CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep
背景
这一篇我们从基础的深度ctr模型谈起。我很喜欢Wide&Deep的框架感觉之后很多改进都可以纳入这个框架中。Wide负责样本中出现的频繁项挖掘,Deep负责样本中未出现的特征泛化。而后续的改进要么用不同的IFC让Deep更有效的提取特征交互信息,要么是让Wide更好的记忆样本信息
以下代码针对Dense输入感觉更容易理解模型结构,其他针对spare输入的模型和完整代码
https://github.com/DSXiangLi/CTR
Embedding + MLP
点击率模型最初在深度学习上的尝试是从简单的MLP开始的。把高维稀疏的离散特征做Embedding处理,然后把Embedding拼接作为MLP的输入,经过多层全联接神经网络的非线性变换得到对点击率的预测。
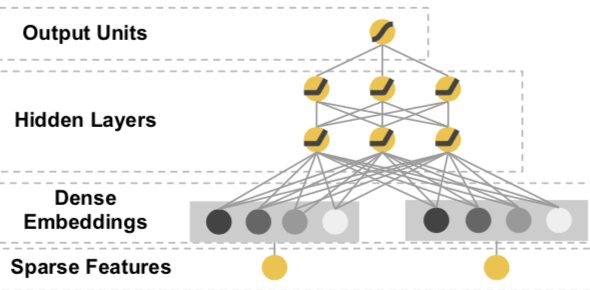
不知道你是否也像我一样困惑过,这个Embedding+MLP究竟学到了什么信息?MLP的Embedding和FM的Embedding学到的是同样的特征交互信息么?最近从大神那里听到一个蛮有说服力的观点,当然keep skeptical,欢迎一起讨论~
mlp可以学到所有特征低阶和高阶的信息表达,但依赖庞大的搜索空间。在样本有限,参数也有限的情况下往往只能学到有限的信息。因此才依赖于基于业务理解的特征工程来帮助mlp在有限的空间下学到更多有效的特征交互信息。FM的向量内积只是二阶特征工程的一种方法。之后针对deep的很多改进也是在探索如何把特征工程的业务经验用于更好的提取特征交互信息
代码实现
def build_features(numeric_handle):
f_sparse = []
f_dense = []
for col, config in EMB_CONFIGS.items():
ind = tf.feature_column.categorical_column_with_hash_bucket(col, hash_bucket_size = config['hash_size'])
one_hot = tf.feature_column.indicator_column(ind)
f_sparse.append(one_hot)
# Method1 for numeric feature
if numeric_handle == 'bucketize':
# Method1 'onehot': bucket to one hot
for col, config in BUCKET_CONFIGS.items():
num = tf.feature_column.numeric_column( col )
bucket = tf.feature_column.bucketized_column( num, boundaries=config )
f_sparse.append(bucket)
else :
# Method2 'dense': concatenate with embedding
for col, config in BUCKET_CONFIGS.items():
num = tf.feature_column.numeric_column( col )
f_dense.append(num)
return f_sparse, f_dense
@tf_estimator_model
def model_fn(features, labels, mode, params):
sparse_columns, dense_columns = build_features(params['numeric_handle'])
with tf.variable_scope('EmbeddingInput'):
embedding_input = []
for f_sparse in sparse_columns:
sparse_input = tf.feature_column.input_layer(features, f_sparse)
input_dim = sparse_input.get_shape().as_list()[-1]
init = tf.random_normal(shape = [input_dim, params['embedding_dim']])
weight = tf.get_variable('w_{}'.format(f_sparse.name), dtype = tf.float32, initializer = init)
embedding_input.append( tf.matmul(sparse_input, weight) )
dense = tf.concat(embedding_input, axis=1, name = 'embedding_concat')
# if treat numeric feature as dense feature, then concatenate with embedding. else concatenate wtih sparse input
if params['numeric_handle'] == 'dense':
numeric_input = tf.feature_column.input_layer(features, dense_columns)
numeric_input = tf.layers.batch_normalization(numeric_input, center = True, scale = True, trainable =True,
training = (mode == tf.estimator.ModeKeys.TRAIN))
dense = tf.concat([dense, numeric_input], axis = 1, name ='numeric_concat')
with tf.variable_scope('MLP'):
for i, unit in enumerate(params['hidden_units']):
dense = tf.layers.dense(dense, units = unit, activation = 'relu', name = 'Dense_{}'.format(i))
if mode == tf.estimator.ModeKeys.TRAIN:
dense = tf.layers.dropout(dense, rate = params['dropout_rate'], training = (mode==tf.estimator.ModeKeys.TRAIN))
with tf.variable_scope('output'):
y = tf.layers.dense(dense, units=1, name = 'output')
return y
Wide&Deep
Wide&Deep是在上述MLP的基础上加入了Wide部分。作者认为Deep的部分负责generalization既样本中未出现模式的泛化和模糊查询,就是上面的Embedding+MLP。wide负责memorization既样本中已有模式的记忆,是对离散特征和特征组合做Logistics Regression。Deep和Wide一起进行联合训练。
