k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为:
1、收集数据:提供文本文件
2、准备数据:使用Python解析文本文件,预处理
3、分析数据:可视化处理
4、训练算法:此步骤不适用与k——近邻算法
5、测试算法:使用海伦提供的部分数据作为测试样本。测试样本与非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类与实际类别不一样,则标记为一个错误。
6、使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据来判断对方是否为自己喜欢的类型。
数据集介绍:
海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
海伦收集约会数据已经有了一段时间,她把这些数据存放在文本文件datingTestSet.txt中,每个样本数据占据一行,总共有1000行。
海伦收集的样本数据主要包含以下3种特征:
- 每年获得的飞行常客里程数
- 玩视频游戏所消耗时间百分比
- 每周消费的冰淇淋公升数
数据展示如下:
准备数据
在将上述特征数据输入到分类器前,必须将待处理的数据的格式改变为分类器可以接收的格式。分类器接收的数据是什么格式的?从上小结已经知道,要将数据分类两部分,即特征矩阵和对应的分类标签向量。
代码如下:
import numpy as np
"""
函数说明:
打开文件并进行解析,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类标签
"""
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index +=1
return returnMat, classLabelVector if __name__ == "__main__":
filename = 'datingTestSet.txt'
datingData, datingLabel = file2matrix(filename)
print(datingData)
print(datingLabel)
运行程序之后,得到相应的数据,其中特征数据如下所示:

可以看到,我们已经顺利导入数据,并对数据进行解析,格式化为分类器需要的数据格式。接着我们需要了解数据的真正含义。可以通过直观的图形化的方式观察数据。
分析数据
编写程序将数据可视化:
import numpy as np
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt """
函数说明:
打开文件并进行解析,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类标签
"""
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index +=1
return returnMat, classLabelVector """
函数说明:可视化数据
Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
NO
"""
def showdata(datingData, datingLabel):
font = FontProperties(fname="c:/windows/fonts/simsun.ttc", size=14)
fig, axs = plt.subplots(2, 2, figsize=(13, 8))
numberOfLabel = len(datingLabel)
labelsColors = []
for i in datingLabel:
if i == 1:
labelsColors.append('black')
if i == 2:
labelsColors.append('orange')
if i == 3:
labelsColors.append('red')
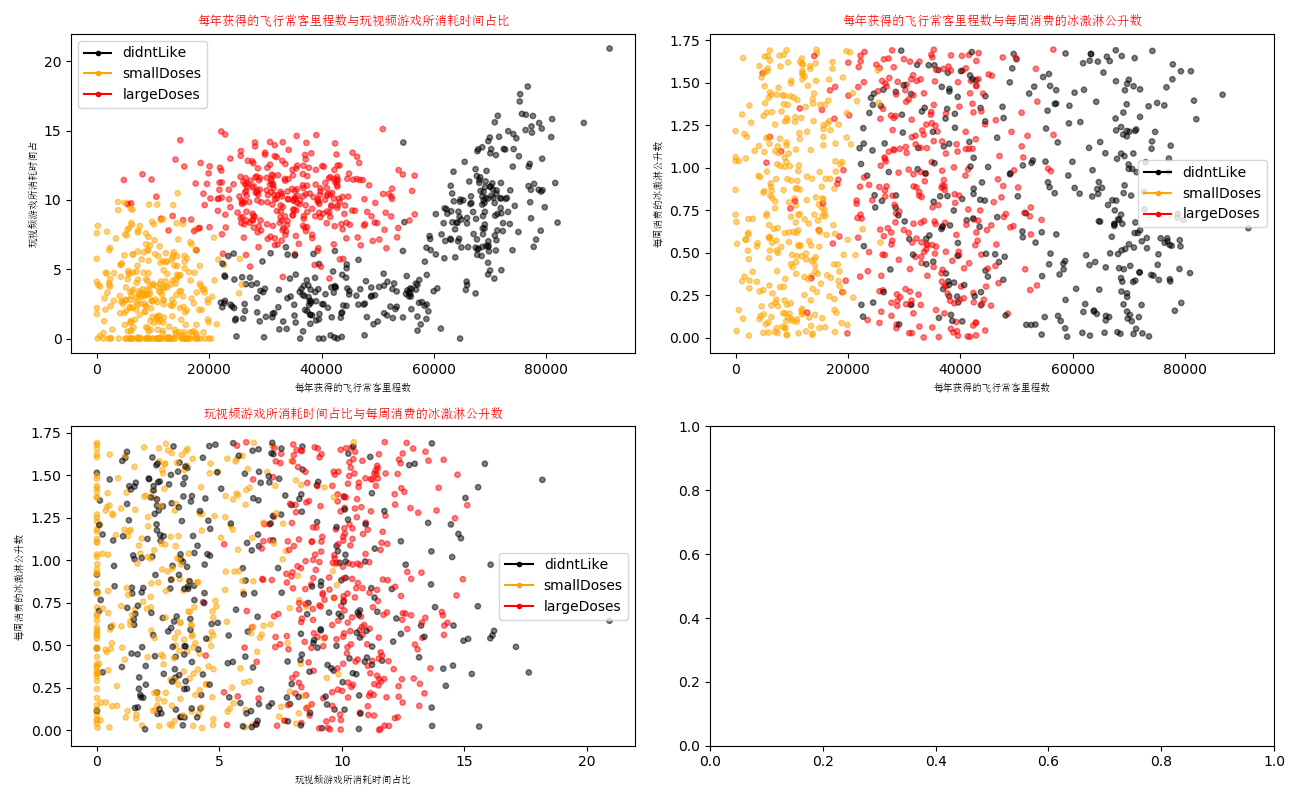
axs[0][0].scatter(x=datingData[:, 0], y=datingData[:, 1], color=labelsColors, s=15, alpha=.5)
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black') axs[0][1].scatter(x=datingData[:, 0], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black') axs[1][0].scatter(x=datingData[:, 1], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
plt.show() if __name__ == "__main__":
filename = 'datingTestSet.txt'
datingData, datingLabel = file2matrix(filename)
showdata(datingData, datingLabel)
运行程序:
准备数据:归一化数值
在上面的数据中可以看出,如果想要计算某两个样本之间的距离,使用开根的方法就会得到一个数值,但是这样的话数字差值最大的属性对计算结果影响就会很大,换句话说:每年获取的飞行常客里程数对于计算结果的影响将远远大于其他特征的影响。而产生这种现象的原因仅仅是因为飞行常客里程数远远大于其他特征值。但是海伦认为这三个特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重的影响到计算结果。
在处理这种不同取值范围的特征值时,我们通常采用的方法是讲数值归一化,如将数值范围处理为0到1或者-1到1之间。
编写名为autoNorm的函数,用该函数自动将数据归一化。代码如下:
