KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!)
1、KNN介绍
K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法。
机器学习,算法本身不是最难的,最难的是:
1、数学建模:把业务中的特性抽象成向量的过程;
2、选取适合模型的数据样本。
这两个事都不是简单的事。算法反而是比较简单的事。
本质上,KNN算法就是用距离来衡量样本之间的相似度。
2、算法图示
◊ 从训练集中找到和新数据最接近的k条记录,然后根据多数类来决定新数据类别。
◊算法涉及3个主要因素:
1) 训练数据集
2) 距离或相似度的计算衡量
3) k的大小
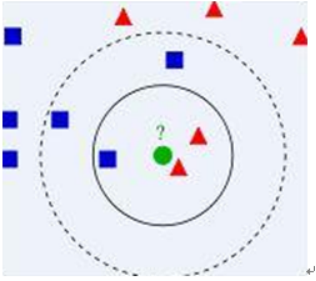
◊算法描述
1) 已知两类“先验”数据,分别是蓝方块和红三角,他们分布在一个二维空间中
2) 有一个未知类别的数据(绿点),需要判断它是属于“蓝方块”还是“红三角”类
3) 考察离绿点最近的3个(或k个)数据点的类别,占多数的类别即为绿点判定类别
3、算法要点
3.1、计算步骤
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
3.2、相似度的度量
◊距离越近应该意味着这两个点属于一个分类的可能性越大。
但,距离不能代表一切,有些数据的相似度衡量并不适合用距离
◊相似度衡量方法:包括欧式距离、夹角余弦等。
(简单应用中,一般使用欧氏距离,但对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适)
3.3、类别的判定
◊简单投票法:少数服从多数,近邻中哪个类别的点最多就分为该类。
◊加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
3.4、算法不足
- 样本不平衡容易导致结果错误
◊如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
◊改善方法:对此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
- 计算量较大
◊因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
◊改善方法:事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
该方法比较适用于样本容量比较大的类域的分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
4、KNN分类算法python实现(python2.7)
需求:
有以下先验数据,使用knn算法对未知类别数据分类
|
属性1 |
属性2 |
类别 |
|
1.0 |
0.9 |
A |
|
1.0 |
1.0 |
A |
|
0.1 |
0.2 |
B |
|
0.0 |
0.1 |
B |
未知类别数据
|
属性1 |
属性2 |
类别 |
|
1.2 |
1.0 |
? |
|
0.1 |
0.3 |
? |
python实现:
KNN.py脚本文件
#!/usr/bin/python
# coding=utf-8
#########################################
# kNN: k Nearest Neighbors # 输入: newInput: (1xN)的待分类向量
# dataSet: (NxM)的训练数据集
# labels: 训练数据集的类别标签向量
# k: 近邻数 # 输出: 可能性最大的分类标签
######################################### from numpy import *
import operator # 创建一个数据集,包含2个类别共4个样本
def createDataSet():
# 生成一个矩阵,每行表示一个样本
group = array([[1.0, 0.9], [1.0, 1.0], [0.1, 0.2], [0.0, 0.1]])
# 4个样本分别所属的类别
labels = ['A', 'A', 'B', 'B']
return group, labels # KNN分类算法函数定义
def kNNClassify(newInput, dataSet, labels, k):
numSamples = dataSet.shape[0] # shape[0]表示行数 # # step 1: 计算距离[
# 假如:
# Newinput:[1,0,2]
# Dataset:
# [1,0,1]
# [2,1,3]
# [1,0,2]
# 计算过程即为:
# 1、求差
# [1,0,1] [1,0,2]
# [2,1,3] -- [1,0,2]
# [1,0,2] [1,0,2]
# =
# [0,0,-1]
# [1,1,1]
# [0,0,-1]
# 2、对差值平方
# [0,0,1]
# [1,1,1]
# [0,0,1]
# 3、将平方后的差值累加
# [1]
# [3]
# [1]
# 4、将上一步骤的值求开方,即得距离
# [1]
# [1.73]
# [1]
#
# ]
# tile(A, reps): 构造一个矩阵,通过A重复reps次得到
# the following copy numSamples rows for dataSet
diff = tile(newInput, (numSamples, 1)) - dataSet # 按元素求差值
squaredDiff = diff ** 2 # 将差值平方
squaredDist = sum(squaredDiff, axis = 1) # 按行累加
distance = squaredDist ** 0.5 # 将差值平方和求开方,即得距离 # # step 2: 对距离排序
# argsort() 返回排序后的索引值
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be append element)
for i in xrange(k):
# # step 3: 选择k个最近邻
voteLabel = labels[sortedDistIndices[i]] # # step 4: 计算k个最近邻中各类别出现的次数
# when the key voteLabel is not in dictionary classCount, get()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 # # step 5: 返回出现次数最多的类别标签
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key return maxIndex
KNNTest.py测试文件
#!/usr/bin/python
# coding=utf-8
import KNN
from numpy import *
# 生成数据集和类别标签
dataSet, labels = KNN.createDataSet()
# 定义一个未知类别的数据
testX = array([1.2, 1.0])
k = 3
# 调用分类函数对未知数据分类
outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel testX = array([0.1, 0.3])
outputLabel = KNN.kNNClassify(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
运行结果:

KNN分类算法及python代码实现的更多相关文章
- 决策树分类算法及python代码实现案例
决策树分类算法 1.概述 决策树(decision tree)——是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现 ...
