DataFrame.nunique(),DataFrame.count()
1. nunique()
DataFrame.nunique(axis = 0,dropna = True )
功能:计算请求轴上的不同观察结果
参数:
- axis : {0或'index',1或'columns'},默认为0。0或'index'用于行方式,1或'列'用于列方式。
- dropna : bool,默认为True,不要在计数中包含NaN。
返回: Series
>>> df = pd.DataFrame({'A': [1, 2, 3], 'B': [1, 1, 1]})
>>> df.nunique()
A 3
B 1
dtype: int64
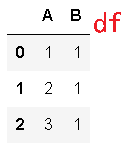
>>> df.nunique(axis=1)
0 1
1 2
2 2
dtype: int64
2. count()
DataFrame.count(axis = 0,level = None,numeric_only = False )
功能:计算每列或每行的非NA单元格。
None,NaN,NaT和numpy.inf都被视作NA
参数:
- axis : {0或'index',1或'columns'},默认为0(行),如果为每列生成0或'索引'计数。如果为每行生成1或'列'计数。
- level : int或str,可选,如果轴是MultiIndex(分层),则沿特定级别计数,折叠到DataFrame中。一个STR指定级别名称。
- numeric_only : boolean,默认为False,仅包含float,int或boolean数据。
返回:Series或DataFrame对于每个列/行,非NA / null条目的数量。如果指定了level,则返回DataFrame。
从字典构造DataFrame
>>> df = pd.DataFrame({"Person":
... ["John", "Myla", "Lewis", "John", "Myla"],
... "Age": [24., np.nan, 21., 33, 26],
... "Single": [False, True, True, True, False]})
>>> df
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False
注意不计数的NA值
>>> df.count()
Person 5
Age 4
Single 5
dtype: int64
每行计数:
>>> df.count(axis='columns')
0 3
1 2
2 3
3 3
4 3
dtype: int64
计算MultiIndex的一个级别:
>>> df.set_index(["Person", "Single"]).count(level="Person")
Age
Person
John 2
Lewis 1
Myla 1
参考文献:
DataFrame.nunique(),DataFrame.count()的更多相关文章
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- Pandas之Dataframe叠加,排序,统计,重新设置索引
Pandas之Dataframe索引,排序,统计,重新设置索引 一:叠加 import pandas as pd a_list = [df1,df2,df3] add_data = pd.concat ...
- pandas 的数据结构(Series, DataFrame)
Pandas 讲解 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas 纳入了大量库和一些标 ...
- 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的dataframe的操作方法
原网址 http://blog.sina.com.cn/s/blog_6bb07f83010152z0.html 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的d ...
- 5 pandas模块,DataFrame类
DataFrame DataFrame是一个[表格型]的数据结构,可以看作是[由Series组成的字典](共用同一个索引).DataFrame由一定顺序排列的多列数据组 ...
- 怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- python,pandas, DataFrame数据获取方式
一.创建DataFrame df=pd.DataFrame(np.arange(,).reshape(,)) my_col=dict(zip(range(),['A','B','C'])) df.re ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
随机推荐
- jquery <img> 图片懒加载 和 标签如果没有加载出图片或没有图片,就显示默认的图片
参考链接:http://www.jq22.com/jquery-info390 或压缩包下载地址:链接:http://pan.baidu.com/s/1hsj8ZWw 密码:4a7s 下面是没有 ...
- [No0000149]ReSharper操作指南6/16-编码协助之其他协助
语法高亮 ReSharper扩展了默认Visual Studio的符号高亮显示.此外,它还会使用可配置的颜色突出显示字段,局部变量,类型和其他标识符.例如,ReSharper语法突出显示允许您轻松区分 ...
- [No0000141]Outlook,设置全局已读回执
Outlook,设置全局已读回执 文件->选项
- [No0000F8]override和new的区别
override 1. override是派生类用来重写(或覆盖)基类中方法的: 2. override不能重写非虚方法和静态方法: 3. override只能重写用virtual.abstract. ...
- 关于Java的基础语法整理
- 两种Python基于OpenCV的固定位置半透明水印去除方案
1. 基于 inpaint 方法(网上的方法,处理质量较低) 算法理论:基于Telea在2004年提出的基于快速行进的修复算法(FMM算法),先处理待修复区域边缘上的像素点,然后层层向内推进,直到修复 ...
- linux命令瞎记录find xargs
1.创建多个文件 touch test{0..100}.txt 2.重定向 “>>” 追加重定向,追加内容,到文件的尾部 “>” 重定向,清除原文件里面所有内容,然后把内容追加到文件 ...
- 在计算机通信中,可靠交付应当由谁来负责?是网络还是端系统? 网络层协议 MAC帧、IP数据报、TCP报文 关系 IP地址与硬件地址 链路层与网络层
小结: 1. 网络层两种服务 虚电路服务 virtual circuit 电信网 网络层负责可靠交付 数据报服务 网络层不负责可靠交付 提供灵活的.无连接的.尽最大努力交付的数据报服务 不提供服务 ...
- python immutable and mutable
https://blog.csdn.net/hsuxu/article/details/7785835 python mutable as default parameter(NONONO) def ...
- Instruments之Leaks学习
前言: 本篇文章,在于学习,我把别人的一些感觉好的文章汇总成了一篇,亲自实现了一下,留用于今后学习资料. 文章脉络:文章脉络: 一.内存优化 简介:Objective_C 有3种内存管理方法, 它们分 ...