强化学习--QLearning
1.概述:
QLearning基于值函数的方法,不同与policy gradient的方法,Qlearning是预测值函数,通过值函数来选择
值函数最大的action,而policy gradient直接预测出action。
目标就是选择出最佳action。
2一些定义
2.1值函数
Given an actor π, it evaluates how good the actor is
有2种值函数,V(S) 、Q(s,a).
2.1.1 V(S)

有2种衡量的方法:

MC方法只能等玩完一个episode才能进行统计评价,效率比较低。

TD方法可以每玩一步就更新一次。
mc与td对比,mc需要估计的是一个episode的值函数,方差比较大,而td是与时间相关的,只有r是需要估计的,方差比较小。
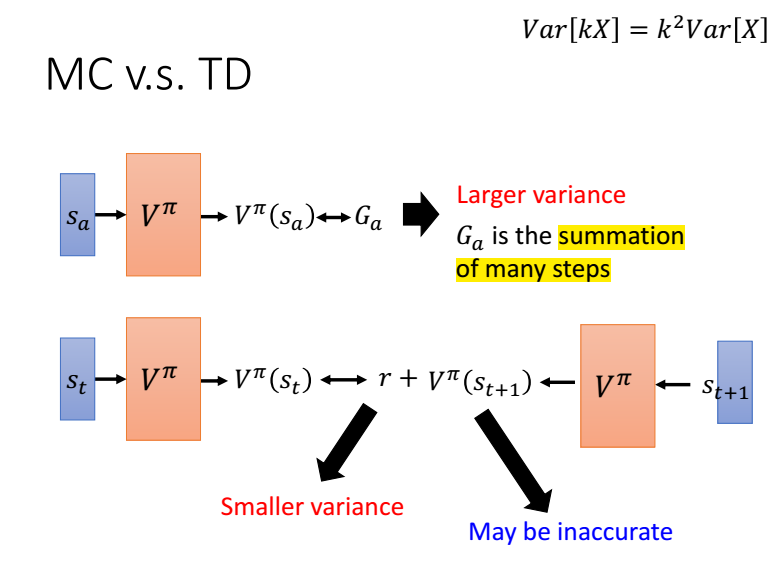
下面看一下例子:
V(Sb)=6/8=1
MC: V(Sa)=0/2=0
TD: V(Sa)=V(Sb)+0=3/4

2.1.2 Q(s,a)
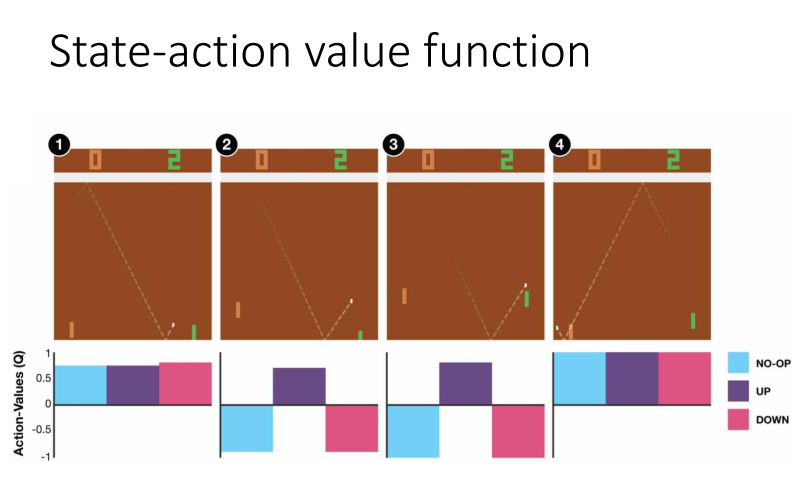
我们可以评估,在当前状态s,采取行动a,在接下来的游戏中获得得奖励累计和的期望为Q(s,a)。但在接下来的游戏中,
不一定采取行动a,而是采取Q值最大的行动。

