浅谈solr
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr是一个高性能,采用Java5开发,
 Solr
Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
下面我们来看看如何使用solr:
- 解压下载的压缩包,solr 不需要使用Tomcat启动,自带jetty,(我会在文末注上solr下载地址:无需去官网翻墙---慢的一比- -)
- window运行cmd 找到solr解压后的目录: bin/solr.cmd start,solr默认端口为8983 出现如右图所示,即可,表明solr已经启动完毕。

- 访问:http://localhost:8983/solr/ 出现如下页面:
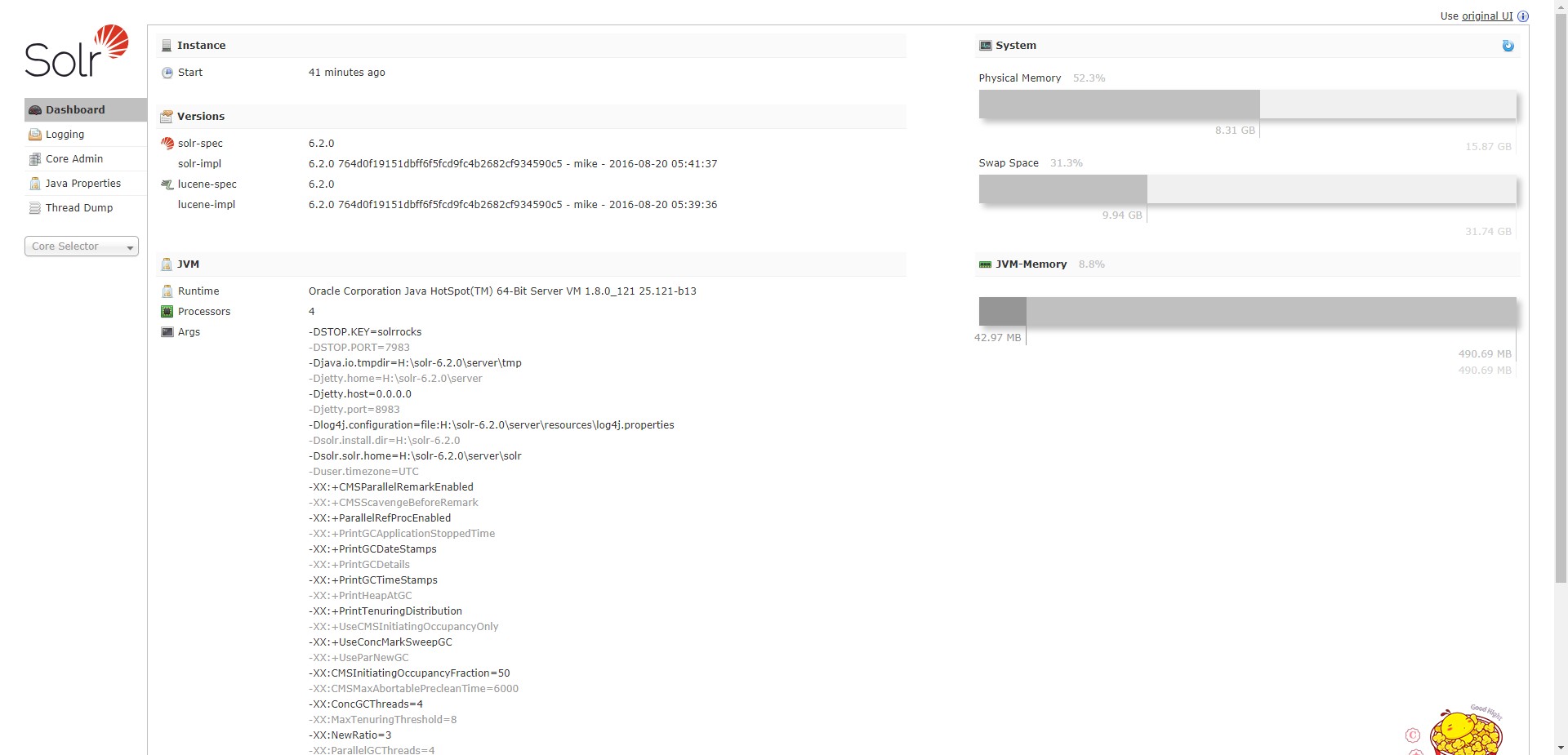
- solr 配置
- 创建core,cmd命令为:solr.cmd create -c articles。其中articles是core的名称,可以自定义。

2. 重启solr:solr restart -p 8983
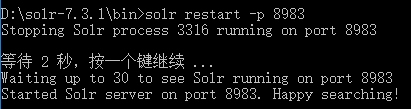
3. 查看core:打开solr控制台,点击"Core Admin",列表中出现"articles",说明core创建成功
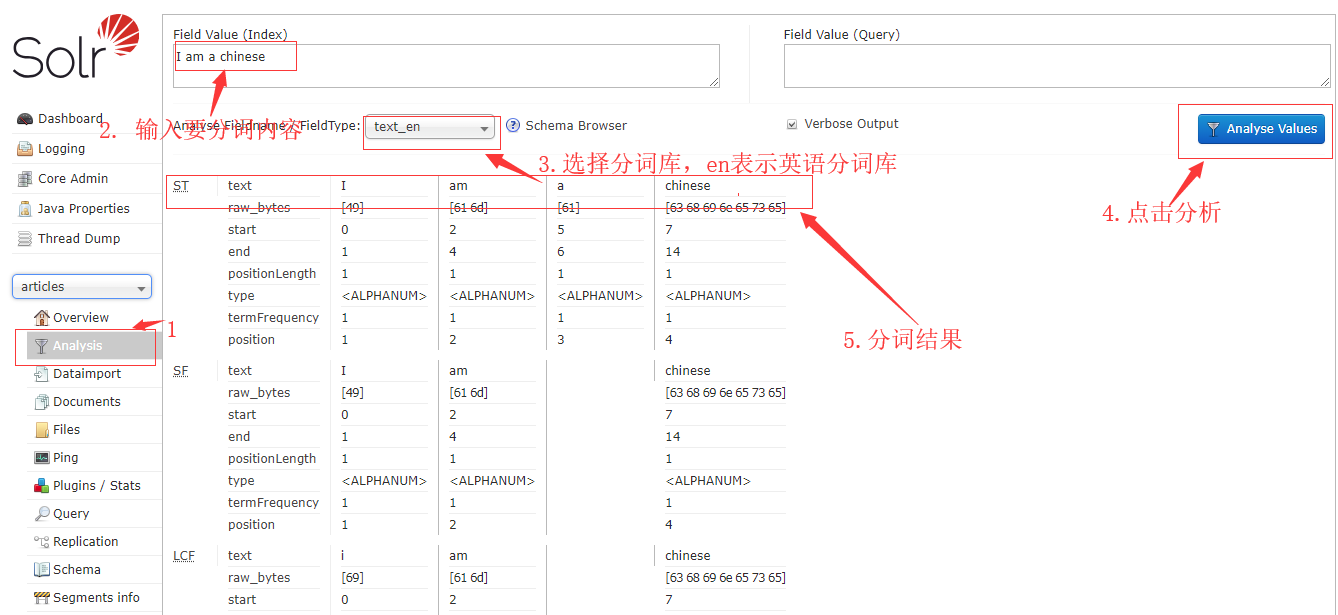
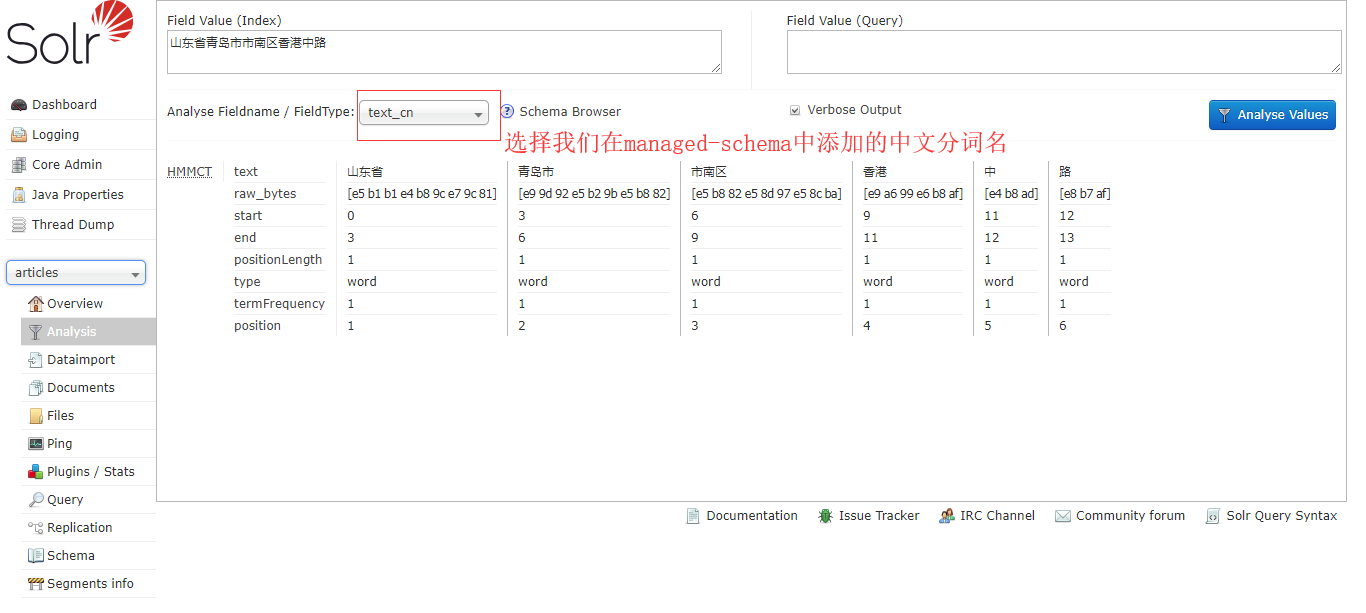
4. 测试分词,选择刚才创建的core,点击Analysis进入分词分析页面,输入要分词的句子,选择分词库,点击分析按钮,即可看到分词结果
solr默认是不支持中文分词的,然而solr已经自带了中文分词的jar包。
中文分词插件配置
添加中文分词插件:solr 7.3中自带中文分词插件,将solr-7.3.1\contrib\analysis-extras\lucene-libs\lucene-analyzers-smartcn-7.3.1.jar 复制到 solr-7.3.1\server\solr-webapp\webapp\WEB-INF\lib 目录中
配置中文分词,修改 solr-7.3.1\server\solr\articles【创建的core的名称】\conf\managed-schema文件,添加中文分词
<!-- Chinese -->
<fieldType name="text_cn" class="solr.TextField" positionIncrementGap="">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
搜索Italian,在Italian下添加我们的中文配置
重启solr,测试中文分词 重启命令 :solr restart -p 8983
至此solr已经配置完毕,接下来是在项目中的简单应用:
找到如下路径的配置文件,notepad++打开