- knn分类算法学习
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的 ...
- KNN分类算法实现手写数字识别
需求: 利用一个手写数字“先验数据”集,使用knn算法来实现对手写数字的自动识别: 先验数据(训练数据)集: ♦数据维度比较大,样本数比较多. ♦ 数据集包括数字0-9的手写体. ♦每个数字大约有20 ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 后端程序员之路 12、K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法,是最简单的机器学习算法之一.由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重 ...
- KNN分类算法--python实现
一.kNN算法分析 K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:如果一个样本在特征空间中 ...
- 在Ignite中使用k-最近邻(k-NN)分类算法
在本系列前面的文章中,简单介绍了一下Ignite的线性回归算法,下面会尝试另一个机器学习算法,即k-最近邻(k-NN)分类.该算法基于对象k个最近邻中最常见的类来对对象进行分类,可用于确定类成员的关系 ...
- KNN分类算法
K邻近算法.K最近邻算法.KNN算法(k-Nearest Neighbour algorithm):是数据挖掘分类技术中最简单的方法之一 KNN的工作原理 所谓K最近邻,就是k个最近的邻居的意思,说的 ...
随机推荐
- C# CEF 封装UserControl
using System; using System.Collections.Generic; using System.ComponentModel; using System.Drawing; u ...
- Java——关于num++和++num
public class num_add_add { public static void numAdd(){ int num = 10; int a = num++; System.out.prin ...
- fatal error C1083: 无法打开包括文件: “SDKDDKVer.h”: No such file or directory(转)
fatal error C1083: 无法打开包括文件: “SDKDDKVer.h”: No such file or directory 解决办法:(Vs2013中) 项目--右键--属性--配置属 ...
- luogu P1943 LocalMaxima_NOI导刊2009提高(1)
又是有关于\(1-n\)排列的题,考虑从大到小依次插入构造排列 对于第\(i\)个数(也就是\(n-i+1\)),只有当它插在当前排列最前面时才会使那个什么数的个数+1,而在最前面的概率为\(\fra ...
- mysql架构解读~mysql的多源复制
一 场景需求 多源复制版本 5.7,目标主机5.6.21 4个DB机器的某些数据库需要数据汇总进行连表查询 二 进行搭建 1 导出相应的目的库 mysqldump -uuser -ppass ...
- android greenDao使用
github:https://github.com/greenrobot/greenDAO 基本使用:https://toutiao.io/posts/yg1kyu/preview https://b ...
- dbms_metadata.get_ddl的用法(DDL)
dbms_metadata包中的get_ddl函数 --GET_DDL: Return the metadata for a single object as DDL. -- This interfa ...
- centos6.5/centos7安装部署企业内部知识管理社区系统wecenter
企业内部知识系统wecenter社区系统安装及部署 centos 6.5环境安装 因为是公司内部使用在线人数不会太多,使用yum安装lamp环境即可 1.安装lamp基本环境 yum -y insta ...
- RestTemplate -springwebclient
1 使用jar版本 - spring-web-4.3.8.RELEASE.jar 场景:backend,post请求远端,header中加入accessToken,用于权限控制 HttpHeaders ...
- centos7忘记登录密码修改
很多时候我们都会忘记Linux root 用户的口令,下面就教大家如果忘记root口令怎么办 第1步:开机后在内核上按“e”.截图如下 按e以后会进入内核启动页面,如下图 第2步:在linux16这行 ...