spark job, stage ,task介绍。
1. spark 如何执行程序?
首先看下spark 的部署图:
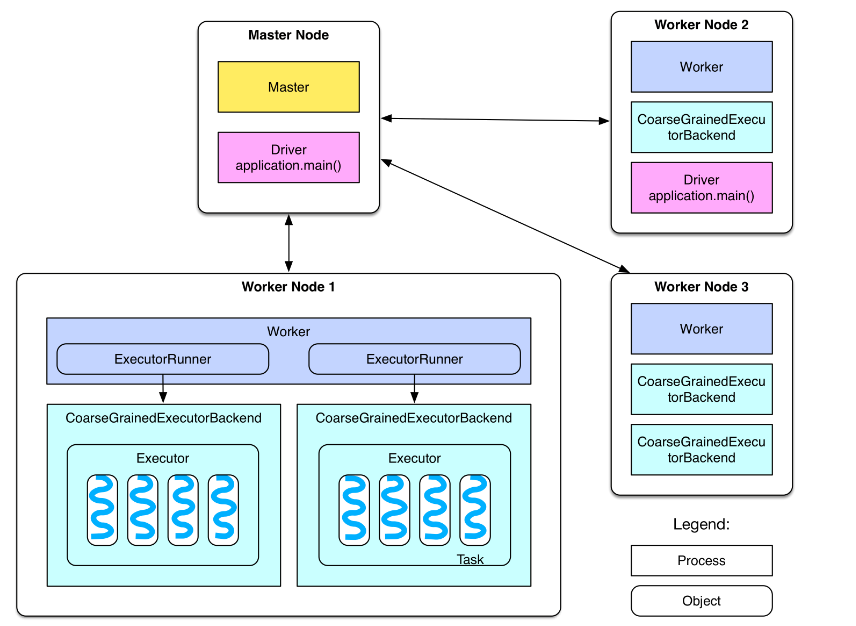
节点类型有:
1. master 节点: 常驻master进程,负责管理全部worker节点。
2. worker 节点: 常驻worker进程,负责管理executor 并与master节点通信。
dirvier:官方解释为: The process running the main() function of the application and creating the SparkContext。即理解为用户自己编写的应用程序
Executor:执行器:
在每个WorkerNode上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上,每个任务都有各自独立的Executor。
Executor是一个执行Task的容器。它的主要职责是:
1、初始化程序要执行的上下文SparkEnv,解决应用程序需要运行时的jar包的依赖,加载类。
2、同时还有一个ExecutorBackend向cluster manager汇报当前的任务状态,这一方面有点类似hadoop的tasktracker和task。
总结:Executor是一个应用程序运行的监控和执行容器。Executor的数目可以在submit时,由 --num-executors (on yarn)指定.
Job:
包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage和Task。
Stage:
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。
Stage的划分在RDD的论文中有详细的介绍,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage。
Task
即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据.
每个executor执行的task的数目, 可以由submit时,--num-executors(on yarn) 来指定。
spark job, stage ,task介绍。的更多相关文章
- 【Spark】Stage生成和Stage源代码浅析
引入 上一篇文章<DAGScheduler源代码浅析>中,介绍了handleJobSubmitted函数,它作为生成finalStage的重要函数存在.这一篇文章中,我将就DAGSched ...
- spark教程(13)-shuffle介绍
shuffle 简介 shuffle 描述了数据从 map task 输出到 reduce task 输入的过程,shuffle 是连接 map 和 reduce 的桥梁: shuffle 性能的高低 ...
- 【原】Spark中Stage的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Job如何划分为Stage http://www.cnblogs.com/yourarebest/p/5342424.html 1 ...
- spark 笔记 9: Task/TaskContext
DAGScheduler最终创建了task set,并提交给了taskScheduler.那先得看看task是怎么定义和执行的. Task是execution执行的一个单元. Task: execut ...
- Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
Spark分区数.task数目.core数目.worker节点数目.executor数目梳理 spark隐式创建由操作组成的逻辑上的有向无环图.驱动器执行时,它会把这个逻辑图转换为物理执行计划,然后将 ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
- spark 笔记 15: ShuffleManager,shuffle map两端的stage/task的桥梁
无论是Hadoop还是spark,shuffle操作都是决定其性能的重要因素.在不能减少shuffle的情况下,使用一个好的shuffle管理器也是优化性能的重要手段. ShuffleManager的 ...
随机推荐
- 测试家庭流媒体服务器Windows7
测试首先选择了Darwin Streaming Server (DSS) for Windows 下载地址:http://dss.macosforge.org/downloads/DarwinStre ...
- ANSYS经典APDL编程
在使用ANSYS的过程中的一些经验总结: Ansys Workbench 有限元分析虽然进入UI阶段,但是语言命令仍然是其基础核心. 1.ANSYS中的一些关键概念的理解; 参数化程序设计语言(APD ...
- js中使用进行字符串传参
在js中拼接html标签传参时,如果方法参数是字符串需要加上引号,这里需要进行字符转义 <a href='javascript:addMenuUI("+"\"&qu ...
- Git Pro - (1) 基础
近乎所有操作都可本地执行 在Git中的绝大多数操作都只需要访问本地文件和资源,不用连网. 三种状态 对于任何一个文件,在 Git 内都只有三 种状态:已提交(committed),已修改(modifi ...
- Delegate, Method as Parameter.
代理, 将方法作为另一方法的参数. 类似C里面的函数指针. using System; using System.Windows.Forms; using System.Threading; name ...
- 7、IMS - DNS & ENUM
1.相关基础SBC:http://blog.sina.com.cn/s/blog_7a6f76080100vp9r.html 2.ENUM/DNS查询过程:http://blog.sina.com.c ...
- NOIP2008 传纸条
题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题.一次素质拓展活动中,班上同学安排做成一个m行n列的矩阵,而小渊和小轩被安排在矩阵对角线的两端,因此,他们就无法直接交谈了.幸运的是 ...
- 2015.05.14:codesmith
安装: 安装好codesmith会有两个软件:一个编译器(CodeSmith Generator Explorer),一个生成工具(CodeSmith Generator Studio) 破解: 一般 ...
- MVC执行过程
HttpRuntime中的PR方法1,封装HttpContext2,获取HttpApplication 主要做3件事a,执行本事件时主要调用Init将Global编译得到类型,b,确保Appstart ...
- ajax options
非同一域名的ajax post请求,浏览器会自动发送http options的请求检查是否允许跨域访问