kmeans算法c语言实现,能对不同维度的数据进行聚类
最近在苦于思考kmeans算法的MPI并行化,花了两天的时间把该算法看懂和实现了串行版。
聚类问题就是给定一个元素集合V,其中每个元素具有d个可观察属性,使用某种算法将V划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。
下面是google到该算法的一个流程图,表意清楚:
1、随机选取数据集中的k个数据点作为初始的聚类中心:
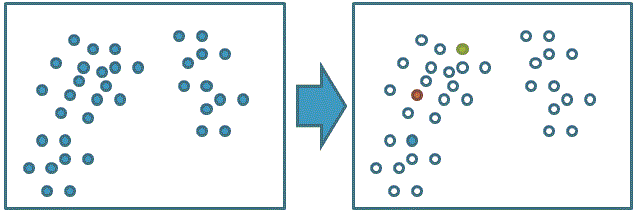
2、分别计算每个数据点到每个中心的距离,选取距离最短的中心点作为其聚类中心:
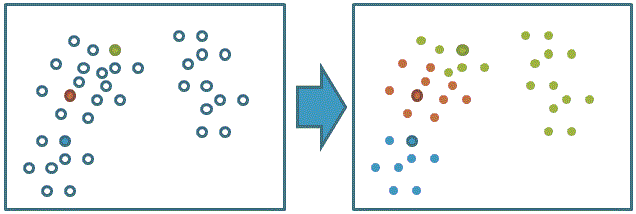
3、利用目前得到的聚类重新计算中心点:
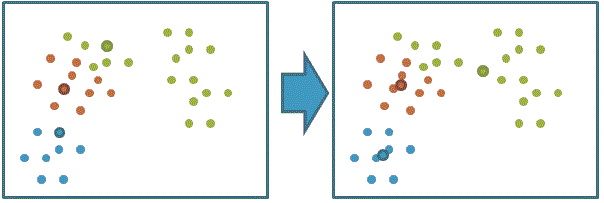
4、重复步骤2和3直到收敛(达到最大迭代次数或聚类中心不再移动):
code:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h> int K,N,D; //聚类的数目,数据量,数据的维数
float **data; //存放数据
int *in_cluster; //标记每个点属于哪个聚类
float **cluster_center; //存放每个聚类的中心点 float **array(int m,int n);
void freearray(float **p);
float **loadData(int *k,int *d,int *n);
float getDistance(float avector[],float bvector[],int n);
void cluster();
float getDifference();
void getCenter(int in_cluster[]); int main()
{
int i,j,count=;
float temp1,temp2;
data=loadData(&K,&D,&N);
printf("Data sets:\n");
for(i=;i<N;i++)
for(j=;j<D;j++){
printf("%-8.2f",data[i][j]);
if((j+)%D==) putchar('\n');
}
printf("-----------------------------\n"); srand((unsigned int)(time(NULL))); //随机初始化k个中心点
for(i=;i<K;i++)
for(j=;j<D;j++)
cluster_center[i][j]=data[(int)((double)N*rand()/(RAND_MAX+1.0))][j]; cluster(); //用随机k个中心点进行聚类
temp1=getDifference(); //第一次中心点和所属数据点的距离之和
count++;
printf("The difference between data and center is: %.2f\n\n", temp1); getCenter(in_cluster);
cluster(); //用新的k个中心点进行第二次聚类
temp2=getDifference();
count++;
printf("The difference between data and center is: %.2f\n\n",temp2); while(fabs(temp2-temp1)!=){ //比较前后两次迭代,若不相等继续迭代
temp1=temp2;
getCenter(in_cluster);
cluster();
temp2=getDifference();
count++;
printf("The %dth difference between data and center is: %.2f\n\n",count,temp2);
} printf("\nThe total number of cluster is: %d\n",count); //统计迭代次数
//system("pause"); //gcc编译需删除
return ;
} //动态创建二维数组
float **array(int m,int n)
{
int i;
float **p;
p=(float **)malloc(m*sizeof(float *));
p[]=(float *)malloc(m*n*sizeof(float));
for(i=;i<m;i++) p[i]=p[i-]+n;
return p;
} //释放二维数组所占用的内存
void freearray(float **p)
{
free(*p);
free(p);
} //从data.txt导入数据,要求首行格式:K=聚类数目,D=数据维度,N=数据量
float **loadData(int *k,int *d,int *n)
{
int i,j;
float **arraydata;
FILE *fp;
if((fp=fopen("data.txt","r"))==NULL) fprintf(stderr,"cannot open data.txt!\n");
if(fscanf(fp,"K=%d,D=%d,N=%d\n",k,d,n)!=) fprintf(stderr,"load error!\n");