import numpy as np
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt """
函数说明:
打开文件并进行解析,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类标签
"""
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index +=1
return returnMat, classLabelVector """
函数说明:可视化数据
Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
NO
"""
def showdata(datingData, datingLabel):
font = FontProperties(fname="c:/windows/fonts/simsun.ttc", size=14)
fig, axs = plt.subplots(2, 2, figsize=(13, 8))
numberOfLabel = len(datingLabel)
labelsColors = []
for i in datingLabel:
if i == 1:
labelsColors.append('black')
if i == 2:
labelsColors.append('orange')
if i == 3:
labelsColors.append('red')
axs[0][0].scatter(x=datingData[:, 0], y=datingData[:, 1], color=labelsColors, s=15, alpha=.5)
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black') axs[0][1].scatter(x=datingData[:, 0], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black') axs[1][0].scatter(x=datingData[:, 1], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
plt.show() """
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def autoNorm(dataset):
minVal = dataset.min(0)
maxVal = dataset.max(0)
ranges = maxVal-minVal
normDataSet = np.zeros(np.shape(dataset))
m = dataset.shape[0]
normDataSet = dataset-np.tile(minVal, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet, ranges, minVal if __name__ == "__main__":
filename = 'datingTestSet.txt'
datingData, datingLabel = file2matrix(filename)
#showdata(datingData, datingLabel)
normDataSet, ranges, minVals = autoNorm(datingData)
print(normDataSet)
print(ranges)
print(minVals)
归一化之后的特征如下:

这样的话,我们已经顺利将数据归一化了,并且求出了数据的取值范围和数据的最小值,这两个值是在分类的时候需要用到的,直接先求解出来,也算是对数据预处理了。
测试算法:作为完整程序验证分类器
机器学习算法一个很重要的工作就是评估算法的正确率,通常我们只提供已有数据的90%作为训练样本来训练分类器,而使用其余的10%数据去测试分类器,检测分类器的正确率。需要注意的是,10%的测试数据应该是随机选择的,由于海伦提供的数据并没有按照特定目的来排序,所以我们可以随意选择10%数据而不影响其随机性。
创建datingClassTest函数:
import numpy as np
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
import operator
"""
函数说明:
打开文件并进行解析,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类标签
"""
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index +=1
return returnMat, classLabelVector """
函数说明:可视化数据
Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
NO
"""
def showdata(datingData, datingLabel):
font = FontProperties(fname="c:/windows/fonts/simsun.ttc", size=14)
fig, axs = plt.subplots(2, 2, figsize=(13, 8))
numberOfLabel = len(datingLabel)
labelsColors = []
for i in datingLabel:
if i == 1:
labelsColors.append('black')
if i == 2:
labelsColors.append('orange')
if i == 3:
labelsColors.append('red')