H:\solr-6.2.0\server\solr\articles\conf\managed-schema

然后maven项目中引入solrj相关jar包:
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
<version>5.2.</version>
</dependency>
写一个测试类,代码如下:
package com.sm.utils; import java.io.IOException;
import java.util.List; import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument; import com.sm.modules.xym.user.entity.XymApiUser; public class SolrUtil {
// 指定solr服务器的地址
private final static String SOLR_URL = "http://localhost:8983/solr/"; /**
* 创建SolrServer对象
*
* 该对象有两个可以使用,都是线程安全的 1、CommonsHttpSolrServer:启动web服务器使用的,通过http请求的 2、
* EmbeddedSolrServer:内嵌式的,导入solr的jar包就可以使用了 3、solr
* 4.0之后好像添加了不少东西,其中CommonsHttpSolrServer这个类改名为HttpSolrClient
*
* @return
*/
public HttpSolrClient createSolrServer() {
HttpSolrClient solr = null;
solr = new HttpSolrClient(SOLR_URL);
return solr;
} /**
* 往索引库添加文档
*
* @throws IOException
* @throws SolrServerException
*/
public void addDoc() throws SolrServerException, IOException {
// 构造一篇文档
SolrInputDocument document = new SolrInputDocument();
// 往doc中添加字段,在客户端这边添加的字段必须在服务端中有过定义
document.addField("id", "");
document.addField("name", "周新星");
document.addField("phoneNumber", "");
// 获得一个solr服务端的请求,去提交 ,选择具体的某一个solr core
HttpSolrClient solr = new HttpSolrClient(SOLR_URL + "articles");
solr.add(document);
solr.commit();
solr.close();
} /**
* 根据id从索引库删除文档
