ElasticSearch集群环境搭建
一 、单机部署
1、下载安装包、解压
2、在window下运行bin/elasticsearch.bat
3、访问localhost:9200
页面显示结果
{
"name" : "d1pb6pN",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "_DZ1xCBoR-a3tFj9O_qZHg",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
启动
本地部署后,非本机网络访问不到。
出现问题
max virtual memory areas vm.max_map_count [65530] is too low
解决方法
切换到root用户修改配置sysctl.conf
vi /etc/sysctl.conf
添加下面配置:
vm.max_map_count=655360
并执行命令:
sysctl -p
二 、集群部署
三、重要概念
一个集群(cluster)是一个或多个服务器节点的集合,用于存储全部的数据。
四、常用API
数据访问模式
<REST Verb> /<Index>/<Type>/<ID>
1、集群健康检查

2、查看节点列表
3、查看索引

pri:分片
rep:副本
4、创建索引
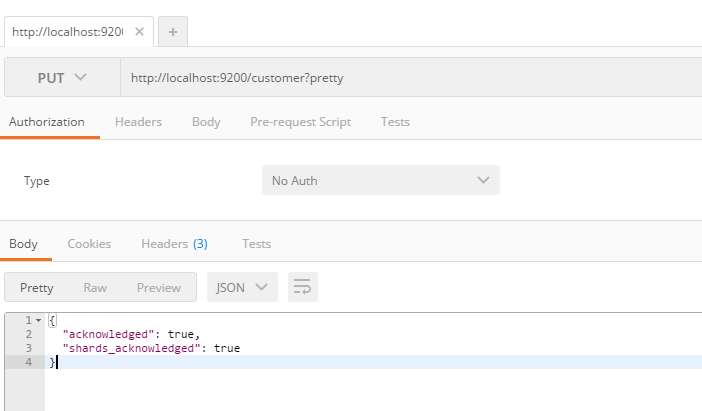
5、给一个文档创建索引
put http://localhost:9200/customer/external/1?pretty
{
"name": "John Doe"
}
得到的响应
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"created" : true
}
ElasticSearch集群环境搭建的更多相关文章
- ElasticSearch 集群环境搭建,安装ElasticSearch-head插件,安装错误解决
ElasticSearch-5.3.1集群环境搭建,安装ElasticSearch-head插件,安装错误解决 说起来甚是惭愧,博主在写这篇文章的时候,还没有系统性的学习一下ES,只知道可以拿来做全文 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 项目进阶 之 集群环境搭建(三)多管理节点MySQL集群
上次的博文项目进阶 之 集群环境搭建(二)MySQL集群中,我们搭建了一个基础的MySQL集群,这篇博客咱们继续讲解MySQL集群的相关内容,同时针对上一篇遗留的问题提出一个解决方案. 1.单管理节点 ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- hadoop2集群环境搭建
在查询了很多资料以后,发现国内外没有一篇关于hadoop2集群环境搭建的详细步骤的文章. 所以,我想把我知道的分享给大家,方便大家交流. 以下是本文的大纲: 1. 在windows7 下面安装虚拟机2 ...
随机推荐
- cobbler实现系统自动化安装centos
cobbler [epel] cobbler服务集成 PXE DHCP rsync Http DNS Kickstart IPMI[电源管理] 1.软件安装 yum install cobbler d ...
- python_flask 基础巩固(自定义URL转换器)
自定义URL转换器(在BaseConverter类外定义)from werkzeug.routing import BaseConverter定义类继承BaseConverter 实现类app.url ...
- 【ProtoBuffer】windows上安装ProtoBuffer3.1.0 (附已编译资源)
------- 17.9.17更新 --- 以下这些方法都是扯淡,对我的机器不适用,我后来花了最后成功安装并亲测可用的方法不是靠vs编过的,vs生成的库引入后函数全部报undefine refere ...
- 基于coridc算法的定点小数除法器的实现
`timescale 1ns / 1ps /////////////////////////////////////////////////////////////////////////////// ...
- day_7数据类型的相互转换,与字符编码
首先复一下昨天的内容 1:深浅拷贝 1:值拷贝 直接赋值 列表1=列表2 列表1中的任何值发生改变,列表2中的值都会随之改变 2:浅拷贝,列表2=列表1 列表1中存放的值的地址没有改变, ...
- Java并发编程:Lock(锁)
一.synchronized的缺陷 synchronized是java中的一个关键字,也就是说是Java语言内置的特性.那么为什么会出现Lock呢? 在上面一篇文章中,我们了解到如果一个代码块被syn ...
- Redis-09.慢查询
慢查询指的是redis命令的执行时间,不包括网络传输和排队时间. Redis配置文件redis.conf中描述慢查询相关的选项在SLOW LOG部分 ######################### ...
- js前段开发工具
http://runjs.cn/?token=e87dac453af5caed08d1771682b0c3f5
- vs链接错误解决方法
常见引起链接错误的主要原因是由于项目不能找到所需的动态库的路径: 这里介绍一下引用第三方动态库的配置方法: 方法一: vs加载动态库需要先把动态库拷贝到exe所在文件夹,再修改项目属性: 链接器-&g ...
- ECShop全系列版本远程代码执行高危漏洞分析+实战提权
漏洞概述 ECShop的user.php文件中的display函数的模版变量可控,导致注入,配合注入可达到远程代码执行.攻击者无需登录站点等操作,可以直接远程写入webshell,危害严重. 漏洞评级 ...