LAB1 partI
序言
part I
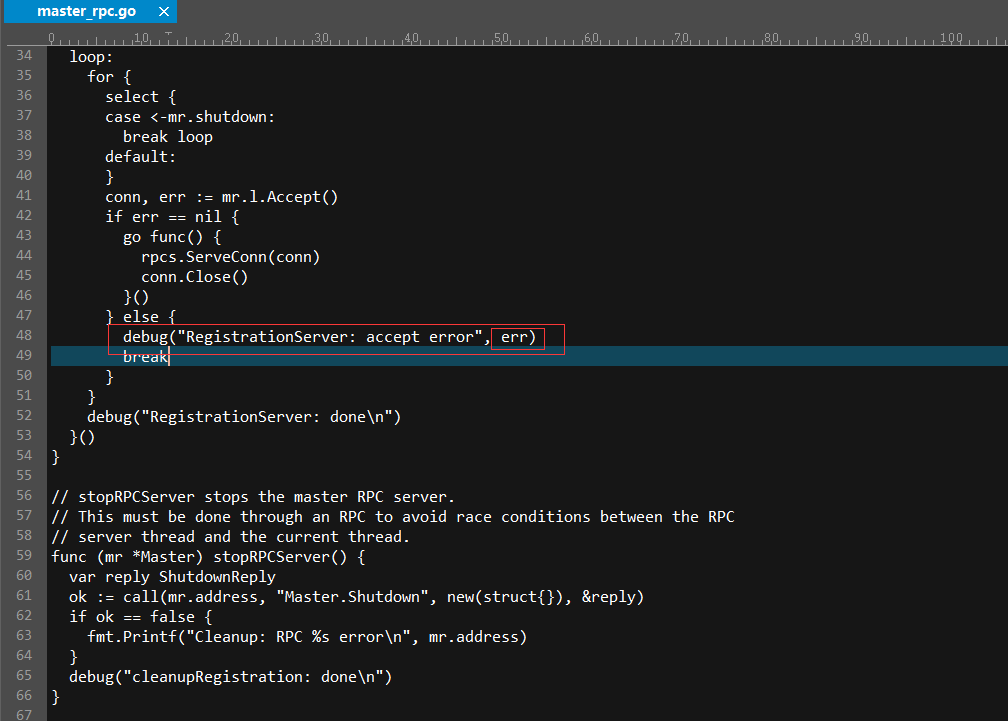

多了 : 号
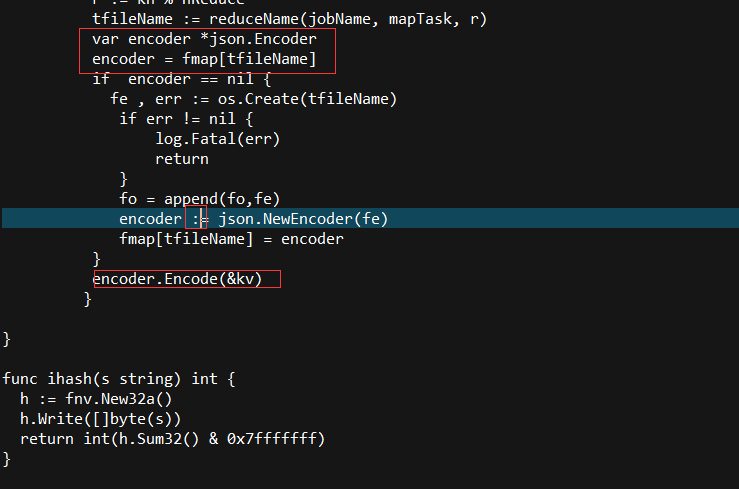
common_map.go
package mapreduce import (
"hash/fnv"
"io"
"os"
"io/ioutil"
"log"
"encoding/json"
) func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) { bs,err:=ioutil.ReadFile(inFile)
if err != io.EOF && err != nil {
log.Fatal(err)
return
}
filecontent := string(bs)
fmap := make(map[string]*json.Encoder)
fo := make([]*os.File,nReduce)
defer func(){
for _, fff := range fo {
fff.Close()
}
}() kvs := mapF(inFile, filecontent)
for _ , kv := range kvs {
k := kv.Key
kh := ihash(k)
r := kh % nReduce
tfileName := reduceName(jobName, mapTask, r)
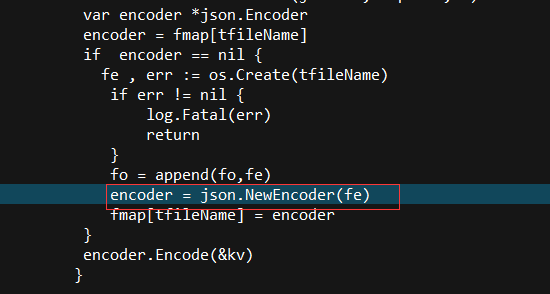
var encoder *json.Encoder
encoder = fmap[tfileName]
if encoder == nil {
fe , err := os.Create(tfileName)
if err != nil {
log.Fatal(err)
return
}
fo = append(fo,fe)
encoder = json.NewEncoder(fe)
fmap[tfileName] = encoder
}
encoder.Encode(&kv)
} } func ihash(s string) int {
h := fnv.New32a()
h.Write([]byte(s))
return int(h.Sum32() & 0x7fffffff)
}
common_reduce.go
package mapreduce import (
"io"
"os"
"log"
"encoding/json"
) func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) { kvm := make(map[string][]string)
fo := make([]*os.File,nMap)
defer func(){
for _, fff := range fo {
fff.Close()
}
}()
for i := ; i< nMap; i++ {
tf := reduceName(jobName, i, reduceTask)
