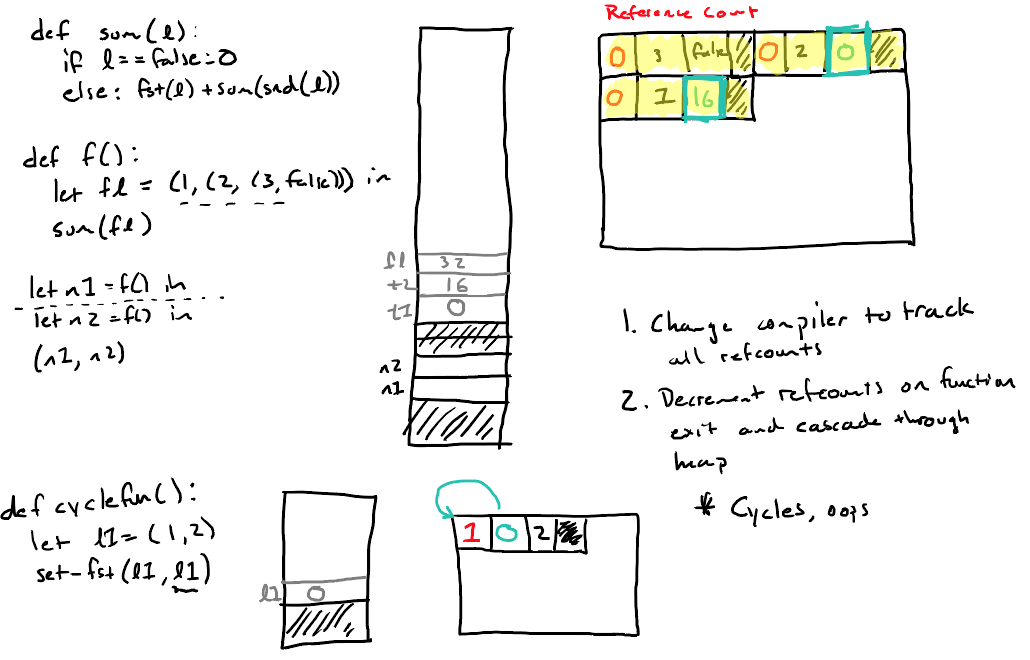
维护标记
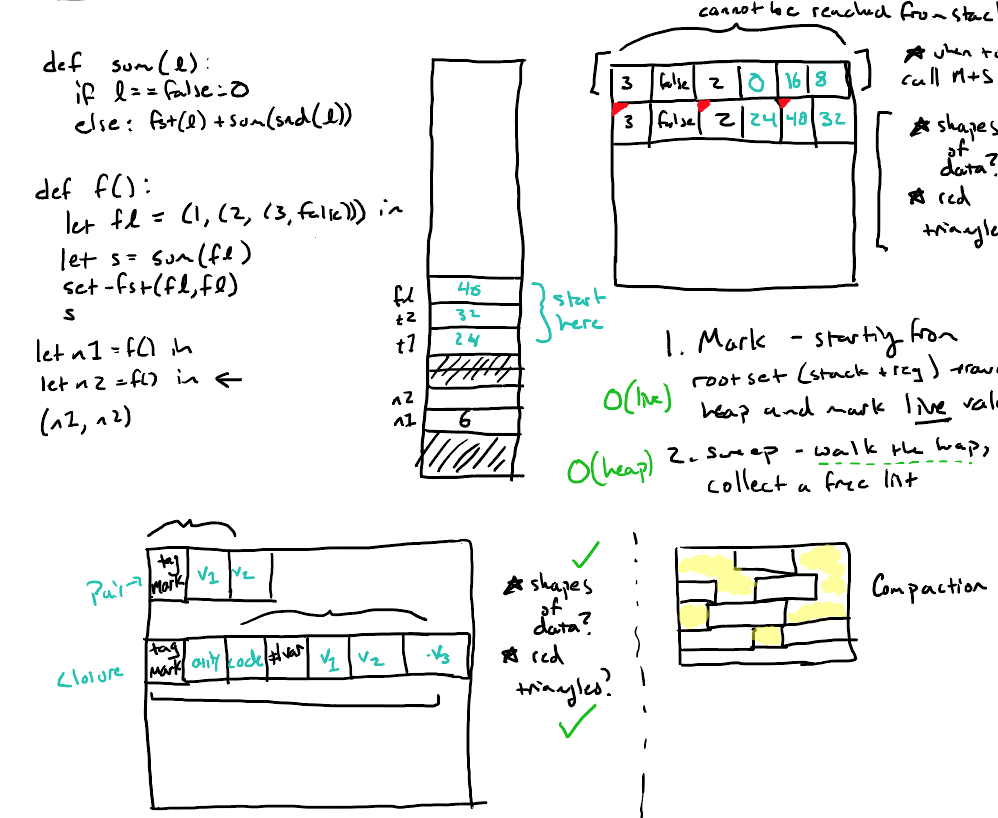
- 标记缩并垃圾回收算法(mark/compact algorithm)
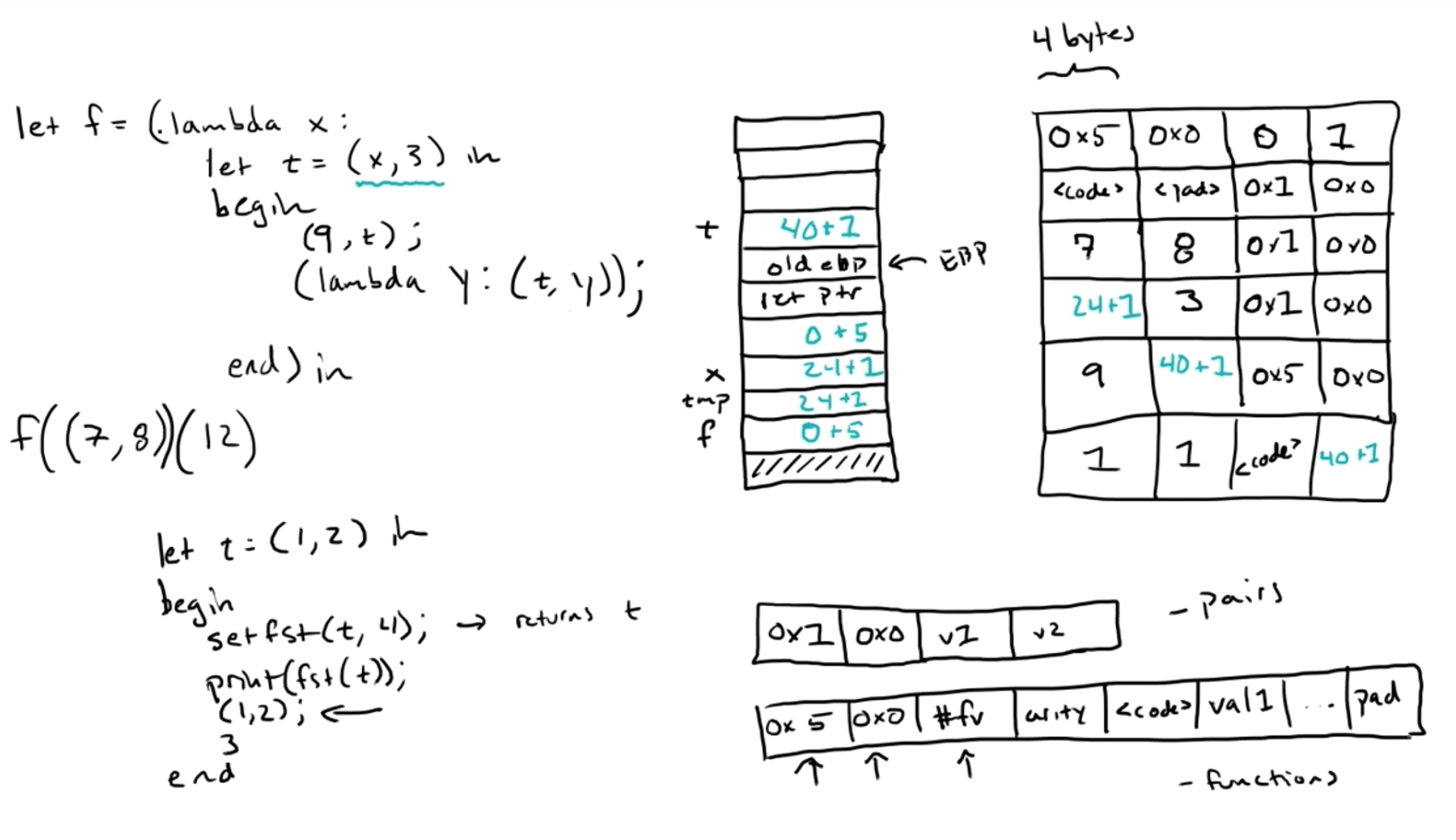
下图展示了f((7, 8))执行时的堆栈情况,这时候内存空间已满,需要进行垃圾收集。
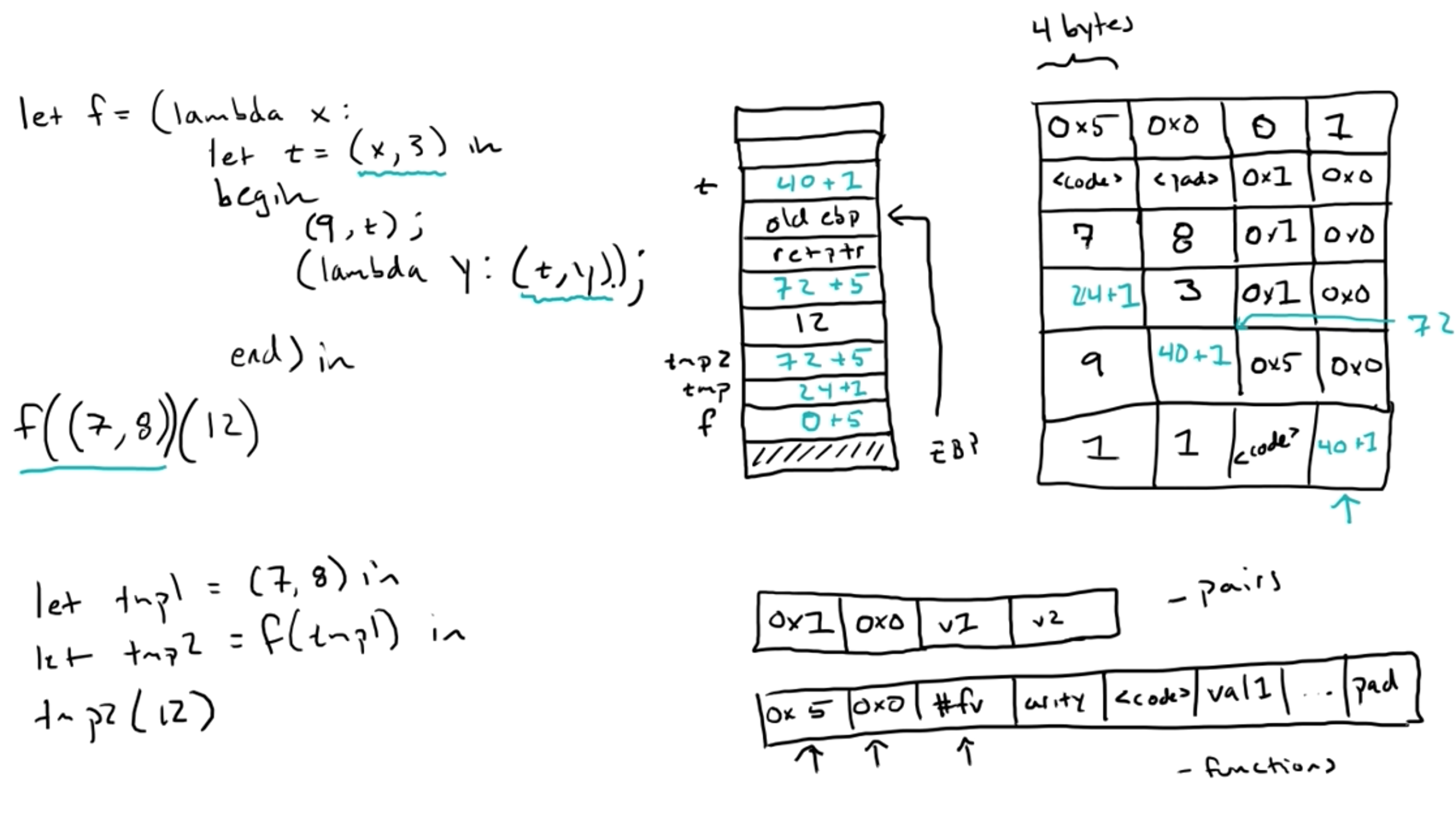
下图展示了f((7, 8))(12)执行时的堆栈情况
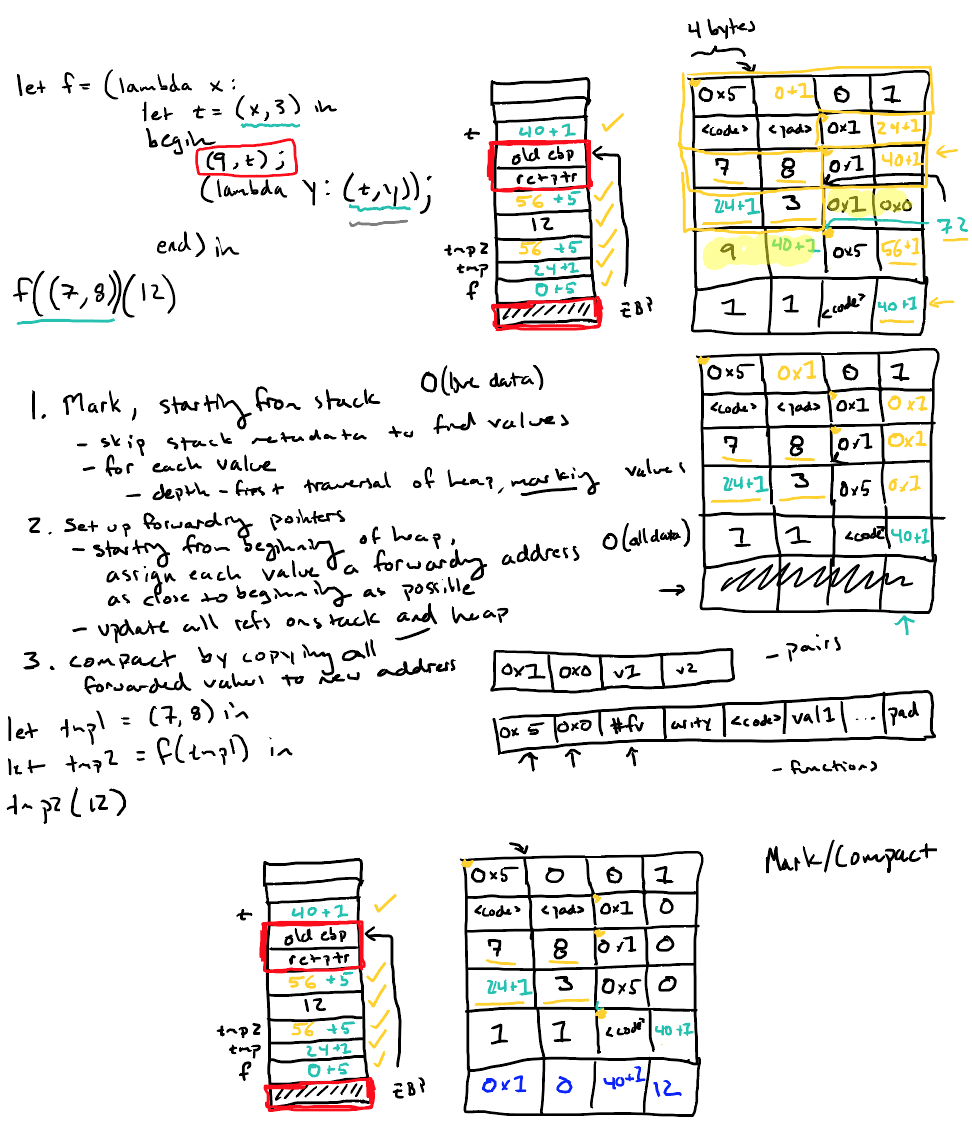
