【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计
寄存器堆(Register File)是微处理的关键部件之一。寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应。传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元。随着端口数量的增加,集中式寄存器堆的功耗、面积、时序均会呈幂增长,进而可能降低处理器总体性能。
下图所示为传统的集中式寄存器堆结构:

本文讨论一种基于分布存储和面积与时序互换原则的多端口寄存器堆设计,我们暂时称之为“分布式寄存器堆”。该种寄存器从端口使用上,仍与集中式寄存器堆完全兼容,但该寄存器堆使用多个寄存器簇和块分布式地存储操作数。当并行写入时,各寄存器簇分布式地存储写入结果;当读出时,由相应的仲裁算法在多个寄存器簇的结果中选取确定的一个簇作为最终输出。图二显示了这种分布式寄存器堆的逻辑结构。
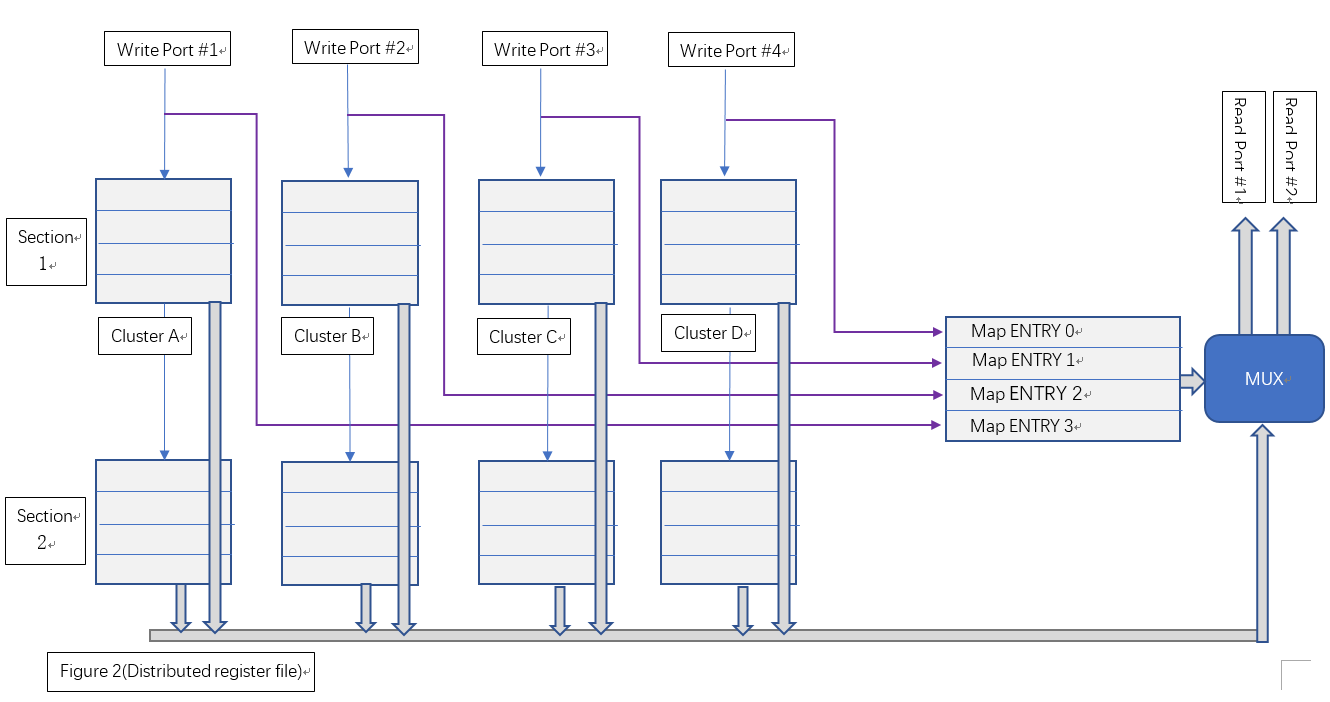
该结构主要由区块(Section)和簇(Cluster)两个维度组织寄存器:
(1)、从Section层面看,Section 1和Section 2是两个完全相同的组成结构(相当于逻辑的复制),同时两个Section中寄存器所持有的操作数也完全相同。一个Section只能处理一个读端口的操作。Section1负责处理读端口#1,而Section2负责处理读端口#2。
(2)、从Cluster层面看,Cluster A、B、C、D是几个分别独立的集中式寄存器堆,其具体结构可等价为一个双口RAM。写入时,Clusters分别独立地写入各自要求的地址。读出时,各Cluster从相同的读出地址读出各自的数据,最后将4个数据送到MUX进行最后的仲裁。
综上,单个Section负责单个读端口操作,单个Cluster负责单个写端口操作。
分布式寄存器堆的设计关键在于仲裁调度算法。由于一个Section只负责处理一个读端口的操作,我们首先从单个Section维度考虑。虽然单个周期内需要同时处理4个写端口,但读端口是唯一的。事先记录每个写端口的地址所对应的Cluster编号,在读出时,通过读出地址反向获取对应的Cluster,进而从该Cluster取出最终结果。
其次再考虑多个读端口并行操作。考虑复制两个相同的Section逻辑,并将所有写端口并联起来,则可以保证两个Section所持有的操作数完全相同。对两个Section同时进行读操作,这样便实现了并行地读出两个不同地址的数据。
接下来设计两个关键部件:Cluster寄存器堆和数据仲裁器。
一、Cluster寄存器的设计
上文已经提到过,Cluster寄存器可等价为双端口RAM。关于DPRAM的具体结构可参考相关资料,本文不再赘述。DPRAM容量根据最为通用的配置,采用32x32bit设计,可通过例化参数设置地址总线和数据总线的宽度。利用Verilog描述一个同步时钟DPRAM的源码如下:
module dpram_sclk
#(
,
,
, // Whether to rest the RAM while initialization (for simulation only)
// Whether enable data bypass
)
(/*AUTOARG*/
// Outputs
dout,
// Inputs
clk, rst, raddr, re, waddr, we, din
);
// Port List
input clk;
input rst;
:] raddr;
input re;
:] waddr;
input we;
:] din;
:] dout;
:] mem[(<<ADDR_WIDTH)-:];
:] rdata;
reg re_r;
:] dout_w;
generate
if(CLEAR_ON_INIT) begin :clear_on_init
integer entry;
initial begin
; entry < (<<ADDR_WIDTH); entry=entry+) // reset
mem[entry] = {DATA_WIDTH{'b0}};
end
end
endgenerate
// bypass control
generate
if (ENABLE_BYPASS) begin : bypass_gen
:] din_r;
reg bypass;
assign dout_w = bypass ? din_r : rdata;
always @(posedge clk)
if (re) din_r <= din;
