快速排序的c++实现 和 python 实现
最近在学python,其中有个要求实现快速排序的练习,就顺便复习了c++的快速排序实现。
快速排序的基本思想是,通过一轮的排序将序列分割成独立的两部分,其中一部分序列的关键字(这里主要用值来表示)均比另一部分关键字小。继续对长度较短的序列进行同样的分割,最后到达整体有序。在排序过程中,由于已经分开的两部分的元素不需要进行比较,故减少了比较次数,降低了排序时间。
详细描述:首先在要排序的序列 a 中选取一个中轴值,而后将序列分成两个部分,其中左边的部分 b 中的元素均小于或者等于 中轴值,右边的部分 c 的元素 均大于或者等于中轴值,而后通过递归调用快速排序的过程分别对两个部分进行排序,最后将两部分产生的结果合并即可得到最后的排序序列。
“基准值”的选择有很多种方法。最简单的是使用第一个记录的关键字值。但是如果输入的数组是正序或者逆序的,就会将所有的记录分到“基准值”的一边。较好的方法是随机选取“基准值”,这样可以减少原始输入对排序造成的影响。但是随机选取“基准值”的开销大。
为了实现一次划分,我们可以从数组(假定数据是存在数组中)的两端移动下标,必要时交换记录,直到数组两端的下标相遇为止。为此,我们附设两个指针(下角标)i 和 j, 通过 j 从当前序列的有段向左扫描,越过不小于基准值的记录。当遇到小于基准值的记录时,扫描停止。通过 i 从当前序列的左端向右扫描,越过小于基准值的记录。当遇到不小于基准值的记录时,扫描停止。交换两个方向扫描停止的记录 a[j] 与 a[i]。 然后,继续扫描,直至 i 与 j 相遇为止。扫描和交换的过程结束。这是 i 左边的记录的关键字值都小于基准值,右边的记录的关键字值都不小于基准值。
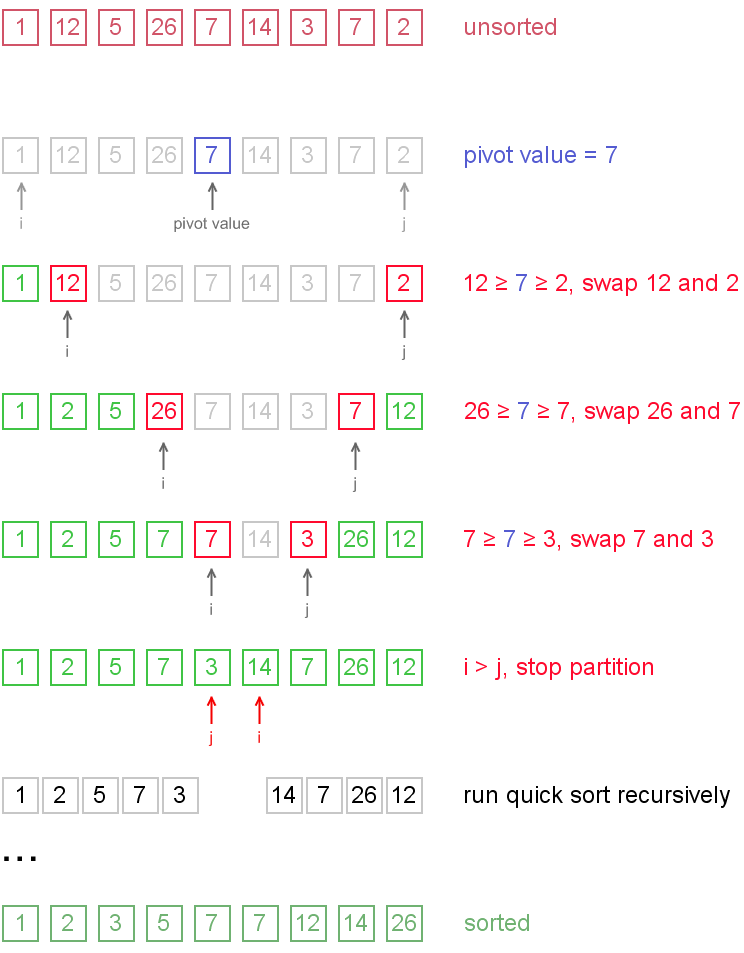
下面是实现代码和测试代码,使用了c++的模板函数,只有有实现operator <的类都可以排序:
实现一:
//快速排序练习c++实现
//author:sixbeauty #include<iostream>
#include<vector>
#include<string> template<typename T>
void swapData(std::vector<T> &p,int i,int j) //交换向量中两个位置的值
{
T data=p[i];
p[i]=p[j];
p[j]=data;
} template<typename T>
void quickSort(std::vector<T> &p,int left,int right) //快速排序实现函数
{
if(left>=right) return ; //若右标志为小于或等于左标志位,则不作任何事 int center=(left+right)/2; //取中间数为key值
int i=left,j=right; //左、右游标定义 while(1)
{
while(p[i]<p[center])
i++; //左游标移到第一个小于key值的位置
while(p[j]>p[center]) //右游标的移动
j--; if(i==j) break; //i==j时,左、右游标i,j同时移动到key值的位置,排序完成 else if(i==center)
{
center=j; //若左游标移动到key的位置而右游标未移动,交换i、j的值后,center也要改变
} else if(j==center)
{
center=i;
} swapData(p,i,j);
} quickSort(p,left,center-1);
quickSort(p,center+1,right);
} int main()
{
//测试代码
/*int p1[8]={1,4,5,7,11,2,18,9};
std::vector<int> vetInt;
for(int i=0;i<8;i++)
vetInt.push_back(p1[i]); quickSort<int>(vetInt,0,7); for(std::vector<int>::iterator itr=vetInt.begin();itr!=vetInt.end();itr++)
std::cout<<*itr<<",";
std::cout<<std::endl;*/ //测试代码
std::string p1[8]={"ba","a","abd","defef","c","ca","daaa","aaa"};