下图是回收算法的实现细节
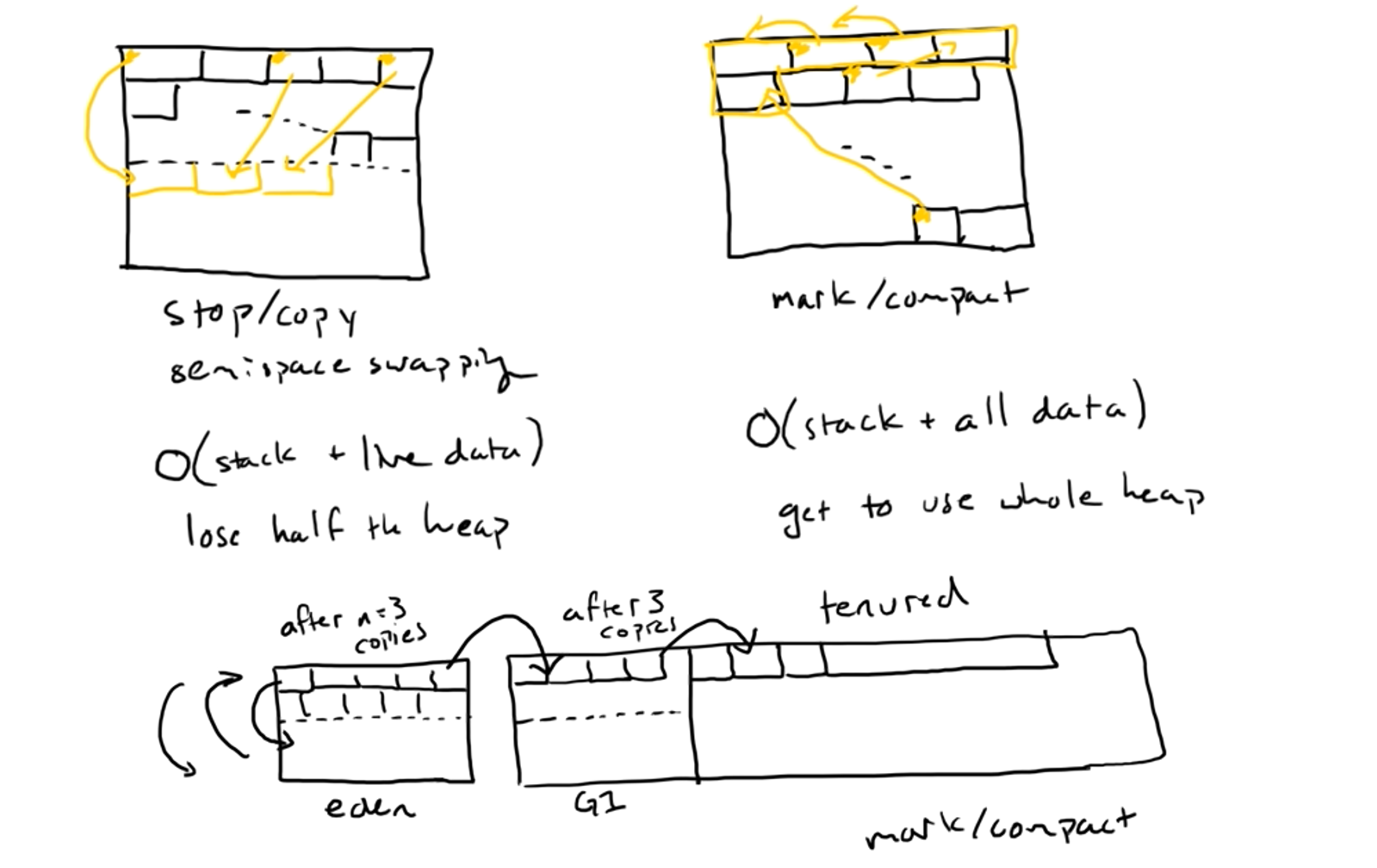
- General GC
在eden区域中,使用semispace swapping将live的data拷贝到堆区的下半部分;如果超过了移动次数,将其拷贝到G1区域,依次进行;
在tenured区域中使用mark/compact算法进行垃圾回收,这个区域中的数据不会频繁的被销毁或移动。
编程作业
Mark
In the first phase, we take the initial heap and stack, and set all the GC words of live data to 1. The live data is all the data reachable from references on the stack, excluding return pointers and base pointers (which don't represent data on the heap). We can do this by looping over the words on the stack, and doing a depth-first traversal of the heap from any reference values (pairs or closures) that we find.
The stack_top and first_frame arguments to mark point to the top of the stack, which contains a previous base pointer value, followed by a return pointer. If f had local variables, then they would cause stack_top to point higher. stack_bottom points at the highest (in terms of number) word on the stack. Thus, we want to loop from stack_top to stack_bottom, traversing the heap from each reference we find. We also want to skip the words corresponding to first_frame and the word after it, and each pair of base pointer and return pointer from there down (if there are multiple function calls active).