这样说可能不完全准确,作者在文中也提到wide部分只是用来锦上添花,来帮助Deep增加那些在样本中频繁出现的模式在预测目标上的区分度。所以wide不需要是一个full-size模型,而更多需要业务上判断比较核心的特征和交叉特征。

连续特征的处理
ctr模型大多是在探讨稀疏离散特征的处理,那连续特征应该怎么处理呢?有几种处理方式
- 连续特征离散化处理,之后可以做embedding/onehot/cross
- 连续特征不做处理,直接和其他离散特征embedding后的vector拼接作为输入。这里要考虑对连续特征进行归一化处理, 不然会收敛的很慢。上面MLP尝试了BatchNorm,Wide&Deep则直接在feature_column里面做了归一化。
- 既作为连续特征输入,同时也做离散化和其他离散特征进行交互
连续特征离散化的优缺点
缺点
- 信息丢失,丢失多少信息要看桶分的咋样
- 平滑度下降,处于分桶边界的特征变动可能带来预测值比较大的波动
优点
- 加入非线性,多数情况下连续特征和目标之间都不是线性关系,而是在到达某个阈值对用户存在0/1的影响
- 更稳健,可有效避免连续特征中的极值/长尾问题
- 特征交互,做离散特征处理后方便进一步做cross特征
- 省事...,不需要再考虑啥正不正态要不要做归一化之类的
代码实现
def znorm(mean, std):
def znorm_helper(col):
return (col-mean)/std
return znorm_helper
def build_features():
f_onehot = []
f_embedding = []
f_numeric = []
# categorical features
for col, config in EMB_CONFIGS.items():
ind = tf.feature_column.categorical_column_with_hash_bucket(col, hash_bucket_size = config['hash_size'])
f_onehot.append( tf.feature_column.indicator_column(ind))
f_embedding.append( tf.feature_column.embedding_column(ind, dimension = config['emb_size']) )
# numeric features: both in numeric feature and bucketized to discrete feature
for col, config in BUCKET_CONFIGS.items():
num = tf.feature_column.numeric_column(col,
normalizer_fn = znorm(NORM_CONFIGS[col]['mean'],NORM_CONFIGS[col]['std'] ))
f_numeric.append(num)
bucket = tf.feature_column.bucketized_column( num, boundaries=config )
f_onehot.append(bucket)
# crossed features
for col1,col2 in combinations(f_onehot,2):
# if col is indicator of hashed bucuket, use raw feature directly
if col1.parents[0].name in EMB_CONFIGS.keys():
col1 = col1.parents[0].name
if col2.parents[0].name in EMB_CONFIGS.keys():
col2 = col2.parents[0].name
crossed = tf.feature_column.crossed_column([col1, col2], hash_bucket_size = 20)
f_onehot.append(tf.feature_column.indicator_column(crossed))
f_dense = f_embedding + f_numeric #f_dense = f_embedding + f_numeric + f_onehot
f_sparse = f_onehot #f_sparse = f_onehot + f_numeric
return f_sparse, f_dense
def build_estimator(model_dir):
sparse_feature, dense_feature= build_features()
run_config = tf.estimator.RunConfig(
save_summary_steps=50,
log_step_count_steps=50,
keep_checkpoint_max = 3,
save_checkpoints_steps =50
)
dnn_optimizer = tf.train.ProximalAdagradOptimizer(
learning_rate= 0.001,
l1_regularization_strength=0.001,
l2_regularization_strength=0.001
)
estimator = tf.estimator.DNNLinearCombinedClassifier(
model_dir=model_dir,
linear_feature_columns=sparse_feature,
dnn_feature_columns=dense_feature,
dnn_optimizer = dnn_optimizer,
dnn_dropout = 0.1,
batch_norm = False,
dnn_hidden_units = [48,32,16],
config=run_config )
return estimator
CTR学习笔记&代码实现系列
https://github.com/DSXiangLi/CTR
参考材料
- Weinan Zhang, Tianming Du, and Jun Wang. Deep learning over multi-field categorical data - - A case study on user response prediction. In ECIR, 2016.
- Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. ACM, 2016: 7-10
- https://www.jiqizhixin.com/articles/2018-07-16-17
- https://cloud.tencent.com/developer/article/1063010
- https://github.com/shenweichen/DeepCTR
CTR学习笔记&代码实现2-深度ctr模型 MLP->Wide&Deep的更多相关文章
- CTR学习笔记&代码实现3-深度ctr模型 FNN->PNN->DeepFM
这一节我们总结FM三兄弟FNN/PNN/DeepFM,由远及近,从最初把FM得到的隐向量和权重作为神经网络输入的FNN,到把向量内/外积从预训练直接迁移到神经网络中的PNN,再到参考wide& ...
