论文阅读笔记(十六)【AAAI2018】:Region-Based Quality Estimation Network for Large-Scale Person Re-Identification
Introduction
(1)Motivation:
当前的行人重识别方法都只能在标准的数据集上取得好的效果,但当行人被遮挡或者肢体移动时,往往效果不佳。
(2)Contribution:
① 提出了一个基于区域的适应性质量估计网络(adaptive region-based quality estimation network,RQEN),包含了区域性特征提取模块和基于区域的质量预测模块。其旨在减小低质量图像区域的影响,利用序列中的区域互补。
② 提供了一个大规模的较整洁的数据集:Labeled Pedestrain in the Wild(LPW),包含了2731个行人,从3个不同场景拍摄,每个行人被2-4个相机捕获,共7694个tracklet、590000帧。该数据集囊括了孩童到老人、步行和快跑等不同的场景。
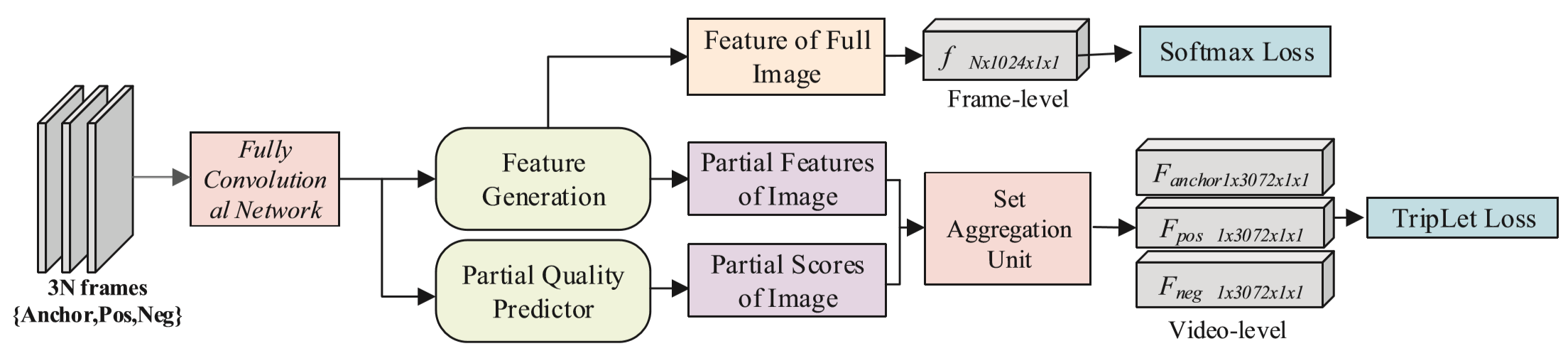
Proposed Method
输入:一个行人的图像序列 S = {I1, I2, ..., In}