Along the way, we also keep track of the highest start address of a live value to use later, which in this case is 64, the address of the closure
int get_heap_index(int* current_addr, int offset, int* heap_start) {
return (*current_addr + offset - (int)heap_start) / 4;
}
void mark_dfs(int* current_addr, int* heap_start, int* max_index) {
// pair: [ tag ][ GC word ][ value ][ value ]
if ((*current_addr & 0x00000007) == 1) {
DEBUG_PRINT("pair: %#010x\n", *current_addr - 1);
int index = get_heap_index(current_addr, -1, heap_start);
if (!heap_start[index + 1]) {
heap_start[index + 1] = 0x1;
if (index > *max_index) *max_index = index;
mark_dfs(&heap_start[get_heap_index(current_addr, 7, heap_start)], heap_start, max_index);
mark_dfs(&heap_start[get_heap_index(current_addr, 11, heap_start)], heap_start, max_index);
}
}
// closure: [ tag ][ GC word ][ varcount = N ][ arity ][ code ptr ][[ N vars' data ]][ maybe padding ]
else if ((*current_addr & 0x00000007) == 5) {
DEBUG_PRINT("closure: %#010x\n", *current_addr - 5);
int index = get_heap_index(current_addr, -5, heap_start);
if (!heap_start[index + 1]) {
heap_start[index + 1] = 0x1;
if (index > *max_index) *max_index = index;
int arity = heap_start[index + 3];
for (int i = 0; i < arity; i++) {
mark_dfs(&heap_start[get_heap_index(current_addr, i * 4 + 15, heap_start)], heap_start, max_index);
}
}
}
}
int* mark(int* stack_top, int* first_frame, int* stack_bottom, int* heap_start) {
int max_index = 0;
for (int* stack_current = stack_top; stack_current != stack_bottom; stack_current++) {
// skip the words corresponding to first_frame and the word after it,
// and each pair of base pointer and return pointer from there down (if there are multiple function calls active).
if (*stack_current != *first_frame && *stack_current != *(first_frame + 1)) {
DEBUG_PRINT("stack_current: %#010x\n", *stack_current);
mark_dfs(stack_current, heap_start, &max_index);
}
}
return heap_start + max_index;
}
Forward
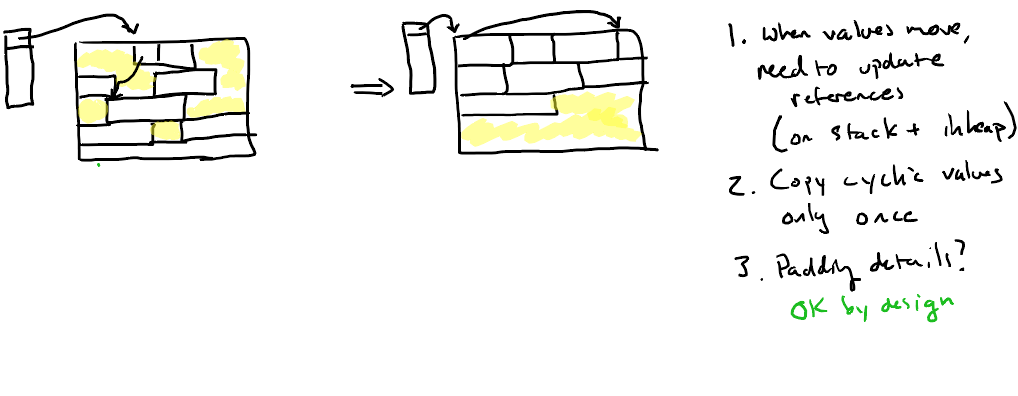
To set up the forwarding of values, we traverse the heap starting from the beginning (heap_start). We keep track of two pointers, one to the next space to use for the eventual location of compacted data, and one to the currently-inspected value.
For each value, we check if it's live, and if it is, set its forwarding address to the current compacted data pointer and increase the compacted pointer by the size of the value. If it is not live, we simply continue onto the next value – we can use the tag and other metadata to compute the size of each value to determine which address to inspect next. The traversal stops when we reach the max_address stored above (so we don't accidentally treat the undefined data in spaces 72-80 as real data).
Then we traverse all of the stack and heap values again to update any internal pointers to use the new addresses.