std::vector<std::string> vetStr;
for(int i=0;i<8;i++)
vetStr.push_back(p1[i]); quickSort<std::string>(vetStr,0,7); for(std::vector<std::string>::iterator itr=vetStr.begin();itr!=vetStr.end();itr++)
std::cout<<*itr<<",";
std::cout<<std::endl;
}
实现二:
上面的实现是我按照以前教材上的逻辑做出来的,由于这个实现用了swap,多次的数值交换降低了效率,存在提升的空间,后来在网上看到一个更高效的版本,它选取数组第一位为key值。
举例说明一下吧,这个可能不是太好理解。假设要排序的序列为
2 2 4 9 3 6 7 1 5 首先用2当作基准,使用i j两个指针分别从两边进行扫描,把比2小的元素和比2大的元素分开。首先比较2和5,5比2大,j左移
2 2 4 9 3 6 7 1 5 比较2和1,1小于2,所以把1放在2的位置
2 1 4 9 3 6 7 1 5 比较2和4,4大于2,因此将4移动到后面
2 1 4 9 3 6 7 4 5 比较2和7,2和6,2和3,2和9,全部大于2,满足条件,因此不变
经过第一轮的快速排序,元素变为下面的样子
[1] 2 [4 9 3 6 7 5]
实现代码如下:
template<typename T>
void quickSort(std::vector<T> &p,int left,int right) //快速排序实现函数
{
if(left>=right) return ; //若右标志为小于或等于左标志位,则不作任何事 T keyData=p[left]; //选取第一位为key值
int i=left,j=right; //左、右游标定义 while(i<j)
{
while(i<j && p[j]>keyData) //第一次进入循环,i=left,所以p[i]的值等于keyData,后面我们要保证p[i]=keyData
j--; //右游标移动到第一个小于key值的位置,i<j保证不出界,防止下面的赋值出错 p[i]=p[j]; //这时p[j]的值等于keyData,但我们不马上赋值 while(i<j && p[i]<keyData)
i++; p[j]=p[i]; //经过这一轮后,p[i]的值又重新等于keyData
} //跳出循环后,在i以前的值都小于keyData,在i以后的值都大于keyData,这时只要把keyData赋值给p[i]即可
p[i]=keyData;
if(left<i) //这里必须加这个,不然在left是最小值的情况是死循环
quickSort(p,left,i-1);
quickSort(p,i+1,right);
}
测试代码用上面的即可;
实现三(python实现):
python没有类模板,而且里面的所谓函数重载根本不能算重载嘛,整就一个c++里面的缺省参数(就多了个利用参数关键字赋值),不过python实现起来真的快很多,就忍了。
下面是实现代码:
#FileName: quckSort.py
#author: sixbeauty def quickSort(p,left,right):
if(left>=right):
return
keyData=p[left]
i=left
j=right while i<j:
while (i<j and p[j]>keyData):
j-=1 p[i]=p[j] while (i<j and p[i]<keyData):
i+=1 p[j]=p[i] p[i]=keyData if(i>left):
quickSort(p,left,i-1)
quickSort(p,i+1,right) p=[8,4,5,7,11,2,9,19]
quickSort(p,0,7)
print(p)
下次讨论python实现的压缩备份程序,python的实现比c++快多了,就算封装成类还是要方便多=_=
快速排序的c++实现 和 python 实现的更多相关文章
- $用python实现快速排序算法
本文主要介绍用python实现基本的快速排序算法,体会一下python的快排代码可以写得多么简洁. 1. 三言两语概括算法核心思想 先从待排序的数组中找出一个数作为基准数(取第一个数即可),然后将原来 ...