下图中1,无论采取那个行动都无所谓,因为离球还很远,而图2离球比较近了,我们需要向上接到球,接下来游戏才能获得奖励。
3 怎么用
我们利用PI去与环境互动,得到一些互动数据,通过TDorMC的方法去更新Q(s,a)的参数,
根据更新后的Q,我们选择一个更好的pi_new,然后把pi更新为pi_new,再去与环境互动。
tips:pi_new 是完全取决于Q,没有新参数。

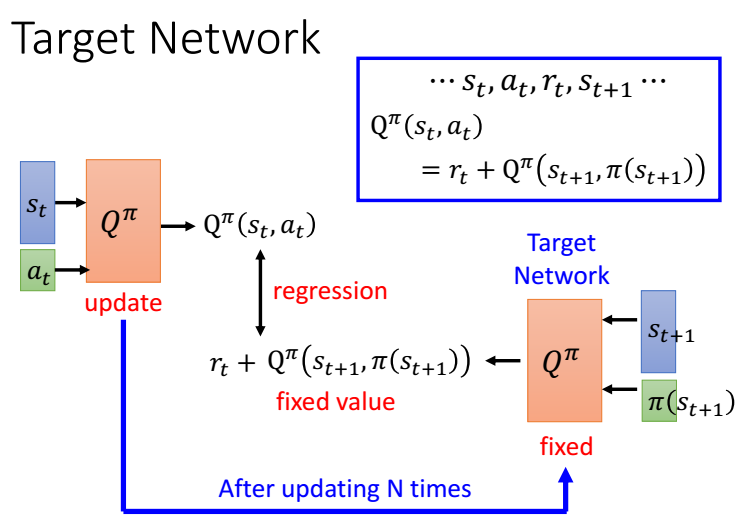
3.1 target network
3.2 Epsilon Greedy
如果我们只选择Q值最大的action,如果碰巧其他的action没有被采样到,这样其他的action将更不会被选择,
并不是他们不好,所以需要打破这种循环,我们以一定的几率选择Q最大的,还有几率选择其他的action。

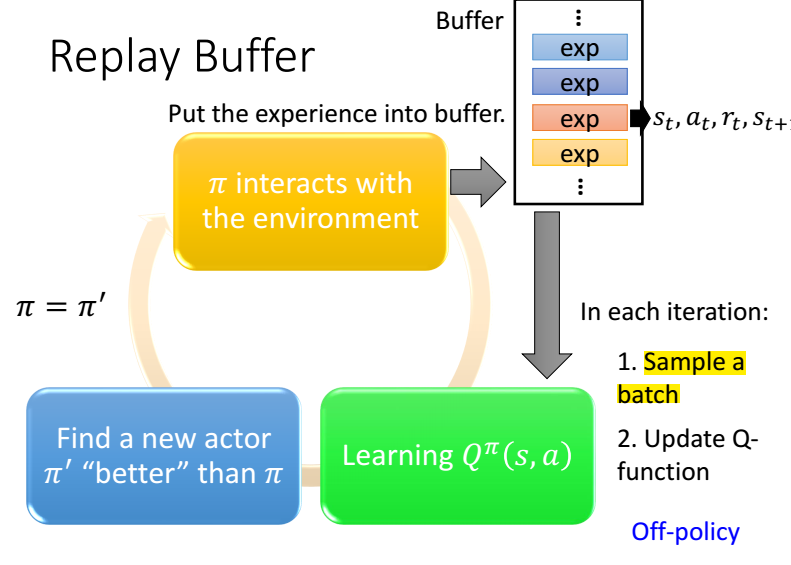
3.3 Replay Buffer
我们将历史数据存到Buffer里,然后训练的时候随机选一批,还要定期更新Buffer
3.4 完整算法