arraydata=array(*n,*d); //生成数据数组
cluster_center=array(*k,*d); //聚类的中心点
in_cluster=(int *)malloc(*n * sizeof(int)); //每个数据点所属聚类的标志数组
for(i=;i<*n;i++)
for(j=;j<*d;j++)
fscanf(fp,"%f",&arraydata[i][j]); //读取数据点
return arraydata;
} //计算欧几里得距离
float getDistance(float avector[],float bvector[],int n)
{
int i;
float sum=0.0;
for(i=;i<n;i++)
sum+=pow(avector[i]-bvector[i],);
return sqrt(sum);
} //把N个数据点聚类,标出每个点属于哪个聚类
void cluster()
{
int i,j;
float min;
float **distance=array(N,K); //存放每个数据点到每个中心点的距离
//float distance[N][K]; //也可使用C99变长数组
for(i=;i<N;++i){
min=9999.0;
for(j=;j<K;++j){
distance[i][j] = getDistance(data[i],cluster_center[j],D);
//printf("%f\n", distance[i][j]);
if(distance[i][j]<min){
min=distance[i][j];
in_cluster[i]=j;
}
}
printf("data[%d] in cluster-%d\n",i,in_cluster[i]+);
}
printf("-----------------------------\n");
free(distance);
} //计算所有聚类的中心点与其数据点的距离之和
float getDifference()
{
int i,j;
float sum=0.0;
for(i=;i<K;++i){
for(j=;j<N;++j){
if(i==in_cluster[j])
sum+=getDistance(data[j],cluster_center[i],D);
}
}
return sum;
} //计算每个聚类的中心点
void getCenter(int in_cluster[])
{
float **sum=array(K,D); //存放每个聚类中心点
//float sum[K][D]; //也可使用C99变长数组
int i,j,q,count;
for(i=;i<K;i++)
for(j=;j<D;j++)
sum[i][j]=0.0;
for(i=;i<K;i++){
count=; //统计属于某个聚类内的所有数据点
for(j=;j<N;j++){
if(i==in_cluster[j]){
for(q=;q<D;q++)
sum[i][q]+=data[j][q]; //计算所属聚类的所有数据点的相应维数之和
count++;
}
}
for(q=;q<D;q++)
cluster_center[i][q]=sum[i][q]/count;
}
printf("The new center of cluster is:\n");
for(i = ; i < K; i++)
for(q=;q<D;q++){
printf("%-8.2f",cluster_center[i][q]);
if((q+)%D==) putchar('\n');
}
free(sum);
}
该程序支持不同维度的数据集,一个示例的数据集 data.txt如下:
K=3,D=3,N=15
-25 22.2 35.34
31.2 -14.4 23
32.02 -23 24.44
-25.35 36.3 -33.34
-20.2 27.333 -28.22
-15.66 17.33 -23.33
26.3 -31.34 16.3
-22.544 16.2 -32.22
12.2 -15.22 22.11
-41.241 25.232 -35.338
-22.22 45.22 23.55
-34.22 50.14 30.98
15.23 -30.11 20.987
-32.5 15.3 -25.22
-38.97 20.11 33.22
kmeans算法c语言实现,能对不同维度的数据进行聚类的更多相关文章
- kmeans算法
# coding:utf-8 import numpy as np import matplotlib.pyplot as plt def dis(x, y): #计算距离 return np.sum ...
- Kmeans算法与KNN算法的区别
最近研究数据挖掘的相关知识,总是搞混一些算法之间的关联,俗话说好记性不如烂笔头,还是记下了以备不时之需. 首先明确一点KNN与Kmeans的算法的区别: 1.KNN算法是分类算法,分类算法肯定是需要有 ...
- k-means算法之见解(一)
k-menas算法之见解 主要内容: 一.引言 二.k-means聚类算法 一.引言: 先说个K-means算法很高大上的用处,来开始新的算法学习.美国竞选总统,选票由公民投出,总统由大家决定.在20 ...