*/
public void deleteDocumentById() throws Exception {
// 选择具体的某一个solr core
HttpSolrClient server = new HttpSolrClient(SOLR_URL + "articles");
// 删除文档
server.deleteById("");
server.deleteById("");
// 删除所有的索引
// solr.deleteByQuery("*:*");
// 提交修改
server.commit();
server.close();
} /**
* 查询
*
* @throws Exception
*/
public void querySolr() throws Exception {
HttpSolrClient solrServer = new HttpSolrClient(SOLR_URL + "articles/");
SolrQuery query = new SolrQuery();
// 下面设置solr查询参数
query.set("q", "*:*");// 参数q 查询所有
// query.set("q", "周星驰");// 相关查询,比如某条数据某个字段含有周、星、驰三个字 将会查询出来
// ,这个作用适用于联想查询 // 参数fq, 给query增加过滤查询条件
// query.addFilterQuery("id:[0 TO 9]");// id为0-4 // 给query增加布尔过滤条件
// query.addFilterQuery("description:演员"); //description字段中含有“演员”两字的数据 // 参数df,给query设置默认搜索域
// query.set("df", "name"); // 参数sort,设置返回结果的排序规则
// query.setSort("id", SolrQuery.ORDER.desc); // 设置分页参数
query.setStart();
query.setRows();// 每一页多少值 // 参数hl,设置高亮
// query.setHighlight(true);
// 设置高亮的字段
// query.addHighlightField("name");
// 设置高亮的样式
// query.setHighlightSimplePre("<font color='red'>");
// query.setHighlightSimplePost("</font>"); // 获取查询结果
QueryResponse response = solrServer.query(query);
// 两种结果获取:得到文档集合或者实体对象 // 查询得到文档的集合
SolrDocumentList solrDocumentList = response.getResults();
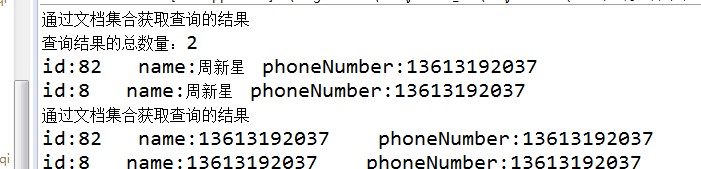