- s11d27 算法
s11d27 算法 一.理论 1.1 时间复杂度和空间复杂度的理论: 1)空间复杂度: 是程序运行所以需要的额外消耗存储空间,一般的递归算法就要有o(n)的空间复杂度了, 简单说就是递归集算时通常是反 ...
- 快速排序(python实现)
算法导论上的快速排序采用分治算法,步骤如下: 1.选取一个数字作为基准,可选取末位数字 2.将数列第一位开始,依次与此数字比较,如果小于此数,将小数交换到左边,最后达到小于基准数的在左边,大于基准数的 ...
- python 实现冒泡排序与快速排序 遇到的错误与问题
今天看了兄弟连php里面的冒泡排序与快速排序,想了下应该可以用python实现. 冒泡排序函数: def mysort(x): len1 = len(x) for i in range(len1-1, ...
- 你需要知道的九大排序算法【Python实现】之快速排序
五.快速排序 基本思想: 通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分关键字小,则分别对这两部分继续进行排序,直到整个序列有序. 算法实现: #coding: ...
- 快速排序算法回顾 --冒泡排序Bubble Sort和快速排序Quick Sort(Python实现)
冒泡排序的过程是首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序,则将两个记录交换,然后比较第二个记录和第三个记录的关键字.以此类推,直至第n-1个记录和第n个记录的关键字进行过比较为止 ...
- JavaScript、Python、java、Go算法系列之【快速排序】篇
常见的内部排序算法有:插入排序.希尔排序.选择排序.冒泡排序.归并排序.快速排序.堆排序.基数排序等. 用一张图概括: 选择排序 选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的 ...
- Python之排序算法:快速排序与冒泡排序
Python之排序算法:快速排序与冒泡排序 转载请注明源地址:http://www.cnblogs.com/funnyzpc/p/7828610.html 入坑(简称IT)这一行也有些年头了,但自老师 ...
- python实现快速排序
最近在公司的工作内容发生变化,短期内工作量变少了,这也让我有时间整理一些日常学习和工作中的收获或思路.所以申请了博客,并打算持续更新. 快速排序采用了分治的思想,基本思想是选取数组中一个数为基准数(一 ...
随机推荐
- linux中backticks反引号的作用
This is a backtick. A backtick is not a quotation sign. It has a very special meaning. Everything yo ...
- 在 TDA 工具里看到 Java Thread State 的第一反应是
转载:http://itindex.net/detail/43158-tda-%E5%B7%A5%E5%85%B7-java 使用 TDA 工具,看到大量 Java Thread State 的第 ...
- sublime text 2中“ctrl + `”快捷键无效
之前sublime 使用正常,这次在装插件的时候,发现ctrl + `快捷键失效了,无法调出控制台. 然后就一直按这两个键,肯定是被别的占用了,所以就像看看有啥反应,看了半天都没有见到什么神奇的窗口跳 ...
- webpack+vuecli打包常见的2个坑
第一个坑: 一般情况下,通过webpack+vuecli默认打包的css.js等资源,路径都是绝对的.但当部署到带有文件夹的项目中,这种绝对路径就会出现问题,因为把配置的static文件夹当成了根路径 ...
- WebDriver API——第2部分Exceptions
Exceptions that may happen in all the webdriver code. exception selenium.common.exceptions.ElementNo ...
- OTU_Network&calc_otu
# -*- coding: utf-8 -*- # __author__ = 'JieYap' from biocluster.agent import Agent from biocluster.t ...
- C#实现播放声音的方法
文章来自学IT网:http://www.xueit.com/html/2009-09/21_4598_00.html 在这里介绍使用C#实现播放声音的几种方法,都是利用组件等方法来实现的,有兴趣的话可 ...
- C++之声明与定义的区别
直接举例,在C++中,声明与定义的区别如下: extern int a;//若有extern关键字,则只是声明 int b;//若没有extern关键字,则为声明+定义 int a;//若之前已经声明 ...
- 使用swagger实现在线api文档自动生成 在线测试api接口
使用vs nuget包管理工具搜索Swashbuckle 然后安装便可 注释依赖于vs生成的xml注释文件
- android 屏幕适配原则
屏幕大小 1.不同的layout Android手 机屏幕大小不一,有480x320,640x360,800x480.怎样才能让App自动适应不同的屏幕呢? 其实很简单,只需要在res目录下创建不同的 ...