KMP算法(next数组方法)
KMP算法之前需要说一点串的问题:
串:
字符串:ASCII码为基本数据形成的一堆线性结构。
串是一个线性结构;它的存储形式:
typedef struct STRING {
CHARACTER *head;
int length;
};
朴素的串匹配算法:
设文本串text = "ababcabcacbab",模式串为patten = "abcac" 其匹配过程如下图所示。
黑色线条代表匹配位置,红色斜杠代表失配位置

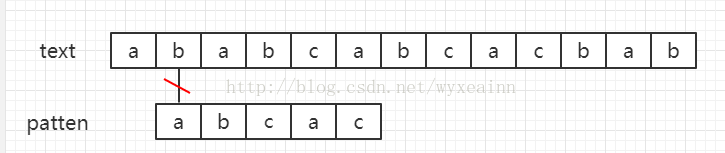

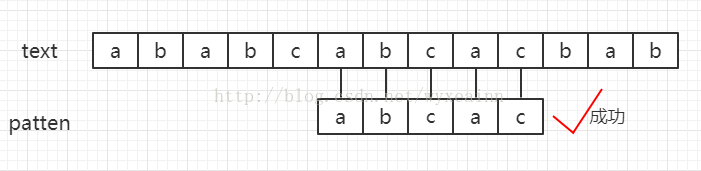
算法说明:
一般匹配字符串时,我们从目标字符串text(假设长度为n)的第一个下标选取和patten长度(长度为m)一样的子字符串进行比较,如果一样,就返回开始处的下标值,不一样,选取text下一个下标,同样选取长度为n的字符串进行比较,直到str的末尾(实际比较时,下标移动到n-m)。在普通的匹配中,假如从文本串的第i个字符来开始于模式串匹配。当匹配到模式串的第j位发现失配,即text[i+j] != patten[j]的时候,我们又从文本串的第i+1个位置来重新开始匹配。尽管我们已经知道了好多字符其实根本就匹配不上,我们还是进行了这个过程,这个时候回溯的过程会非常耗费我们的时间。这样的时间复杂度是O(n*m)。
代码如下:
int search(const char*str,const char *subStr) {
int strlen = strlen(str);
int subStrlen = strlen(subStr);
int i;
int j;
for(i = ;i <= strlen - subStrlen;i++){
for(j = ;j < subStrlen;j++){
if(str[i + j] != subStr[j])
break;
}判断subStrlen是否比较完成
}
}
KMP算法:
而KMP算法的实质就是,当遇到text[i+j] != patten[j]的时候,但是我们知道模式串中的 0~j-1 位置上的字符已经于i ~ i+j-1位置上的字符是完全匹配的。就不再重新从text[i+1]开始匹配,而是根据next数组的下标找到patten的下标,从那个下标开始匹配。从而时间复杂度为O(m+n)。
例如模式串Patten = "abaabcac"。其next数组如图所示:
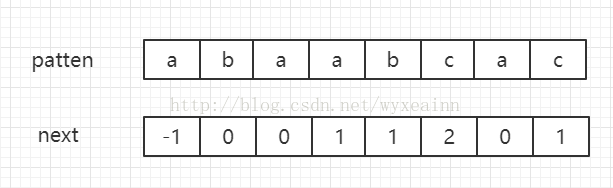

我们可以看到这次的匹配在蓝色的c失配了,而c的下标为5,他的next数组的下标为2。因此,下次的匹配不再是从text[1]开始,而是从text[2]开始,这样就省去了不必要的比较。