ff, err := os.Open(tf)
if err != nil {
log.Fatal(err)
panic(err)
}
fo=append(fo,ff)
decoder := json.NewDecoder(ff)
var ky KeyValue
for {
if err := decoder.Decode(&ky); err == io.EOF {
break
} else if(err != nil) {
log.Fatal(err)
panic(err)
}
vlist := kvm[ky.Key];
vlist = append(vlist, ky.Value)
kvm[ky.Key] = vlist
}
}
tfileName := mergeName(jobName, reduceTask) fe,err := os.Create(tfileName)
if err != nil {
log.Fatal(err)
panic(err)
}
defer func(){
fe.Close();
}()
encoder := json.NewEncoder(fe)
for k , v := range kvm {
encoder.Encode(KeyValue{k, reduceF(k,v)})
} }
LAB1 partI的更多相关文章
- 6.828 lab1 bootload
MIT6.828 lab1地址:http://pdos.csail.mit.edu/6.828/2014/labs/lab1/ 第一个练习,主要是让我们熟悉汇编,嗯,没什么好说的. Part 1: P ...
- Machine Learning #Lab1# Linear Regression
Machine Learning Lab1 打算把Andrew Ng教授的#Machine Learning#相关的6个实验一一实现了贴出来- 预计时间长度战线会拉的比較长(毕竟JOS的7级浮屠还没搞 ...
- ucore lab1 bootloader学习笔记
---恢复内容开始--- 开机流程回忆 以Intel 80386为例,计算机加电后,CPU从物理地址0xFFFFFFF0(由初始化的CS:EIP确定,此时CS和IP的值分别是0xF000和0xFFF0 ...
- LAB1 partV
partV 创建文档反向索引.word -> document 与 前面做的 单词统计类似,这个是单词与文档位置的映射关系. mapF 文档解析相同,返回信息不同而已. reduceF 返回归约 ...
- 6.824 LAB1 环境搭建
MIT 6.824 LAB1 环境搭建 vmware 虚拟机 linux ubuntu server 安装 go 官方安装步骤: 下载此压缩包并提取到 /usr/local 目录,在 /usr/l ...
- 软件测试:lab1.Junit and Eclemma
软件测试:lab1.Junit and Eclemma Task: Install Junit(4.12), Hamcrest(1.3) with Eclipse Install Eclemma wi ...