区域特征提取模块:landmark detector标记行人身体的关键点 [Wei 2016. Convolutional pose machines.CVPR],middle representation按照关键点位置进行划分,然而由于分辨率低的原因,划分常常不够精确。采用的方法:按照关键点分布,将人体大致分为三个部分,定义 u、m、l 为上部、中部、下部区域,分别生成特征向量,即 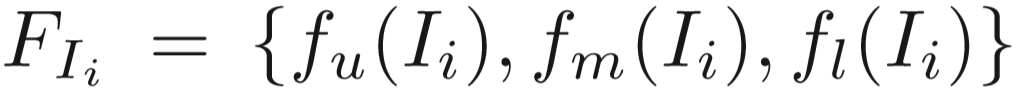 ,并进行平均池化。
,并进行平均池化。
质量预测模块:对区域特征生成质量估计 。
。
最终生成视频特征表示 Fw(S)。
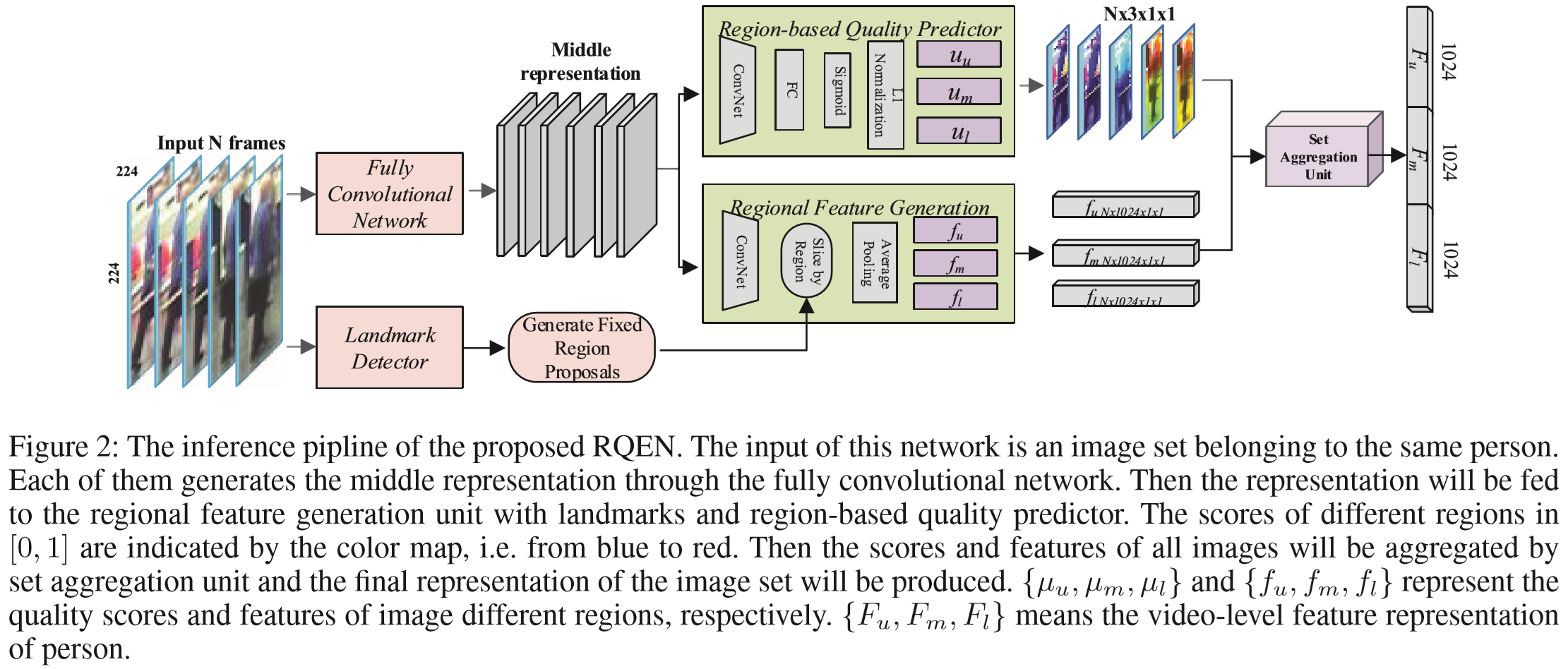
(1)区域生成策略:
令 Pi = {p1, p2, ..., pm} 为图像 Ii 的坐标(landmark)集合,m 为坐标点的数量(作者设置 m = 14),如图:

由于低分辨率和遮挡等影响,很多情况下坐标点很难被确定。
采用 k-means 聚类方法对三个集合进行聚类,聚类的设定为:S1P = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],S2P = [9, 10, 11, 12],S3P = [11, 12, 13, 14].
