spark基础---->spark的第一个程序
这里面我们介绍一下spark的安装,并通过一个python的例子来简单的体会一下spark的使用。
spark的安装与使用
安装环境:mac 10.13.6,spark版本:2.3.1,python版本:3.6.5
一、在mac上面安装spark和pyspark,可以使用brew包管理器安装。直接运行命令
> brew install apache-spark
> pip install pyspark
二、通过start-master启动我们的集群
> ./start-master.sh

然后我们访问:http://localhost:8080/,就可以看到集群相关的信息。
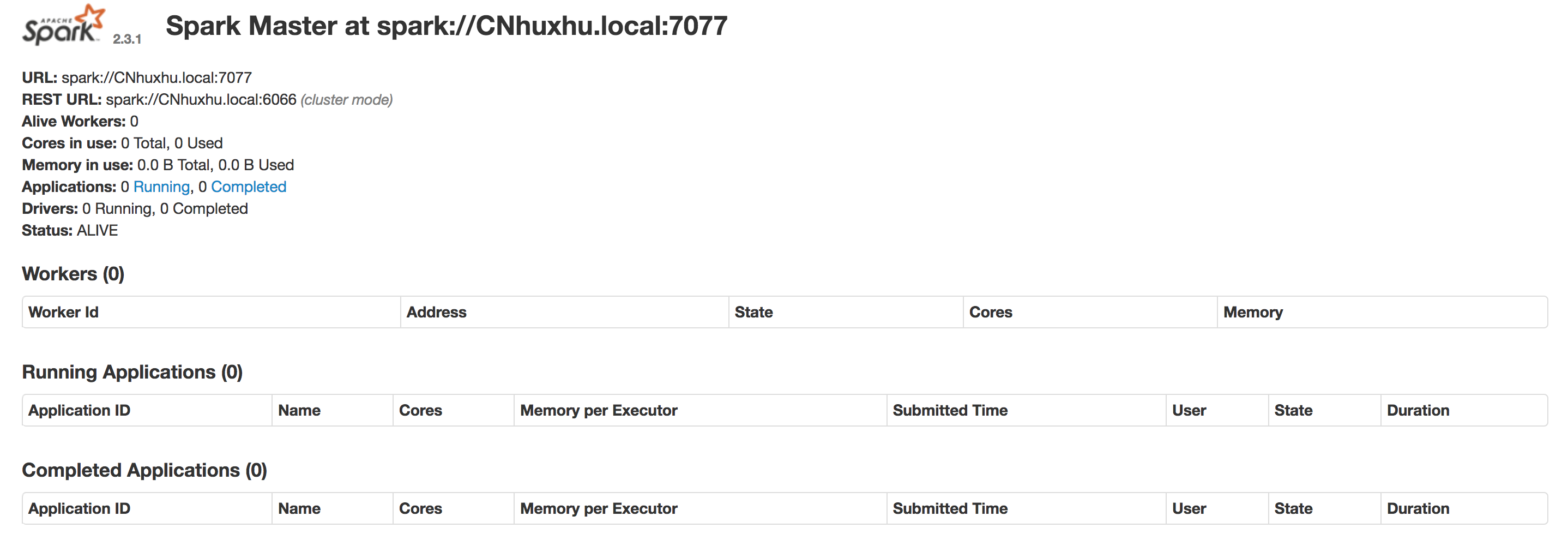
三、启动我们的worker。
> ./start-slave.sh spark://CNhuxhu.local:7077