System.out.println("通过文档集合获取查询的结果");
System.out.println("查询结果的总数量:" + solrDocumentList.getNumFound());
// 遍历列表
for (SolrDocument doc : solrDocumentList) {
System.out.println(
"id:" + doc.get("id") + " name:" + doc.get("name") + " phoneNumber:" + doc.get("phoneNumber"));
} // 得到实体对象
List<XymApiUser> tmpLists = response.getBeans(XymApiUser.class);
if (tmpLists != null && tmpLists.size() > ) {
System.out.println("通过文档集合获取查询的结果");
for (XymApiUser per : tmpLists) {
System.out.println(
"id:" + per.getId() + " name:" + per.getName() + " phoneNumber:" + per.getPhoneNumber());
}
}
} public static void main(String[] args) throws Exception {
SolrUtil solr = new SolrUtil();
solr.createSolrServer();
// solr.addDoc();
// solr.deleteDocumentById();
solr.querySolr();
}
}
这样还不能实现数据映射到实体类,我们最后需要在对应实体类XymApiUser.java文件为对应需要映射的字段加上@Field(“name”)注解

这样我们执行一下main方法:
至此solr安装及与项目的基本整合完毕。
solr是一款基于lucene开发的相当强大全文索引工具,极大加快了查询速度,因为使用了分词,所以是精确匹配,能够让查询更简单,更灵活,值得一试。
solr下载地址:链接: https://pan.baidu.com/s/12bno8K9VOYdn42wY0gRfzA 提取码: e8e2
浅谈solr的更多相关文章
- 浅谈springboot自动配置原理
前言 springboot自动配置关键在于@SpringBootApplication注解,启动类之所以作为项目启动的入口,也是因为该注解,下面浅谈下这个注解的作用和实现原理 @SpringBootA ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 浅谈WebService的版本兼容性设计
在现在大型的项目或者软件开发中,一般都会有很多种终端, PC端比如Winform.WebForm,移动端,比如各种Native客户端(iOS, Android, WP),Html5等,我们要满足以上所 ...