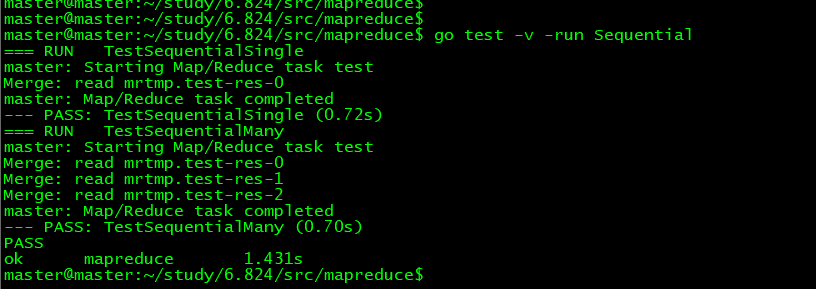
- MIT 6.824 lab1:mapreduce
这是 MIT 6.824 课程 lab1 的学习总结,记录我在学习过程中的收获和踩的坑. 我的实验环境是 windows 10,所以对lab的code 做了一些环境上的修改,如果你仅仅对code 感兴 ...
- 清华大学OS操作系统实验lab1练习知识点汇总
lab1知识点汇总 还是有很多问题,但是我觉得我需要在查看更多资料后回来再理解,学这个也学了一周了,看了大量的资料...还是它们自己的80386手册和lab的指导手册觉得最准确,现在我就把这部分知识做 ...
- JOS lab1 part2 分析
lab1的Exercise 2就是让我们熟悉gdb的si操作,并知道BIOS的几条指令在做什么就够了,所以我们也会尽可能的去分析每一行代码. 首先进入到6.8282/lab这个目录下,输入指令make ...
随机推荐
- js循环出相同name,不同id的按钮,对其进行点击回复操作
function getseat(){ var option= "<button class='btn'style='margin:5px;' onclick='onclickSeat ...
- 运维ldd语法--》ldconfig
Linux:ldd命令详解 ldd 用于打印程序或者库文件所依赖的共享库列表. 语法 ldd(选项)(参数) 选项 --version:打印指令版本号: -v:详细信息模式,打印所有相关信息: - ...
- Linux命令rz
rz :上传文件:sz: 下载文件: 在linux 系统中,使用rz(或 sz) 命令是,提示 -bash: rz(或者是sz): command not found .这个时候,说明没有安装 lrz ...
- 关于SpringMVC的配置流程以及一些细节
首先说道SpringMvc是什么,SpringMVC是Spring框架里面的一个子框架,它对网站前后端的代码分层做了一套实现,这套实现给我们带来了几个好处,首先第一,SpringMVC实现了一个请求对 ...
- [转载]前端 阿里p6面试题集锦含答案
1.说一下你了解CSS盒模型. 盒模型分为:IE的怪异盒模型和标注浏览器的盒模型,然后可以通过box-sizing属性控制两种盒模型的变换. 2.说一下box-sizing的应用场景. 这个也不难,简 ...
- python3+cv2+andiord安卓摄像头
#coding=utf-8import cv2 import time if __name__ == '__main__': cv2.namedWindow("camera",1) ...
- Mac pip install mysql-python
首次在mac os 下,用pip install MySQL-Python时经常出现如下错误: sh: mysql_config: command not foundTraceback (most r ...
- Charles Map Local 中文显示乱码问题
最近在迁移客户端的业务,用React Native实现,在用本地数据测试Android的时候,遇到到中文乱码的问题.是因为编码问题. 一.首先看看文件编码是否是UTF-8,我的电脑是安装了Sublim ...
- IOS 生成静态库文件(.framework)
http://blog.csdn.net/zwl492454828/article/details/55095422
- Python:从入门到实践--第九章-类--练习
#.餐馆:创建一个名为Restaurant的类,其方法_init_()设置两个属性:restaurant_name和cuisine_type. #创建一个名为describe_restaurant的方 ...