axs[0][0].scatter(x=datingData[:, 0], y=datingData[:, 1], color=labelsColors, s=15, alpha=.5)
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black') axs[0][1].scatter(x=datingData[:, 0], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black') axs[1][0].scatter(x=datingData[:, 1], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
plt.show() """
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def autoNorm(dataset):
minVal = dataset.min(0)
maxVal = dataset.max(0)
ranges = maxVal-minVal
normDataSet = np.zeros(np.shape(dataset))
m = dataset.shape[0]
normDataSet = dataset-np.tile(minVal, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet, ranges, minVal """
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndices = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndices[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] """
函数说明:分类器测试函数 Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
""" def datingClassTest():
filename = "datingTestSet.txt"
datingDataMat, datingLabels = file2matrix(filename)
hoRatio = 0.10
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :],
datingLabels[numTestVecs:m], 4)
print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率:%f%%" % (errorCount / float(numTestVecs) * 100)) if __name__ == "__main__":
datingClassTest()
运行结果显示:错误率为4%。
我们可以改变函数datingClassTest内变量hoRatio和分类器k的值,检测错误率是否随着变量值的变化而增加。依赖于分类算法、数据集和程序设置,分类器的输出结果可能有很大的不同。
使用算法:构建完整可用系统
上面我们已经在数据上对分类器进行了测试,现在可以使用这个分类器为海伦来对人们分类。我们会给海伦一个小程序,通过该程序,海伦可以在约会网站上找到某人并输入他的信息,程序会给出她对对方喜欢程度的预测值。
最终程序如下:
import numpy as np
from matplotlib.font_manager import FontProperties
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
import operator
"""
函数说明:
打开文件并进行解析,对数据进行分类:1代表不喜欢,2代表魅力一般,3代表极具魅力
Parameters:
filename - 文件名
Returns:
returnMat - 特征矩阵
classLabelVector - 分类标签
"""
def file2matrix(filename):
fr = open(filename)
arrayOLines = fr.readlines()
numberOfLines = len(arrayOLines)
returnMat = np.zeros((numberOfLines, 3))
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip()
listFromLine = line.split('\t')
returnMat[index, :] = listFromLine[0:3]
if listFromLine[-1] == 'didntLike':
classLabelVector.append(1)
elif listFromLine[-1] == 'smallDoses':
classLabelVector.append(2)
elif listFromLine[-1] == 'largeDoses':
classLabelVector.append(3)
index +=1
return returnMat, classLabelVector """
函数说明:可视化数据
Parameters:
datingDataMat - 特征矩阵
datingLabels - 分类Label
Returns:
NO
"""
def showdata(datingData, datingLabel):
font = FontProperties(fname="c:/windows/fonts/simsun.ttc", size=14)
fig, axs = plt.subplots(2, 2, figsize=(13, 8))
numberOfLabel = len(datingLabel)
labelsColors = []
for i in datingLabel:
if i == 1:
labelsColors.append('black')
if i == 2:
labelsColors.append('orange')
if i == 3:
labelsColors.append('red')
axs[0][0].scatter(x=datingData[:, 0], y=datingData[:, 1], color=labelsColors, s=15, alpha=.5)
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black') axs[0][1].scatter(x=datingData[:, 0], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black') axs[1][0].scatter(x=datingData[:, 1], y=datingData[:, 2], color=labelsColors, s=15, alpha=.5)
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
plt.show() """
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def autoNorm(dataset):
minVal = dataset.min(0)
maxVal = dataset.max(0)
ranges = maxVal-minVal
normDataSet = np.zeros(np.shape(dataset))
m = dataset.shape[0]
normDataSet = dataset-np.tile(minVal, (m, 1))
normDataSet = normDataSet / np.tile(ranges, (m, 1))
return normDataSet, ranges, minVal """
函数说明:kNN算法,分类器
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
k - kNN算法参数,选择距离最小的k个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndices = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndices[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0] """
函数说明:分类器测试函数 Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
""" def datingClassTest():
filename = "datingTestSet.txt"
datingDataMat, datingLabels = file2matrix(filename)
hoRatio = 0.10
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m * hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :],
datingLabels[numTestVecs:m], 4)
print("分类结果:%d\t真实类别:%d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率:%f%%" % (errorCount / float(numTestVecs) * 100)) """
函数说明:通过输入一个人的三维特征,进行分类输出
"""
def classifyPerson():
resultList = ['讨厌', '有些喜欢', '非常喜欢']
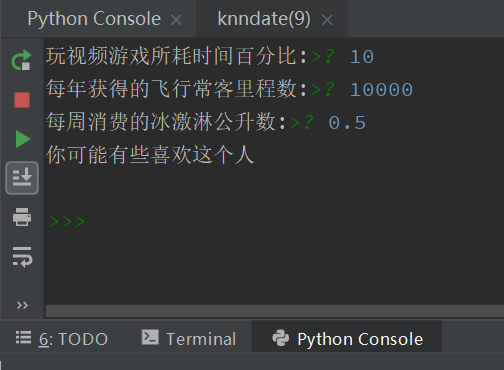
precentTats = float(input("玩视频游戏所耗时间百分比:"))
ffMiles = float(input("每年获得的飞行常客里程数:"))
iceCream = float(input("每周消费的冰激淋公升数:"))
filename = "datingTestSet.txt"
datingDataMat, datingLabels = file2matrix(filename)
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = np.array([ffMiles, precentTats, iceCream])
norminArr = (inArr - minVals) / ranges
classifierResult = classify0(norminArr, normMat, datingLabels, 3)
print("你可能%s这个人" % (resultList[classifierResult-1])) if __name__ == "__main__":
#datingClassTest()
classifyPerson()
运行程序,依次输入:10,10000,0.5.
得到结果:你可能有些喜欢这个人
如下图所示:
k-近邻(KNN)算法改进约会网站的配对效果[Python]的更多相关文章
- 使用K近邻算法改进约会网站的配对效果
1 定义数据集导入函数 import numpy as np """ 函数说明:打开并解析文件,对数据进行分类:1 代表不喜欢,2 代表魅力一般,3 代表极具魅力 Par ...
- 【Machine Learning in Action --2】K-近邻算法改进约会网站的配对效果
摘自:<机器学习实战>,用python编写的(需要matplotlib和numpy库) 海伦一直使用在线约会网站寻找合适自己的约会对象.尽管约会网站会推荐不同的人选,但她没有从中找到喜欢的 ...