- 浅谈angular2+ionic2
浅谈angular2+ionic2 前言: 不要用angular的语法去写angular2,有人说二者就像Java和JavaScript的区别. 1. 项目所用:angular2+ionic2 ...
- iOS开发之浅谈MVVM的架构设计与团队协作
今天写这篇博客是想达到抛砖引玉的作用,想与大家交流一下思想,相互学习,博文中有不足之处还望大家批评指正.本篇博客的内容沿袭以往博客的风格,也是以干货为主,偶尔扯扯咸蛋(哈哈~不好好工作又开始发表博客啦 ...
- Linux特殊符号浅谈
Linux特殊字符浅谈 我们经常跟键盘上面那些特殊符号比如(?.!.~...)打交道,其实在Linux有其独特的含义,大致可以分为三类:Linux特殊符号.通配符.正则表达式. Linux特殊符号又可 ...
随机推荐
- Confluence 6 用户宏示例 - Hello World
下面示例显示了如何创建一个用户宏,在这个用户宏中显示文本 'Hello World!' 和任何用户在宏内容中输入的内容. Macro name helloworld Visibility Visibl ...
- 一道关于js声明变量,var和let的面试题
function aa(flag) { // var test // 变量提升,函数最顶部 if(flag) { var test = 'hello man' } else { //此处访问 test ...
- Java面向对象(二)
一.封装 1.为什么要使用封装在类的外部直接操作类的属性是”不安全的"2.如何实现封装 1).属性私有化:设置属性的修饰符为private 2) .提供公共的set和get方法赋值 ...
- Linux之man命令详解及中文汉化
使用方法 Linux man中的man就是manual的缩写,用来查看系统中自带的各种参考手册 使用方法: man command 示例: [root@VM_0_13_centos ~]# man l ...
- RabbitMQ疑惑释义
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们.消息传递指的是程序之间 ...
- 论文阅读笔记十三:The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation(FC-DenseNets)(CVPR2016)
论文链接:https://arxiv.org/pdf/1611.09326.pdf tensorflow代码:https://github.com/HasnainRaz/FC-DenseNet-Ten ...
- Just Oj 2017C语言程序设计竞赛高级组E: DATE ALIVE(二分匹配)
E: DATE ALIVE 时间限制: 1 s 内存限制: 128 MB 提交 我的状态 题目描述 五河士道家里的精灵越来越多了,而每一个精灵都想和他有一个约会.然而五河士道却只有一个,无奈 ...
- 开始写博客,学习Linq
除了为处理数据提供全新的方法之外,LINQ还代表了一种朝着声明式以及函数式编程发展的转变. 当人们问我为什么要学习LINQ时,我会告诉他们LINQ可以处理XML.关系型数据以及内存中的集合,更会提到L ...
- [转] babel的使用
一.配置文件.babelrc .babelrc 文件存放在项目的根目录下. { "presets": [], "plugins": [] } presets 字 ...
- Git Flow,Git团队协作最佳实践
规范的Git使用 Git是一个很好的版本管理工具,不过相比于传统的版本管理工具,学习成本比较高, 实际开发中,如果团队成员比较多,开发迭代频繁,对Git的应用比较混乱,会产生很多不必要的冲突或者代码丢 ...