- CTR学习笔记&代码实现5-深度ctr模型 DeepCrossing -> DCN
之前总结了PNN,NFM,AFM这类两两向量乘积的方式,这一节我们换新的思路来看特征交互.DeepCrossing是最早在CTR模型中使用ResNet的前辈,DCN在ResNet上进一步创新,为高阶特 ...
- CTR学习笔记&代码实现4-深度ctr模型 NFM/AFM
这一节我们总结FM另外两个远亲NFM,AFM.NFM和AFM都是针对Wide&Deep 中Deep部分的改造.上一章PNN用到了向量内积外积来提取特征交互信息,总共向量乘积就这几种,这不NFM ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- CTR学习笔记&代码实现1-深度学习的前奏LR->FFM
CTR学习笔记系列的第一篇,总结在深度模型称王之前经典LR,FM, FFM模型,这些经典模型后续也作为组件用于各个深度模型.模型分别用自定义Keras Layer和estimator来实现,哈哈一个是 ...
- GIS案例学习笔记-明暗等高线提取地理模型构建
GIS案例学习笔记-明暗等高线提取地理模型构建 联系方式:谢老师,135-4855-4328,xiexiaokui#qq.com 目的:针对数字高程模型,通过地形分析,建立明暗等高线提取模型,生成具有 ...
- 【PyTorch深度学习】学习笔记之PyTorch与深度学习
第1章 PyTorch与深度学习 深度学习的应用 接近人类水平的图像分类 接近人类水平的语音识别 机器翻译 自动驾驶汽车 Siri.Google语音和Alexa在最近几年更加准确 日本农民的黄瓜智能分 ...
- 深度学习笔记之关于总结、展望、参考文献和Deep Learning学习资源(五)
不多说,直接上干货! 十.总结与展望 1)Deep learning总结 深度学习是关于自动学习要建模的数据的潜在(隐含)分布的多层(复杂)表达的算法.换句话来说,深度学习算法自动的提取分类需要的低层 ...
- [原创]java WEB学习笔记44:Filter 简介,模型,创建,工作原理,相关API,过滤器的部署及映射的方式,Demo
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
随机推荐
- 必备技能六、Vue中实现全局方法
现实背景:很多时候我们会在全局调用一些方法. 实现方式两种:官网的实现use方法,然后你也可以用野路子直接在Vue.prototype上面定义. 先说野路子,因为其实野路子就是最根本的实现方式,官方的 ...
- npm项目创建初始过程详解
npm install 就是安装模块,npm run dev 就是执行npm script中的命令.当我们执行npm命令的时候,它到哪里去找,这就要说到每个node项目中都有的核心文件package ...
- 服务器上监控tomcat,如果挂掉则重启
该脚本用于监控tomcat服务器是否可用,如果服务不可用则重启tomcat 略微修改后也可以用于其他服务的监控 monitor.sh 脚本如下 #!/bin/sh # 定义要监控的页面地址 WebUr ...
- 如何从普通程序员晋升为架构师 面向过程编程OP和面向编程OO
引言 计算机科学是一门应用科学,它的知识体系是典型的倒三角结构,所用的基础知识并不多,只是随着应用领域和方向的不同,产生了很多的分支,所以说编程并不是一件很困难的事情,一个高中生经过特定的训练就可以做 ...
- Hadoop集群搭建(一)~虚拟机的创建
Hadoop集群的搭建包括,虚拟机系统的安装:安装JDK,Hadoop:克隆虚拟机:伪分布式的搭建:安装zookeeper:Hive:Hbae:Spark等等: 我将分为多篇文章来记录.这篇文章主要写 ...
- props watch 接口抖动
readType (val) { this.innerReadType = '-' this.$nextTick(() => { this.innerReadType = val }) },
- PLINQ 并行操作Linq
C#并行编程-PLINQ:声明式数据并行 目录 C#并行编程-相关概念 C#并行编程-Parallel C#并行编程-Task C#并行编程-并发集合 C#并行编程-线程同步原语 C#并行编程-P ...
- 作为一位Vue工程师,这些开发技巧你都会吗?
路由参数解耦 一般在组件内使用路由参数,大多数人会这样做: export default { methods: { getParamsId() { return this.$route.params. ...
- Java-方法(新手)
//创建的一个类.public class zy1ri0319 { //公共静态的主方法. public static void main(String[] args){ //调用方法. zy1(); ...
- RabbitMQ消息发布和消费的确认机制
前言 新公司项目使用的消息队列是RabbitMQ,之前其实没有在实际项目上用过RabbitMQ,所以对它的了解都谈不上入门.趁着周末休息的时间也猛补习了一波,写了两个窗体应用,一个消息发布端和消息消费 ...