always @(posedge clk)
if (waddr == raddr && we && re)
bypass <= ;
else
bypass <= ;
end else begin
assign dout_w = rdata;
end
endgenerate
// R/W logic
always @(posedge clk)
re_r <= rst ? 'b0 : re;
'b0}};
always @(posedge clk) begin
if (we)
mem[waddr] <= din;
if (re)
rdata <= mem[raddr];
end
endmodule
module dpram_sclk
值得注意的是,实现中加入了数据旁通机制,保证当发生同时读写且地址相同时,写入数据能在单个操作周期内送达读端口。
二、数据仲裁器的设计
数据仲裁器的核心是维护一个写入地址→Cluster编号的映射表。假设分布式寄存器堆总共有32个寄存器(以5bit地址总线寻址),则我们需要一个表项数为32的列表,存储每个地址对应的Cluster编号。Verilog描述如下:
:] sel_map[(<<ADDR_WIDTH)-:];
对于每个写端口,在写操作周期维护映射表,记录下写入地址对应的Cluster,实现如下:
// Maintain the selection map
always @(posedge clk) begin
if (we1)
sel_map[waddr1] <= 'd0;
if (we2)
sel_map[waddr2] <= 'd1;
if (we3)
sel_map[waddr3] <= 'd2;
if (we4)
sel_map[waddr4] <= 'd3;
end
对于读端口,先从映射表获取实际存储目标操作数的Cluster,然后利用多路复用器选取其输出,作为该Section的最终读取结果。
// mux
'd0 ? dout0 :
sel_map[raddr]=='d1 ? dout1 :
sel_map[raddr]=='d2 ? dout2 :
sel_map[raddr]=='d3 ? dout3 :
{DATA_WIDTH{'b0}}; /* never got this */
由此,我们可以得出单个Section的完整设计:
module cpram_sclk_4w1r #(
,
,
, // Whether to rest the RAM while initialization (for simulation only)
// Whether enable data bypass
)
(/*AUTOARG*/
// Outputs
rdata,
// Inputs
clk, rst, we1, waddr1, wdata1, we2, waddr2, wdata2, we3, waddr3,
wdata3, we4, waddr4, wdata4, re, raddr
);
// Ports
input clk;
input rst;
input we1;
:] waddr1;
:] wdata1;
input we2;
:] waddr2;
:] wdata2;
input we3;
:] waddr3;
:] wdata3;
input we4;
:] waddr4;
:] wdata4;
input re;
:] raddr;
:] rdata;
// Internals
:] dout;
:] dout0;
:] dout1;
:] dout2;
:] dout3;
:] sel_map[(<<ADDR_WIDTH)-:];
// instance of sync dpram #1 for Cluster A
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem0
(
.clk (clk),
.rst (rst),
.dout (dout0),
.raddr (raddr),
.re (re),
.waddr (waddr1),
.we (we1),
.din (wdata1)
);
// instance of sync dpram #2 for Cluster B
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem1
(
.clk (clk),
.rst (rst),
.dout (dout2),
.raddr (raddr),
.re (re),
.waddr (waddr2),
.we (we2),
.din (wdata2)
);