4 QLeaning 进阶
参考:
链接:https://www.zhihu.com/question/49787932/answer/124727629
https://www.youtube.com/watch?v=2-zGCx4iv_k&list=PLJV_el3uVTsODxQFgzMzPLa16h6B8kWM_&index=4
强化学习--QLearning的更多相关文章
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 强化学习-Q-Learning算法
1. 前言 Q-Learning算法也是时序差分算法的一种,和我们前面介绍的SARAS不同的是,SARSA算法遵从了交互序列,根据当前的真实行动进行价值估计:Q-Learning算法没有遵循交互序列, ...
- 深度学习之强化学习Q-Learning
1.知识点 """ 1.强化学习:学习系统没有像很多其他形式的机器学习方法一样被告知应该做什么行为, 必须在尝试之后才能发现哪些行为会导致奖励的最大化,当前的行为可能不仅 ...
- 强化学习——Q-learning算法
假设有这样的房间 如果将房间表示成点,然后用房间之间的连通关系表示成线,如下图所示: 这就是房间对应的图.我们首先将agent(机器人)处于任何一个位置,让他自己走动,直到走到5房 ...
- 强化学习-Q-learning学习笔记
Q学习动作探索策略中的ep-greepy,以ep的概率进行随机探索,以1-ep的概率以最大值策略进行开发,因为设定的迭代次数比较多,所以肯定存在一定的次数去搜索不同的动作. 1)Python版本 b站 ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- 强化学习之QLearning
注:以下第一段代码是 文章 提供的代码,但是简书的代码粘贴下来不换行,所以我在这里贴了一遍.其原理在原文中也说得很明白了. 算个旅行商问题 基本介绍 戳 代码解释与来源 代码整个计算过程使用的以下公式 ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
随机推荐
- 压缩维度oj P1173+P1174+P1164
今天在洛谷上刷dp,忽然冒出一道求最大字段和的问题,然后忘了瞬间忘了这是dp,几分钟一个贪心出来了成功ac,忽然想起自己在作dp,于是乖乖刷dp. 这个可能很多人都会但是今天有4种解法哦,本人只尝试了 ...
- LeetCode 566 Reshape the Matrix 解题报告
题目要求 In MATLAB, there is a very useful function called 'reshape', which can reshape a matrix into a ...
- LeetCode 893 Groups of Special-Equivalent Strings 解题报告
题目要求 You are given an array A of strings. Two strings S and T are special-equivalent if after any nu ...
- beego的https和http同时启用
2017/07/19 14:01:03 [I] [asm_amd64.s:2197] http server Running on http://:8080 2017/07/19 14:01:03 [ ...
- maven项目里jar包显示灰色
在spring boot项目加载Junit jar包之后,发现jar的颜色是灰色的,和其它的不一样. 带着好奇问了问身边的大神,大神解释说是因为pom文件里依赖项带上了<scope>tes ...
- CSS 优先级&伪元素&伪类
优先级 单冒号(:)用于CSS3伪类,双冒号(::)用于CSS3伪元素 伪元素 属性 描述 CSS :first-letter 向文本的第一个字母添加特殊样式 1 :first-line 向文本的首行 ...
- dedecms怎样调用指定id文章?
前面我们聊了帝国cms如何调用指定id的文章到首页,作为同行的织梦cms应该也是可以实现的吧?那么,dedecms怎样调用指定id文章呢?使用idlist直接调用指定的ID这样的方法是比较好的.官方给 ...
- cxf简单例子
cxf 这里介绍在web跟非web中的发布以及调用 准备条件: 1,导入cxf的相关jar包,以maven项目为例 pom的配置文件为 <project xmlns="http://m ...
- vue中mixins的使用
与vuex的区别 经过上面的例子之后,他们之间的区别应该很明显了哈~ vuex:用来做状态管理的,里面定义的变量在每个组件中均可以使用和修改,在任一组件中修改此变量的值之后,其他组件中此变量的值也会随 ...
- EOS account 中的 Threshold 和 weight 使用
https://eoscity.io/f/viewtopic.php?f=7&t=17 这篇文章的原文: (https://steemit.com/eos/@genereos/eos-mu ...