ElasticSearch集群环境搭建
一 、单机部署
1、下载安装包、解压
2、在window下运行bin/elasticsearch.bat
3、访问localhost:9200
页面显示结果
{
"name" : "d1pb6pN",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "_DZ1xCBoR-a3tFj9O_qZHg",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
启动
本地部署后,非本机网络访问不到。
出现问题
max virtual memory areas vm.max_map_count [65530] is too low
解决方法
切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
二 、集群部署
三、重要概念
一个集群(cluster)是一个或多个服务器节点的集合,用于存储全部的数据。
四、常用API
数据访问模式
<REST Verb> /<Index>/<Type>/<ID>
1、集群健康检查

2、查看节点列表
3、查看索引

pri:分片
rep:副本
4、创建索引
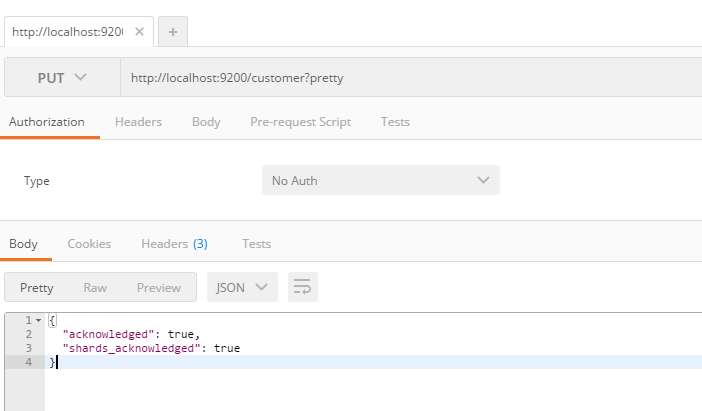
5、给一个文档创建索引
put http://localhost:9200/customer/external/1?pretty
{
"name": "John Doe"
}
得到的响应
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
ElasticSearch集群环境搭建的更多相关文章
- ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决 说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章. 所以,我想把我知道的分享给大家,方便大家交流. 以下是本文的大纲: 1. 在windows7 下面安装虚拟机2 ...
随机推荐
- python3--迭代
判断一个对象是否能够进行迭代的方法 Iterable from collections import Iterable dict = {'name':'Joe','age':17} print (is ...
- js基础知识:字面量 关键字和保留字
js中的字面量概念我的理解就是:字体表面的常量 如:数字 100, 字符串 "ssss"或'ssss' 布尔值:false ,正则 以及null对象. 这些都是常量. 关键字: ...
- java面试一、1.3线程与进程
免责声明: 本文内容多来自网络文章,转载为个人收藏,分享知识,如有侵权,请联系博主进行删除. 1.3.进程和线程 线程和进程的概念.并行和并发的概念 线程和进程: 线程:是程序执行流的最小单元 ...
- UE4物理动画使用
Rigid Body Body的创建. 对重要骨骼创建Body,保证Body控制的是表现和变化比较大的骨骼. 需要对Root创建Body并绑定,设置为Kinematic且不启用物理.原因是UPrimi ...
- 记录一下msf的学习使用
刚刚用Metasploit Pro scan了一下云端服务器.RHOST直接输IP就好. 得到反馈如下: [*] [2019.04.04-14:27:35] Scan initiated: Speed ...
- Oracle EBS数据定义移植工具:Xdf(XML Object Description File)
转载自:http://www.orapub.cn/posts/3296.html Oracle EBS二次开发中,往往会创建很多数据库对象,如表.同义词.视图等,这些数据库对象是二次开发配置管理内容很 ...
- Vipe-技术选型
1.AOP,IOC框架-Spring 选择Spring是最不需要考虑的.应该90%以上的JAVA项目都有用Spring. 2.ORM框架-Mybatis Mybatis入门比较简单,并且对SQL语法的 ...
- Windows 10 IoT Core 17133 for Insider 版本更新
今天,微软发布了Windows 10 IoT Core 17133 for Insider 版本更新,本次更新只修正了一些Bug,没有发布新的特性.用户可以登录Windows Device Porta ...
- 爱上python之盲注探测脚本
本文转自:i春秋论坛 前言: 最近在学python,做了个盲注的简单的跑用户的脚本,仅做个记录. sqmap也有不灵的时候,有时需要根据情况自写脚本探测 正文: 本地用大表姐给的sql和p ...
- 阿里巴巴Java开发规约及插件安装
[上海尚学堂编辑整理]10.14日,阿里巴巴在杭州云栖大会上,正式发布了由阿里巴巴 P3C 项目组,经过 近一年的持续研发,正式发布众所期待的 <阿里巴巴 Java 开发规约>的扫描插件. ...