// instance of sync dpram #3 for Cluster C
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem2
(
.clk (clk),
.rst (rst),
.dout (dout3),
.raddr (raddr),
.re (re),
.waddr (waddr3),
.we (we3),
.din (wdata3)
);
// instance of sync dpram #4 for Cluster D
dpram_sclk
#(
.ADDR_WIDTH (ADDR_WIDTH),
.DATA_WIDTH (DATA_WIDTH),
.CLEAR_ON_INIT (CLEAR_ON_INIT),
.ENABLE_BYPASS (ENABLE_BYPASS)
)
mem3
(
.clk (clk),
.rst (rst),
.dout (dout3),
.raddr (raddr),
.re (re),
.waddr (waddr4),
.we (we4),
.din (wdata4)
);
// mux
'd0 ? dout0 :
sel_map[raddr]=='d1 ? dout1 :
sel_map[raddr]=='d2 ? dout2 :
sel_map[raddr]=='d3 ? dout3 :
{DATA_WIDTH{'b0}}; /* never got this */
// Read output with/without bypass controlling
generate
if (ENABLE_BYPASS) begin : bypass_gen
assign rdata =
(we1 && (raddr==waddr1)) ? wdata1 :
(we2 && (raddr==waddr2)) ? wdata2 :
(we3 && (raddr==waddr3)) ? wdata3 :
(we4 && (raddr==waddr4)) ? wdata4 :
dout;
end else begin
assign rdata = dout;
end
endgenerate
// Maintain the selection map
always @(posedge clk) begin
if (we1)
sel_map[waddr1] <= 'd0;
if (we2)
sel_map[waddr2] <= 'd1;
if (we3)
sel_map[waddr3] <= 'd2;
if (we4)
sel_map[waddr4] <= 'd3;
end
endmodule
值得说明的是:上述实现仍然需要考虑四个写端口与一个读端口的数据旁通路径。通过例化参数ENABLE_BYPASS可以指定是否使用数据旁通逻辑。
将两个Section写端口并联,并分别引出其读端口,即构成了一个4w 2r寄存器堆。
总结
本文讨论的数据的分布存储方法和基于面积换时序的逻辑复制方法,在集中存储式寄存器堆的优化中取得了较好的效果。但该结构缺点也十分明显:首先,对集中寄存器堆的复制无疑增加了面积和功耗,其次,随着写端口数的增加,仲裁逻辑的规模也随之增长,这将导致数据路径延迟增加,进而降低寄存器堆时钟工作频率。
相比于ASIC设计,本结构更适合于FPGA验证。理由如下:在FPGA中,寄存器是非常有限的资源。若直接实现一定规模的RAM结构,则需要大量占用寄存器资源。为此,FPGA在硬件上集成了RAM Block资源。这些RAM Blocks多可配置为双端口模式,但对于更复杂的端口配置(如本例的4w2r),则只能间接实现。
本设计完全采用RAM Blocks实现多端口寄存器堆。因为FPGA综合工具在分析verilog源码时,将自动识别出我们所采用的DPRAM,转而使用RAM Block资源,避免占用寄存器资源,为设计的其它部分留出更多可用的寄存器资源。同时,这将避免使用LUT实现复杂的RAM单元寻址和控制逻辑,从而优化时序。
2018 10.20
===================================================
本博文仅供参考,多有疏漏之处,欢迎提出宝贵意见。
【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计的更多相关文章
- 【CPU微架构设计】利用Verilog设计基于饱和计数器和BTB的分支预测器
在基于流水线(pipeline)的微处理器中,分支预测单元(Branch Predictor Unit)是一个重要的功能部件,它负责收集和分析分支/跳转指令的执行结果,当处理后续分支/跳转指令时,BP ...