- K-means算法的原理、优缺点及改进(转)
文章内容转载自:http://blog.csdn.net/sinat_35512245/article/details/55051306 ...
- 数学建模及机器学习算法(一):聚类-kmeans(Python及MATLAB实现,包括k值选取与聚类效果评估)
一.聚类的概念 聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好.我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结 ...
- 数据挖掘经典算法——K-means算法
算法描述 K-means算法是一种被广泛使用的基于划分的聚类算法,目的是将n个对象会分成k个簇.算法的具体描述如下: 随机选取k个对象作为簇中心: Do 计算所有对象到这k个簇中心的距离,将距离最近的 ...
- 机器学习实战之K-Means算法
一,引言 先说个K-means算法很高大上的用处,来开始新的算法学习.我们都知道每一届的美国总统大选,那叫一个竞争激烈.可以说,谁拿到了各个州尽可能多的选票,谁选举获胜的几率就会非常大.有人会说,这跟 ...
- 【转】机器学习实战之K-Means算法
一,引言 先说个K-means算法很高大上的用处,来开始新的算法学习.我们都知道每一届的美国总统大选,那叫一个竞争激烈.可以说,谁拿到了各个州尽可能多的选票,谁选举获胜的几率就会非常大.有人会说,这跟 ...
- RFM模型的变形LRFMC模型与K-means算法的有机结合
应用场景: 可以应用在不同行业的客户分类管理上,比如航空公司,传统的RFM模型不再适用,通过RFM模型的变形LRFMC模型实现客户价值分析:基于消费者数据的精细化营销 应用价值: LRFMC模型构建之 ...
随机推荐
- Lucene.net初探
引言 在分析同事开发的客户端搜索项目时注意到,搜索的关键是索引,而提到索引就不得不提Lucene.net,思路就是将需要搜索内容写入索引,客户端自己或局域网其他机器搜索时直接搜索索引,从而查看到你共享 ...
- VC++6.0文件关联问题的解决方法
最近我的电脑*.c文件关联失败,无法实现双击*.c打开vc++6.0,感觉特别不爽. 在经过自己的琢磨研究后,终于找到了解决方法. 特此分享下,希望可以帮到遇到同样问题的你. 核心内容: 1.& ...
- 《C#并发编程经典实例》笔记
1.前言 2.开宗明义 3.开发原则和要点 (1)并发编程概述 (2)异步编程基础 (3)并行开发的基础 (4)测试技巧 (5)集合 (6)函数式OOP (7)同步 1.前言 最近趁着项目的一段平稳期 ...
- 浅谈 C#委托
看了<CLR via C#>的17章委托后,为自己做一点浅显的总结,也分享给需要的人. .NET通过委托来提供一种回调函数机制,.NET委托提供了很多功能,例如确保回调方法是类型安全的(C ...
- 未能解析此远程名称: 'api.ucpaas.com'
未能解析此远程名称: 'api.ucpaas.com' 这个问题的原因不是云之讯,而是(我用的是阿里云)云服务器的DNS解析的问题 或者是云服务器后台的安全组规则的问题, 应该把内网入方向和内网出 ...
- MySQL 5.7 create VIEW or FUNCTION or PROCEDURE
1.视图 a. CREATE ALGORITHM = UNDEFINED DEFINER = `root`@`localhost` SQL SECURITY INVOKER VIEW `sakila` ...
- input输入框提示语
<input id="username" name="username" type="text" placeholder=" ...
- iPhone开发与cocos2d 经验谈
转CSDN jilongliang : 首先,对于一个完全没有mac开发经验,甚至从没摸过苹果系统的开发人员来说,首先就是要熟悉apple的那一套开发框架(含开发环境IDE.开发框架uikit,还有开 ...
- java web学习总结(十八) -------------------过滤器的高级使用
在filter中可以得到代表用户请求和响应的request.response对象,因此在编程中可以使用Decorator(装饰器)模式对request.response对象进行包装,再把包装对象传给目 ...
- input输入框限制仅能输入数字且规定数字长度(使用与输入手机号)
现在越来越多的账户名使用手机号来登录,为了减少前后端的交互,需要用户在输入时就要进行格式的判断, 目前的常规办法是,在输入完成后进行判断. 下面的方法是在输入时就规定只能输入数字,其他格式的字符是无法 ...