代码如下:
#include <stdio.h>
#include <malloc.h>
#include <string.h> #include "kmpmec.h" void getNext(const char *str, int *next);
int KMPSearch(const char *str, const char *subStr); int KMPSearch(const char *str, const char *subStr) {
int strLen = strlen(str);
int subLen = strlen(subStr);
int *next;
int i = ;
int j = ; if (strLen <= || subLen <= || strLen < subLen) {
return -;
}
next = (int *) calloc(sizeof(int), subLen);
if (subLen > ) {
getNext(subStr, next);
} while (strLen - i + next[j] >= subLen) {
while (subStr[j] != && str[i] == subStr[j]) {
i++;
j++;
}
if (subStr[j] == ) {
free(next);
return i - subLen;
} else if (j == ) {
i++;
j = ;
} else {
j = next[j];
}
} free(next);
return -;
} void getNext(const char *str, int *next) { //得到next数组
int i = ;
int j = ;
boolean flag; next[] = next[] = ; //next数组的前两个下标一定为零
for (i = ; str[i]; i++) {
for (flag = TRUE; flag;) {
if (str[i-] == str[j]) { //通过比较失配位置的前一个和前一个下标元素的比较,获取next数组的下标。
next[i] = ++j;
flag = FALSE;
} else if (j == ) {
next[i] = ;
flag = FALSE;
} else {
j = next[j];
}
}
}
} int main(void) {
char str[];
char subStr[];
int result; printf("请输入源字符串:");
gets(str);
printf("请输入子字符串:");
gets(subStr); result = KMPSearch(str, subStr);
if (result == -) {
printf("字符串[%s]不存在子串[%s]\n", str, subStr);
} else {
printf("子串[%s]第一次出现在字符串[%s]中的下标为%d\n", subStr, str, result);
} return ;
};
KMP算法(next数组方法)的更多相关文章
- 转载-KMP算法前缀数组优雅实现
转自:http://www.cnblogs.com/10jschen/archive/2012/08/21/2648451.html 我们在一个母字符串中查找一个子字符串有很多方法.KMP是一种最常见 ...
- 第4章学习小结_串(BF&KMP算法)、数组(三元组)
这一章学习之后,我想对串这个部分写一下我的总结体会. 串也有顺序和链式两种存储结构,但大多采用顺序存储结构比较方便.字符串定义可以用字符数组比如:char c[10];也可以用C++中定义一个字符串s ...
- KMP算法next数组求解
关于KMP算法,许多教材用的是递推式求解,虽然代码简洁,但是有些不好理解,这里我介绍一种迭代求next数组的方法 KMP算法关键部分就是滑动模式串,我们可以每次滑动一个单位,直到出现可能匹配的情况,此 ...
- 数据结构之KMP算法next数组
我们要找到一个短字符串(模式串)在另一个长字符串(原始串)中的起始位置,也就是模式匹配,最关键的是找到next数组.最简单的算法就是用双层循环来解决,但是这种算法效率低,kmp算法是针对模式串自身的特 ...
- KMP算法&next数组总结
http://www.cnblogs.com/yjiyjige/p/3263858.html KMP算法应该是每一本<数据结构>书都会讲的,算是知名度最高的算法之一了,但很可惜,我大二那年 ...
- KMP算法 Next数组详解
题面 题目描述 如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置. 为了减少骗分的情况,接下来还要输出子串的前缀数组next.如果你不知道这是什么意思也不要问,去百 ...
- 【文文殿下】浅谈KMP算法next数组与循环节的关系
KMP算法 KMP算法是一种字符串匹配算法,他可以在O(n+m)的时间内求出一个模式串在另一个模式串下出现的次数. KMP算法是利用next数组进行自匹配,然后来进行匹配的. Next数组 Next数 ...
- KMP算法(推导方法及模板)
介绍 克努斯-莫里斯-普拉特算法Knuth-Morris-Pratt字符串查找算法(简称为KMP算法)可在一个主文本字符串S内查找一个词W的出现位置.此算法通过运用对这个词在不匹配时本身就包含足够的信 ...
- poj1961(kmp算法next数组应用)
题目链接:https://vjudge.net/problem/POJ-1961 题意:给定一个长为n的字符串(n<=1e6),对于下标i(2<=i<=n),如果子串s(1...i) ...
- POJ-2752(KMP算法+前缀数组的应用)
Seek the Name, Seek the Fame POJ-2752 本题使用的算法还是KMP 最主要的片段就是前缀数组pi的理解,这里要求解的纸盒pi[n-1]有关,但是还是需要使用一个循环来 ...
随机推荐
- oracle 12c AUTO_SAMPLE_SIZE动态采用工作机制
The ESTIMATE_PERCENT parameter in DBMS_STATS.GATHER_*_STATS procedures controls the percentage of ro ...
- centos6.5安装部署zabbix监控服务端和客户端
部署zabbix服务端需要LNMP环境(nginx,mysql,php),其它数据库也可以,我这里使用mysql,关于LNMP环境部署,可以参考我的另一遍文章:http://www.cnblogs.c ...
- Windows Media Player添加播放插件
- EXP7 网络欺诈技术防范(修改版)
实践内容 本实践的目标理解常用网络欺诈背后的原理,以提高防范意识,并提出具体防范方法. 1.简单应用SET工具建立冒名网站 2.ettercap DNS spoof 3.结合应用两种技术,用DNS s ...
- android uboot中的mmc命令
一:mmc的命令如下: 1:对mmc读操作 mmc read addr blk# cnt 2:对mmc写操作 mmc write addr blk# cnt 3:对mmc擦除操作 mmc erase ...
- topcoder srm 691 div1 -3
1.给定一个$n$个顶点$n$个边的图,边是$(i,a_{i})$,顶点编号$[0,n-1]$.增加一个顶点$n$,现在选出一个顶点集$M$,对于任意的在$M$中 的顶点$x$,去掉边$(x,a_{x ...
- 为什么不能用drop function add 去删除函数? 因为不能使用 mysql中的保留字!
mysql中有很多的 保留字, 也叫关键字, 你在使用 数据库中的任何东西, 都最好是 避开这些关键字/保留字, 包括 数据库名, 表名, 字段名, 函数名, 存储过程名. 这些关键字包括: mysq ...
- 振兴中华|2013年蓝桥杯A组题解析第三题-fishers
标题: 振兴中华 小明参加了学校的趣味运动会,其中的一个项目是:跳格子. 地上画着一些格子,每个格子里写一个字,如下所示:(也可参见p1.jpg) 从我做起振 我做起振兴 做起振兴中 起振兴中华 比赛 ...
- 抠图|计蒜客2019蓝桥杯省赛 B 组模拟赛(一)
样例输入: 3 4 5 1 0 0 0 1 1 0 1 0 1 1 0 1 0 1 1 0 0 0 1 5 6 1 1 1 1 1 1 1 0 1 0 1 1 1 0 1 0 1 1 1 0 0 0 ...
- HDU 4632 Palindrome subsequence & FJUT3681 回文子序列种类数(回文子序列个数/回文子序列种数 容斥 + 区间DP)题解
题意1:问你一个串有几个不连续子序列(相同字母不同位置视为两个) 题意2:问你一个串有几种不连续子序列(相同字母不同位置视为一个,空串视为一个子序列) 思路1:由容斥可知当两个边界字母相同时 dp[i ...