- ARM架构--CPU的微架构
网上确实有说ARM架构的,但是此架构泛指用ARM指令系统的CPU,而不是CPU的微架构.,硬件电路上,要用ARM指令集系统,必然硬件设计电路上要要遵循,ARM指令的特点和寻址方式,所以说高通和苹果的C ...
- InfoQ一波文章:菜鸟核心技术/Intel发布CPU新架构3D堆栈法/BDL/PaddlePaddle/百度第三代Spider/Tera
菜鸟智慧新物流核心技术全解析 孟靖 阅读数:63192018 年 12 月 14 日 16:00 2018 年天猫双 11 全球狂欢节已正式落下帷幕,最终成交额定格在 2135 亿元,物流订单 ...
- 微服务架构下分布式Session管理
转载本文需注明出处:EAII企业架构创新研究院(微信号:eaworld),违者必究.如需加入微信群参与微课堂.架构设计与讨论直播请直接回复此公众号:“加群 姓名 公司 职位 微信号”. 一.应用架构变 ...
- 手机服务器微架构设计与实现 之 http server
手机服务器微架构设计与实现 之 http server ·应用 ·传输协议和应用层协议概念 TCP UDP TCP和UDP选择 三次握手(客户端与服务器端建立连接)/四次挥手(断开连接)过程图 · ...
- CPU和微架构的概念
CPU是什么: 中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit). 它的功能主要 ...
- Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案
Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案 说明:Java生鲜电商平台中由于采用了微服务架构进行业务的处理,买家,卖家,配送,销售,供应商等进行服务化,但是不可避免存在 ...
- 处理器核、Core、处理器、CPU区别&&指令集架构与微架构的区别&&32位与64位指令集架构说明
1.处理器核.Core.处理器.CPU的区别 严格来说"处理器核"和" Core "是指处理器内部最核心的部分,是真正的处理器内核:而"处理器&quo ...
- 阿里微服务架构下分布式事务解决方案-GTS
虽然微服务现在如火如荼,但对其实践其实仍处于初级阶段.即使互联网巨头的实践也大多是试验层面,鲜有核心业务系统微服务化的案例.GTS是目前业界第一款,也是唯一的一款通用的解决微服务分布式事务问题的中间件 ...
随机推荐
- Kafka connect in practice(3): distributed mode mysql binlog ->kafka->hive
In the previous post Kafka connect in practice(1): standalone, I have introduced about the basics of ...
- pycharm移动项目文件后,运行报错
pycharm移动项目文件后,运行报错: ModuleNotFoundError: No module named 'D:/my_project/my_cases/email139cases/tes ...
- Android 开发 RecyclerView设置间距
实现步骤 首先要创建一个类继承RecyclerView.ItemDecoration 然后重新这个类的getItemOffsets方法,删除方法里的super.getItemOffsets(outRe ...
- QPixmap 在非QtCreator环境下无法显示jpg图片
这几天需要实现在Qt界面中显示jpg图片,于是直接将路径传给QPixmap对象,发现显示不出来. 然而在Qt SDK自带的Demo中却可以正确显示jpg图片,经搜索引擎查找发现,是自己的exe文件缺少 ...
- ssm注入失败
今天做ssm整合时候,创建bean/注入一直出错,检查几遍没发现问题,后来发现犯了个低级错误,mapper.xml的<mapper namespace="XXXXX" > ...
- LWIP之ARP协议
描述ARP缓存表的数据结构: struct etharp_entry { struct etharp_q_entry *q; //数据包缓冲队列指针 ip_addr_t ipaddr; //目标IP地 ...
- pgadmin连接 postgresql远程设置
背景:通过yum默认方式将pgsql10安装在centos7, pgsql 的配置文件在:/var/lib/pgsql/10/data. 配置文件:postgresql.conf 和 pg_hba.c ...
- 系统设计与架构笔记:ETL工具开发和设计的建议
最近项目组里想做一个ETL数据抽取工具,这是一个研发项目,但是感觉公司并不是特别重视,不重视不是代表它不重要,而是可能不会对这个项目要求太高,能满足我们公司的小需求就行,想从这个项目里衍生出更多的东西 ...
- part2
一. 列表.元组操作 切片:取多个元素 #!/usr/bin/env python # _*_ coding:utf-8 _*_ #切片:取多个元素 names = ['cai','xiao','lo ...
- asp.net core结合docker实现自动化获取源码、部署、更新
之前入坑dotnet core,由于一开始就遇到在windows上编译发布的web无法直接放到centos上执行.之后便直接研究docker,实现在容器中编译发布.然后就越玩越大,后来利用git的ho ...