In this case, the closure is scheduled to move from its current location of 64 to a new location of 16. So its forwarding pointer is set, and both references to it on the stack are also updated. The first tuple is already in its final position (starting at 0), so while its forwarding pointer is set, references to it do not change.
void forward_dfs(int* current_addr, int* heap_start) {
if ((*current_addr & 0x00000007) == 1) {
int index = get_heap_index(current_addr, -1, heap_start);
int gc_tag = heap_start[index + 1];
if (gc_tag != 0x0 && gc_tag != 0x1) {
DEBUG_PRINT("gc_tag: %p\n", (int *)gc_tag);
forward_dfs(&heap_start[get_heap_index(current_addr, 7, heap_start)], heap_start);
forward_dfs(&heap_start[get_heap_index(current_addr, 11, heap_start)], heap_start);
*current_addr = gc_tag;
}
} else if ((*current_addr & 0x00000007) == 5) {
int index = get_heap_index(current_addr, -5, heap_start);
int gc_tag = heap_start[index + 1];
if (gc_tag != 0x0 && gc_tag != 0x1) {
int arity = heap_start[index + 3];
for (int i = 0; i < arity; i++) {
forward_dfs(&heap_start[get_heap_index(current_addr, i * 4 + 15, heap_start)], heap_start);
*current_addr = gc_tag;
}
}
}
}
void forward(int* stack_top, int* first_frame, int* stack_bottom, int* heap_start, int* max_address) {
int* p = heap_start; // current compacted data pointer
int* q = p; // current inspected value pointer
while (q <= max_address) {
int tag = *q;
int gc_word = *(q + 1);
DEBUG_PRINT("tag: %d\n", tag);
DEBUG_PRINT("gc_word: %d\n", gc_word);
// pair
if ((tag & 0x00000007) == 1) {
if (gc_word) {
*(q + 1) |= (int)p;
p += 4;
}
q += 4;
}
// closure
else if ((tag & 0x00000007) == 5) {
int frees = *(q + 3);
int needed_space = 5 + frees;
int with_padding = needed_space + needed_space % 2;
if (gc_word) {
*(q + 1) |= (int)p;
p += with_padding;
}
q += with_padding;
}
}
// traverse all of the stack and heap values again to update any internal pointers to use the new addresses.
for (int* stack_current = stack_top; stack_current != stack_bottom; stack_current++) {
if (*stack_current != *first_frame && *stack_current != *(first_frame + 1)) {
forward_dfs(stack_current, heap_start);
}
}
return;
}
Compact
Finally, we travers the heap, starting from the beginning, and copy the values into their forwarding positions. Since all the internal pointers and stack pointers have been updated already, once the values are copied, the heap becomes consistent again. We track the last compacted address so that we can return the first free address—in this case 40—which will be returned and used as the new start of allocation. While doing so, we also zero out all of the GC words, so that the next time we mark the heap we have a fresh start.
I also highly recommend that you walk the rest of the heap and set the words to some special value. The given tests suggest overwriting each word with the value 0x0cab005e – the “caboose” of the heap. This will make it much easier when debugging to tell where the heap ends, and also stop a runaway algorithm from interpreting leftover heap data as live data accidentally.
int* compact(int* heap_start, int* max_address, int* heap_end) {
int start_index;
int offset;
int size;
for (int i = 0; (heap_start + i) <= max_address; ) {
int tag = *(heap_start + i);
int *gc_tag = heap_start + i + 1;
if ((tag & 0x00000007) == 1) {
size = 4;
offset = -1;
} else if ((tag & 0x00000007) == 5) {
offset = -5;
int frees = *(heap_start + i + 3);
int needed_space = 5 + frees;
size = needed_space + needed_space % 2;
}
if (*gc_tag == 0x0) {
i += size;
} else {
start_index = get_heap_index(gc_tag, offset, heap_start);
*gc_tag = 0x0;
DEBUG_PRINT("start_index: %d, i: %d\n", start_index, i);
for (int j = start_index; j < start_index + size; j++) {
DEBUG_PRINT("value: %#010x\n", *(heap_start + i + j % 4));
*(heap_start + j) = *(heap_start + i + j % size);
}
i += size;
}
}
for (int i = start_index + size; (heap_start + i) != heap_end; i++) {
*(heap_start + i) = 0x0cab005e;
}
return heap_start + size;
}
Test
➜ starter-garbage git:(master) ✗ ./gctest
heap: 0x7a615160, max address: 0x7a615190
0/0x7a615160: 0x1 (1)
1/0x7a615164: 0x0 (0)
2/0x7a615168: 0x7a615171 (2053198193)
3/0x7a61516c: 0x8 (8)
4/0x7a615170: 0x1 (1)
5/0x7a615174: 0x0 (0)
6/0x7a615178: 0xa (10)
7/0x7a61517c: 0xc (12)
8/0x7a615180: 0xcab005e (212533342)
9/0x7a615184: 0xcab005e (212533342)
10/0x7a615188: 0xcab005e (212533342)
11/0x7a61518c: 0xcab005e (212533342)
12/0x7a615190: 0xcab005e (212533342)
13/0x7a615194: 0xcab005e (212533342)
14/0x7a615198: 0xcab005e (212533342)
15/0x7a61519c: 0xcab005e (212533342)
.
