DataFrame.nunique(),DataFrame.count()
1. nunique()
DataFrame.nunique(axis = 0,dropna = True )
功能:计算请求轴上的不同观察结果
参数:
- axis : {0或'index',1或'columns'},默认为0。0或'index'用于行方式,1或'列'用于列方式。
- dropna : bool,默认为True,不要在计数中包含NaN。
返回: Series
>>> df = pd.DataFrame({'A': [1, 2, 3], 'B': [1, 1, 1]})
>>> df.nunique()
A 3
B 1
dtype: int64
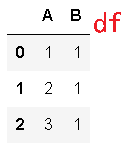
>>> df.nunique(axis=1)
0 1
1 2
2 2
dtype: int64
2. count()
DataFrame.count(axis = 0,level = None,numeric_only = False )
功能:计算每列或每行的非NA单元格。
None,NaN,NaT和numpy.inf都被视作NA
参数:
- axis : {0或'index',1或'columns'},默认为0(行),如果为每列生成0或'索引'计数。如果为每行生成1或'列'计数。
- level : int或str,可选,如果轴是MultiIndex(分层),则沿特定级别计数,折叠到DataFrame中。一个STR指定级别名称。
- numeric_only : boolean,默认为False,仅包含float,int或boolean数据。
返回:Series或DataFrame对于每个列/行,非NA / null条目的数量。如果指定了level,则返回DataFrame。
从字典构造DataFrame
>>> df = pd.DataFrame({"Person":
... ["John", "Myla", "Lewis", "John", "Myla"],
... "Age": [24., np.nan, 21., 33, 26],
... "Single": [False, True, True, True, False]})
>>> df
Person Age Single
0 John 24.0 False
1 Myla NaN True
2 Lewis 21.0 True
3 John 33.0 True
4 Myla 26.0 False
注意不计数的NA值
>>> df.count()
Person 5
Age 4
Single 5
dtype: int64
每行计数:
>>> df.count(axis='columns')
0 3
1 2
2 3
3 3
4 3
dtype: int64
计算MultiIndex的一个级别:
>>> df.set_index(["Person", "Single"]).count(level="Person")
Age
Person
John 2
Lewis 1
Myla 1
参考文献:
DataFrame.nunique(),DataFrame.count()的更多相关文章
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- Pandas之Dataframe叠加,排序,统计,重新设置索引
Pandas之Dataframe索引,排序,统计,重新设置索引 一:叠加 import pandas as pd a_list = [df1,df2,df3] add_data = pd.concat ...
- pandas 的数据结构(Series, DataFrame)
Pandas 讲解 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas 纳入了大量库和一些标 ...
- 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的dataframe的操作方法
原网址 http://blog.sina.com.cn/s/blog_6bb07f83010152z0.html 在使用R做数据挖掘时,最常用的数据结构莫过于dataframe了,下面列出几种常见的d ...
- 5 pandas模块,DataFrame类
DataFrame DataFrame是一个[表格型]的数据结构,可以看作是[由Series组成的字典](共用同一个索引).DataFrame由一定顺序排列的多列数据组 ...
- 怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- python,pandas, DataFrame数据获取方式
一.创建DataFrame df=pd.DataFrame(np.arange(,).reshape(,)) my_col=dict(zip(range(),['A','B','C'])) df.re ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
随机推荐
- ThinkPHP框架 做个简单表单 添加数据例子__ACTION__ __SELF__
public function zhuCe(){//自定义zhuCe方法和zhuCe显示表里的__ACTiON__这个相互交接 //实现两个逻辑 //1,显示注册页面 //2.向数据库添加内容 //自 ...
- day4 四、流程控制之if判断、while循环、for循环
一.if判断 1.语法一: if 条件: 条件成立时执行的子代码块 代码1 代码2 代码3 示例: sex='female' age= is_beautiful=True and age < a ...
- echarts pie 图表 显示的label 中内容 字体大小自定义
option = { tooltip: { trigger: 'item', formatter: "{a} <br/>{b}: {c} ({d}%)" }, lege ...
- Node.js编程规范
摘自:https://github.com/dead-horse/node-style-guide https://github.com/felixge/node-style-guide 2空格缩进 ...
- [No000013D].Net 项目代码风格参考
1. C#代码风格要求 1.1 注释 类型.属性.事件.方法.方法参数,根据需要添加注释. 如果类型.属性.事件.方法.方法参数的名称已经是自解释了,不需要加注释:否则需要添加注释. 当添加注释时,添 ...
- [No000012B]WPF(3/7)有趣的边框和画刷[译]
介绍 边框是每个WPF程序的主要构成块.在我现在的程序中,我使用了很多的边框来装饰界面.从把边框直接放到窗口中到把边框放到控件模板和列表项中,边框在创建一个好的应用界面上扮演了一个非常重要的角色.在这 ...
- nginx之fastcgi和PHP的PHP-FPM
php-fpm:PHP fastcgi进程管理器 php-fpm的工作模式:1个master进程.多个worker进程(在PHP中worker进程就是php-cgi进程),php-cgi是PHP的解释 ...
- cocos2dx 常用的构建工具
理编辑工具Physics Editing ToolsMekanimo 网址:http://www.mekanimo.net/PhysicsBench 网址:http://www.cocos2d-iph ...
- delphi 把数据库图片的存取
procedure TForm1.Button1Click(Sender: TObject); // 插入图片过程 var Stream:TMemoryStream;begin try Stream ...
- AndroidsStudio_找Bug
新版本不再提供Android Monitor,但在Logcat中可以找到运行日志,但在Regex中要勾选Show only... 另外设置一个控件记得加id.