(2)区域质量预测:
middle representation 输入到卷积网络中,该网络包含卷积层和全连接层,输出的 orignial score μori(Ii) 对应了图片不同的区域,再通过sigmoid函数求出各区域的[0, 1]得分,视频序列不同帧中属于同一区域的得分进行正则化,得到最终结果。
(3)设置聚合单元:
一个图像集合 S = {I1, I2, ..., In},对于每帧图片,有不同的区域表征: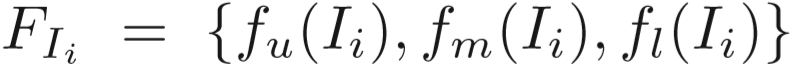 ,区域对应的质量评估得分为:
,区域对应的质量评估得分为: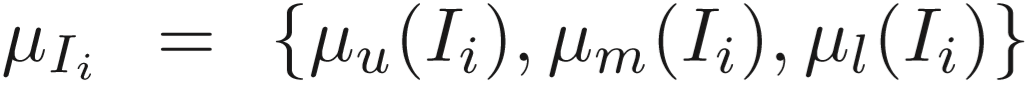 ,则生成的特征为:
,则生成的特征为: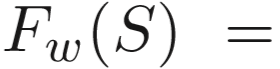
 ,其中:
,其中:
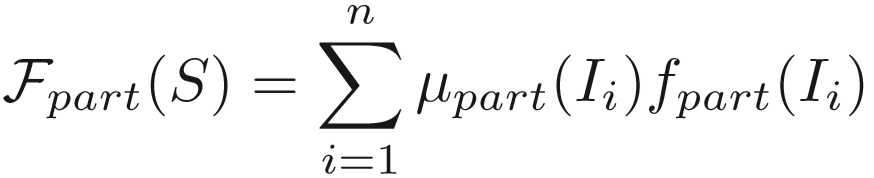
(4)联合训练帧级特征和视频级特征:
训练帧级特征是为了让同一视频内部更紧凑,训练视频级特征是为了让不同视频间更有区分度。