OK (1 test)
参考资料
[swarthmore cs75] Compiler 6 – Garbage Snake的更多相关文章
- [swarthmore cs75] Compiler 6 – Fer-de-lance
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第8次大作业. First-class function: It treats function ...
- [swarthmore cs75] Compiler 5 – Egg-eater
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第7次大作业. 抽象语法: 存储方式: 栈中的数据如果最后三位(tag bits)是001表示元 ...
- [swarthmore cs75] Compiler 4 – Diamondback
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第6次大作业. 函数声明 增加函数声明.函数调用的抽象语法:在转换成anf之前还要检查函数声明和 ...
- [swarthmore cs75] Compiler 3 – Cobra
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第5次大作业. 增加了bool数据表示和比较运算符的支持,具体语法参考下图: 第一种int和bo ...
- [swarthmore cs75] Compiler 2 – Boa
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第4次大作业. A-Normal Form 在80年代,函数式语言编译器主要使用Continua ...
- [swarthmore cs75] Compiler 1 – Adder
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第3次大作业. 编译的过程:首先解析(parse)源代码,然后成抽象语法树(AST),再生成汇编 ...
- [swarthmore cs75] inlab1 — Tiny Compiler
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了inlab1的实践过程. tiny compiler 这个迷你的编译器可以将一个源文件,编译成可执行的二进制代码. ...
- [swarthmore cs75] Lab 1 — OCaml Tree Programming
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第2大次作业. 比较两个lists的逻辑: let rec cmp l ll = match ( ...
- [swarthmore cs75] Lab 0 Warmup & Basic OCaml
课程回顾 Swarthmore学院16年开的编译系统课,总共10次大作业.本随笔记录了相关的课堂笔记以及第1次大作业. 什么是编译 编译就是执行Program->Program'转换的过程,如下 ...
随机推荐
- KCF:High-Speed Tracking with Kernelized Correlation Filters 的翻译与分析(一)。分享与转发请注明出处-作者:行于此路
High-Speed Tracking with Kernelized Correlation Filters 的翻译与分析 基于核相关滤波器的高速目标跟踪方法,简称KCF 写在前面,之所以对这篇文章 ...
- Commit can not be set while enrolled in a transaction
[java] Exception: java.sql.SQLException [java] Message: Commit can not be set while enrolled in a tr ...
- Vue和后台交互的方式
1 vue-resource https://segmentfault.com/a/1190000007087934 2 axios 3 ajax
- 获取select下拉框选中的的值
有一id=test的下拉框,怎么获取选中的那个值呢? 分别使用javascript方法和jquery方法 <select id="test" name="&quo ...
- Jboss项目部署出现java.lang.UnsupportedClassVersionError 问题的解决方法
出现java.lang.UnsupportedClassVersionError 错误的原因,是因为我们使用高版本的JDK编译的Java class文件试图在较低版本的JVM上运行,所报的错误. 解决 ...
- poj2777(线段树)
题目链接:https://vjudge.net/problem/POJ-2777 题意:有L块连续的板子,每块板子最多染一种颜色,有T种(<=30)颜色,刚开始将所有板子染成颜色1,O次操作(包 ...
- JVM、垃圾收集器
1.Java虚拟机原理 所谓虚拟机,就是一台虚拟的机器.他是一款软件,用来执行一系列虚拟计算指令,大体上虚拟机可以分为系统虚拟机和程序虚拟机, 大名鼎鼎的Vmare就属于系统虚拟机,他完全是对物理计算 ...
- Unexpected character '�' (1:0) while parsing file
webpack打包,如果在html中有<img>标签,会打包不成功,因为找不到路径,所只要把图片放样式里就好了
- c++11新标准for循环和lambda表达式
:first-child { margin-top: 0px; } .markdown-preview:not([data-use-github-style]) h1, .markdown-previ ...
- 视频剪辑软件原型-videocut
制作软件:墨刀 分享网址:<iframe src="https://modao.cc/app/fb0e31590711295ebebdf50fff7dd9861b7a9c1d/embe ...