再次访问http://localhost:8080/,可以在workers里面看到我们启动的worker信息。

四、编写我们的第一个spark的python程序
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("FirstApp").setMaster("spark://CNhuxhu.local:7077")
sc = SparkContext(conf=conf)
lines = sc.textFile('/usr/local/Cellar/apache-spark/2.3.1/README.md')
print('counts = ', lines.count())
五、提交到spark中处理
spark-submit --master local[4] simpleSpark.py
可以在控制台看到如下的打印信息:
counts = 103
程序中遇到的一些问题
一、运行程序报以下的错误
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
这是由于我们的mac本地安装的java版本有jdk8和jdk10,但是默认的是jdk10。spark2.3.1要求的jdk版本是1.8,所以修改系统的jdk版本问题解决。vim ~/.zshrc,添加以下内容
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_162.jdk/Contents/Home
二、查看系统安装jdk的java_home命令
usr/libexec/java_home -V
可以查看系统安装的所有java以及JAVA_HOME的信息
Matching Java Virtual Machines (2):
10.0.2, x86_64: "Java SE 10.0.2" /Library/Java/JavaVirtualMachines/jdk-10.0.2.jdk/Contents/Home
1.8.0_162, x86_64: "Java SE 8" /Library/Java/JavaVirtualMachines/jdk1.8.0_162.jdk/Contents/Home /Library/Java/JavaVirtualMachines/jdk-10.0.2.jdk/Contents/Home
三、以下是一个java版本的spark程序
项目是由maven构建的,在pom.xml添加所需的依赖。
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.1</version>
</dependency>
我们编写的java代码如下:
package com.linux.huhx; import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.SparkSession; /**
* user: huxhu
* date: 2018/8/11 3:40 PM
**/
public class SimpleSpark {
public static void main(String[] args) {
String logFile = "/usr/local/Cellar/apache-spark/2.3.1/README.md"; // Should be some file on your system
SparkSession spark = SparkSession.builder().appName("Simple Application").getOrCreate();
Dataset<String> logData = spark.read().textFile(logFile).cache(); long numAs = logData.filter(s -> s.contains("a")).count();
long numBs = logData.filter(s -> s.contains("b")).count(); System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs); spark.stop();
}
}
mvn package打包项目,在target目录下生成可执行的sparkLearn-1.0-SNAPSHOT.jar文件。最后执行spark-submit命令
spark-submit --class "com.linux.huhx.SimpleSpark" --master local[] target/sparkLearn-1.0-SNAPSHOT.jar
可以在控制台看到如下的日志打印
Lines with a: 61, lines with b: 30
友情链接
spark基础---->spark的第一个程序的更多相关文章
- Java 零基础跑起第一个程序
Java 零基础跑起第一个程序 一 概述 1 java代码编译 编译后才干在计算机中执行.编译就是把人能看懂的代码转换成机器能看懂的形式 2 java的长处 一次编译.到处执行.由于java代码是在 ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- C#基础知识-编写第一个程序(二)
通过上一篇数据类型已经介绍了C#中最基本的15种预定义数据类型,了解每一种类型代表的数据以及每种类型的取值范围,这是很重要也是最基本.下面我们通过实例来了解每个类型如何去使用.编写C#程序时我们需要用 ...
- Go基础---->go的第一个程序
今天我们学习搭建一个学习go语言的开发环境. Go语言 一.下载go 下载地址:https://golang.org/dl/ 校验下载,在命令行输入go version 二.编写第一个hello wo ...
- cocos2dx基础篇(2) 第一个程序
[本节内容] 1.程序的基本组成:CCSprite(精灵).CCLayer(层).CCScene(场景).CCDirector(导演) 2.分析HelloWorld源码. 一.基本组成 cocos2d ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark菜鸟学习营Day5 分布式程序开发
Spark菜鸟学习营Day5 分布式程序开发 这一章会和我们前面进行的需求分析进行呼应,完成程序的开发. 开发步骤 分布式系统开发是一个复杂的过程,对于复杂过程,我们需要分解为简单步骤的组合. 针对每 ...
- spark基础知识
1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架. dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopM ...
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
随机推荐
- solr中重建索引(转)
Stop your application server Change your schema.xml file Start your application server Delete the in ...
- 版本控制-git(二)
上次文章给大家介绍了Git的一些基本知识(http://www.cnblogs.com/jerehedu/p/4582398.html),并介绍了使用git init初始化化版本库,使用git add ...
- 如何将Revit明细表导出为Excel文档
Revit软件没有将明细表直接导出为Excel电子表格的功能,Revit只能将明细表导出为TXT格式,但是这种TXT文件用EXCEL处理软件打开然后另存为XLS格式即可,以Revit2013版自带的建 ...
- Kubernetes 编排系统
1.1 Kubernetes简介 1.1.1 什么是Kubernetes Kubernetes (通常称为K8s,K8s是将8个字母“ubernete”替换为“8”的缩写) 是用于自动部署.扩展和管理 ...
- 分布式文件系统---GlusterFS
1.1 分布式文件系统 1.1.1 什么是分布式文件系统 相对于本机端的文件系统而言,分布式文件系统(英语:Distributed file system, DFS),或是网络文件系统(英语:Netw ...
- Shell获取某目录下所有文件夹的名称
查看目录下面的所有文件: #!/bin/bash cd /目标目录 for file in $(ls *) do echo $file done 延伸的方法,查看目录下面的所有目录 #!/bin/ba ...
- Eclipse 个人使用配置
个人最喜欢使用的是eclipse,但是每次有新的版本或者是在不同的电脑上都要一遍一遍的配置.下面收集自己每次用eclipse需要注意配置的地方: 快捷键只需要修改一个code assitant 修改显 ...
- sublime python3中读取和写入文件时如何解决编码问题
# -*- coding: utf-8 -*- #分析用户身份审核信息 #python 3.5 #xiaodeng #http://apistore.baidu.com/apiworks/servic ...
- Atitit mysql数据库统计信息
Atitit mysql数据库统计信息 SELECT table_name, table_rows, index_length, data_length, auto_increment, create ...
- 按enter键触发登录事件
$(document).keydown(function(event){ if(event.keyCode==13){ $(".submit").click(); } });