损失函数: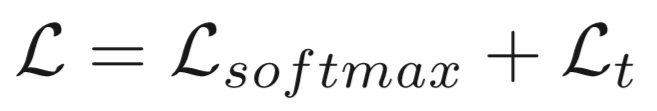
其中三元组损失函数为:
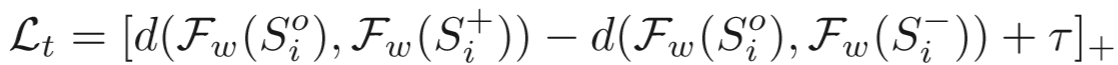
距离采用 L2-norm 距离。
在区域质量估计部分,T表示输入的数据,输出的 orignial score μori(Ii) 为:

再进行正则化:


Experiments
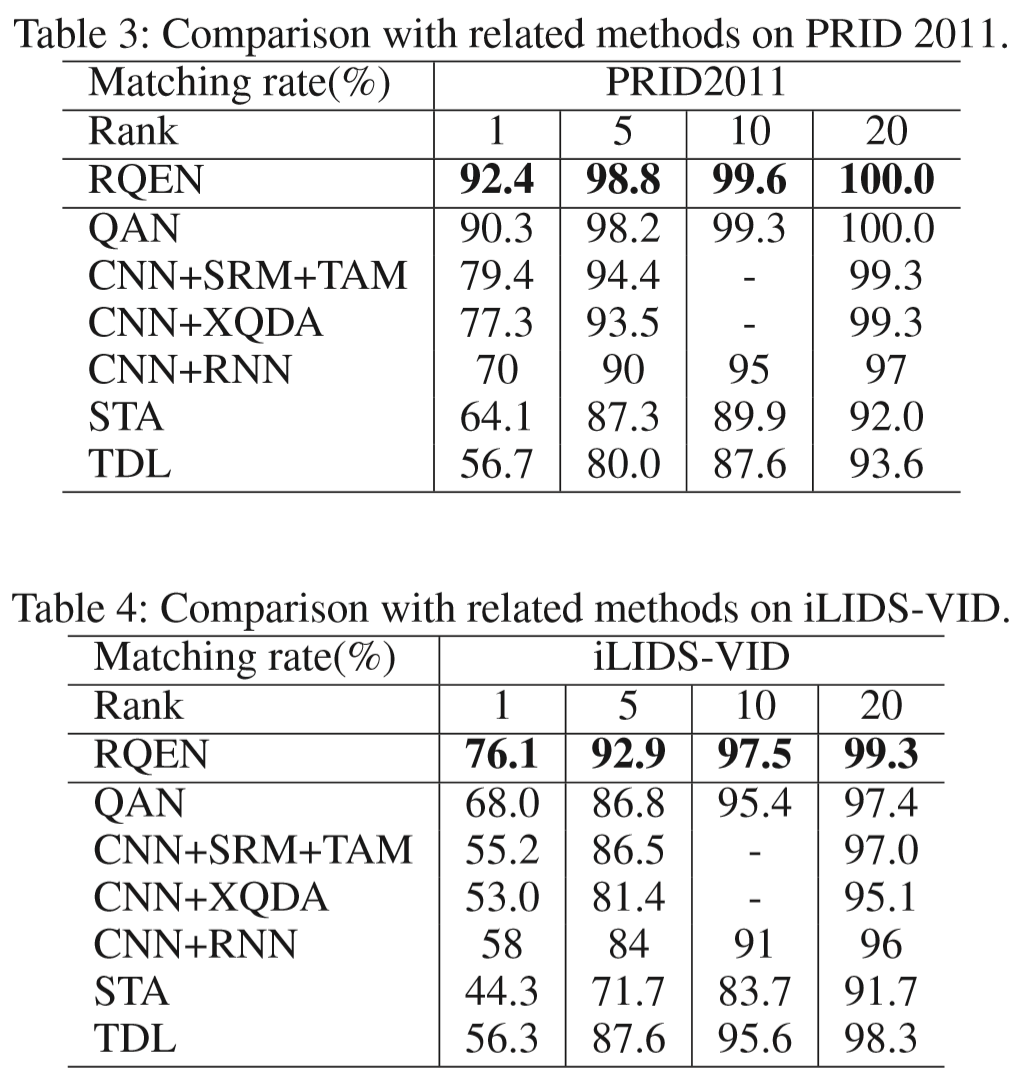
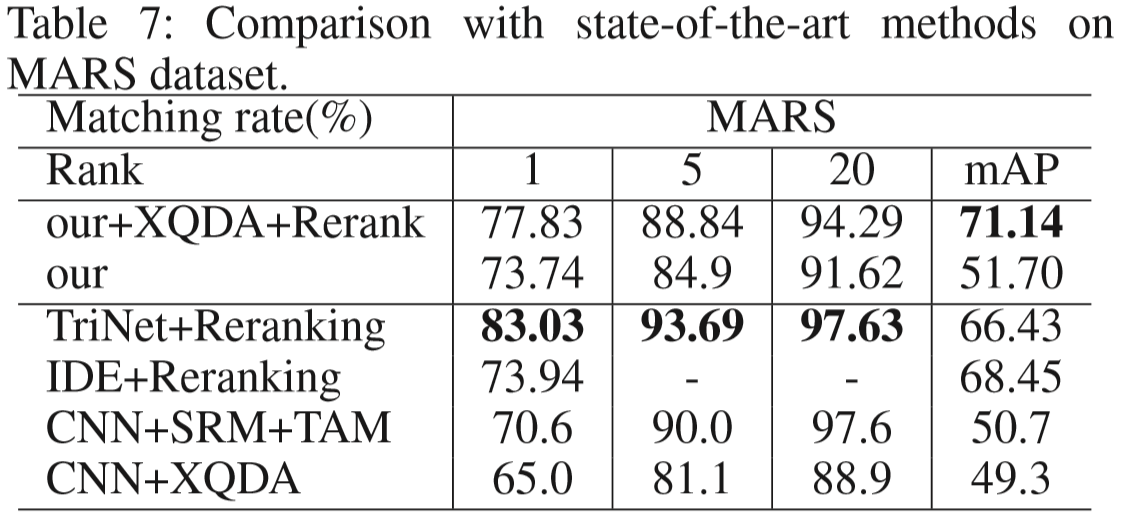
(1)数据集:PRID2011、iLIDS-VID、MARS、LPW
(2)实验结果:
(1)本方法分析:

method(a):GoogLeNet+batch norm(用ImageNet model初始化)[baseline]
method(b)(c)(d):+RU、+RM、+RL表示不同的区域特征
method(e):+QFix表示质量生成单元中设置所有质量得分为1,即消除质量得分的影响
method(f):+MP表示控制参数数量不变(作者提到在RQEN方法中参数会变多?这是为什么?)