- 机器学习读书笔记(二)使用k-近邻算法改进约会网站的配对效果
一.背景 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可以进行如下分类 不喜欢的人 魅力一般的人 极具魅 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 使用k-近邻算法改进约会网站的配对效果
---恢复内容开始--- < Machine Learning 机器学习实战>的确是一本学习python,掌握数据相关技能的,不可多得的好书!! 最近邻算法源码如下,给有需要的入门者学习, ...
- 机器学习实战1-2.1 KNN改进约会网站的配对效果 datingTestSet2.txt 下载方法
今天读<机器学习实战>读到了使用k-临近算法改进约会网站的配对效果,道理我都懂,但是看到代码里面的数据样本集 datingTestSet2.txt 有点懵,这个样本集在哪里,只给了我一个文 ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
- k-近邻算法-优化约会网站的配对效果
KNN原理 1. 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系. 2. 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较. a. 计算新 ...
随机推荐
- Java开发知识之Java中的泛型
Java开发知识之Java中的泛型 一丶简介什么是泛型. 泛型就是指泛指任何数据类型. 就是把数据类型用泛型替代了. 这样是可以的. 二丶Java中的泛型 Java中,所有类的父类都是Object类. ...
- Java开发知识之Java的包装类
Java开发知识之Java的包装类 一丶什么是包装类 包装类的意思就是对基本数据类型封装成一个类.这些类都是Number的子类.区别就是封装数据类型不同.包含的方法基本相同. 具体可以查询JAVA A ...
- [一]FileDescriptor文件描述符 标准输入输出错误 文件描述符
文件描述符 当应用程序请求打开或者操作文件时,操作系统为应用程序设置一张文件列表,具体的实现形式此处不深入说明 操作系统会提供给你一个非负整数,作为一个索引号,它的作用就像地址或者说指针或者说偏移 ...
- java 虚拟机内存划分,类加载过程以及对象的初始化
涉及关键词: 虚拟机运行时内存 java内存划分 类加载顺序 类加载时机 类加载步骤 对象初始化顺序 构造代码块顺序 构造方法 顺序 内存区域 java内存图 堆 方法区 虚拟机栈 本地 ...
- 关于跨DB增量(增、改)同步两张表的数据小技巧
有些场景下,需要隔离不同的DB,彼此DB之间不能互相访问,但实际的业务场景又需要从A DB访问B DB的情形,这时怎么办?我认为有如下常规的三种方案: 1.双方提供RESET API,需要访问不同DB ...
- 搞懂Linux下的几种文件类型
在Linux系统下,有七类文件类型: 普通文件(-) 目录(d) 软链接(字符链接L) 套接字文件(S) 字符设备(S) 块设备(B) 管道文件(命名管道P) 普通文件.目录.软链接无需多解释. 管道 ...
- Python迭代和解析(2):迭代初探
解析.迭代和生成系列文章:https://www.cnblogs.com/f-ck-need-u/p/9832640.html 在Python中支持两种循环格式:while和for.这两种循环的类型不 ...
- 解读经典《C#高级编程》最全泛型协变逆变解读 页127-131.章4
前言 本篇继续讲解泛型.上一篇讲解了泛型类的定义细节.本篇继续讲解泛型接口. 泛型接口 使用泛型可定义接口,即在接口中定义的方法可以带泛型参数.然后由继承接口的类实现泛型方法.用法和继承泛型类基本没有 ...
- 【响应式编程的思维艺术】 (1)Rxjs专题学习计划
目录 一. 响应式编程 二. 学习路径规划 一. 响应式编程 响应式编程,也称为流式编程,对于非前端工程师来说,可能并不是一个陌生的名词,它是函数式编程在软件开发中应用的延伸,如果你对函数式编程还没有 ...
- 第44章 添加新协议 - Identity Server 4 中文文档(v1.0.0)
除了对OpenID Connect和OAuth 2.0的内置支持之外,IdentityServer4还允许添加对其他协议的支持. 您可以将这些附加协议端点添加为中间件或使用例如MVC控制器.在这两种情 ...