(2)对比方法分析:


论文阅读笔记(十六)【AAAI2018】:Region-Based Quality Estimation Network for Large-Scale Person Re-Identification的更多相关文章
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)
论文链接:https://arxiv.org/abs/1802.02611 tensorflow 官方实现: https: //github.com/tensorflow/models/tree/ma ...
- 论文阅读笔记十:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (DeepLabv2)(CVPR2016)
论文链接:https://arxiv.org/pdf/1606.00915.pdf 摘要 该文主要对基于深度学习的分割任务做了三个贡献,(1)使用空洞卷积来进行上采样来进行密集的预测任务.空洞卷积可以 ...
- 论文阅读笔记(六)【TCSVT2018】:Semi-Supervised Cross-View Projection-Based Dictionary Learning for Video-Based Person Re-Identification
Introduction (1)Motivation: ① 现实场景中,给所有视频进行标记是一项繁琐和高成本的工作,而且随着监控相机的记录,视频信息会快速增多,因此需要采用半监督学习的方式,只对一部分 ...
- 云时代架构阅读笔记十六——Hystrix理解
背景 分布式系统环境下,服务间类似依赖非常常见,一个业务调用通常依赖多个基础服务.如下图,对于同步调用,当库存服务不可用时,商品服务请求线程被阻塞,当有大批量请求调用库存服务时,最终可能导致整个商品服 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
随机推荐
- VUE报表开发
因为在项目中经常开发一些报表,并且业务.逻辑其实都有大部分的重复部分. 所以将这些常用的模块抽象出来.并且可视化操作.封装成一款报表开发工具. 先看一下项目的一些效果:数据单项绑定 可视化操作: 数据 ...
- how to convert wstring to string
#define _CRT_SECURE_NO_WARNINGS #include <iostream> #include <string> #include <local ...
- python学习记录(八)
0910--https://www.cnblogs.com/fnng/archive/2013/04/28/3048356.html Python异常 Python用异常对象(exception ob ...
- A simple way to monitor SQL server SQL performance.
This is all begins from a mail. ... Dear sir: This is liulei. Thanks for your help about last PM for ...
- 排查 Kubernetes HPA 通过 Prometheus 获取不到 http_requests 指标的问题
部署好了 kube-prometheus 与 k8s-prometheus-adapter (详见之前的博文 k8s 安装 prometheus 过程记录),使用下面的配置文件部署 HPA(Horiz ...
- HDU 1006 模拟
Tick and Tick Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- APP图标在线生成
在线生成安卓APP图标生成 图标在线 在线图标 安卓图标 生成图标 https://icon.wuruihong.com/ 在线png图片压缩 png压缩 https://compresspng.c ...
- File类和枚举
java.io.File类:文件和目录路径名的抽象表示形式 File类常见构造方法: File(String pathname):通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例. ...
- linux学习--1. 文件系统
文件目录结构 闲话篇: linux我也是最近才开始学,写随笔是为分享学习经验的同时也留着供自己以后来参考.因为linux一切皆文件的基本哲学思想.所以我决定从文件目录开始写. 正文: 首先linux文 ...
- C语言switch中case后跟随break语句
1.case后面的常量表达式实际上只起语句标号作用,而不起条件判断作用,即“只是开始执行处的入口标号”.因此,一旦与switch后面圆括号中表达式的值匹配,就从此标号处开始执行:而且执行完一个case ...