tensorflow数据集加载
本篇涉及的内容主要有小型常用的经典数据集的加载步骤,tensorflow提供了如下接口:keras.datasets、tf.data.Dataset.from_tensor_slices(shuffle、map、batch、repeat),涉及的数据集如下:boston housing、mnist/fashion mnist、cifar10/100、imdb
1.keras.datasets
通过该接口可以直接下载指定数据集。boston housing提供了和房价有关的一些因子(面积、居民来源等),mnist提供了手写数字的图片和对应label,fashion mnist提供了10种衣服的灰度图和对应label,cifar10/100是用来进行简单图像识别的数据集,分别包含10类物品和100类物品,imdb是一个类似于淘宝好评的数据集,即通过评语及其标注(好评或差评),来实现一个好评或差评的分类器。
注:通过该接口得到的数据集格式为numpy格式。
2.tf.data.Dataset.from_tensor_slices()
该方法可以用来进行数据的迭代,过程中可以直接将numpy格式转化为tensor格式,然后通过调用next(iter())方法实现迭代,使用示例如下:
# 加载数据集
(x,y),(x_test,y_test) = keras.datasets.mnist.load_data()
# 转化为tensor并实现迭代
db = tf.data.Dataset.from_tensor_slices(x_test)
# 打印迭代数据的shape
print(next(iter(db)).shape)
# 将img和label封装为同一次迭代
db = tf.data.Dataset.from_tensor_slices((x_test,y_test))
print(next(iter(db))[0].shape)
print(next(iter(db))[1].shape)
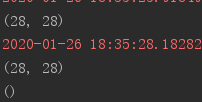
3.shuffle
通过shuffle函数可以将数据集打散,从而提高模型的泛化能力,使用方法:db.shuffle(10000),参数设置范围,通常值设置比较大
4.map
# deep learning一般使用float32,而numpy格式多为float64,所以需要转化
def preprocess(x,y):
x = tf.cast(x,dtype=tf.float32)/255
y = tf.cast(y,dtype=tf.int32)
y = tf.one_hot(y,depth=10)
return x,y db2 = db.map(preprocess)
res = next(iter(db2))
print(res[0].shape,res[1].shape)

5.batch
db3 = db2.batch(32)
res = next(iter(db3))
print(res[0].shape,res[1].shape)

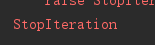
6.StopIteration
因为迭代多次后会到达数据集的末尾,如果不进行异常处理则会报StopIteration异常,如下处理方式就是错误的:
db_iter = iter(db3)
while True:
next(db_iter)
只要加上异常处理语句对db_iter重新赋值即可
tensorflow数据集加载的更多相关文章
- OFRecord 数据集加载
OFRecord 数据集加载 在数据输入一文中知道了使用 DataLoader 及相关算子加载数据,往往效率更高,并且学习了如何使用 DataLoader 及相关算子. 在 OFrecord 数据格式 ...
- 什么是pytorch(4.数据集加载和处理)(翻译)
数据集加载和处理 这里主要涉及两个包:torchvision.datasets 和torch.utils.data.Dataset 和DataLoader torchvision.datasets是一 ...
- tensorflow数据加载、模型训练及预测
数据集 DNN 依赖于大量的数据.可以收集或生成数据,也可以使用可用的标准数据集.TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用:本教程中用来训练建立模型的一些数据集介绍 ...
- Windows下pycharm远程连接服务器调试-tensorflow无法加载问题
最近打算在win系统下使用pycharm开发程序,并远程连接服务器调试程序,其中在import tensorflow时报错如图所示(在远程服务器中执行程序正常): 直观错误为: ImportError ...
- Tensorflow模型加载与保存、Tensorboard简单使用
先上代码: from __future__ import absolute_import from __future__ import division from __future__ import ...
- tensorflow学习笔记2:c++程序静态链接tensorflow库加载模型文件
首先需要搞定tensorflow c++库,搜了一遍没有找到现成的包,于是下载tensorflow的源码开始编译: tensorflow的contrib中有一个makefile项目,极大的简化的接下来 ...
- TensorFlow模型加载与保存
我们经常遇到训练时间很长,使用起来就是Weight和Bias.那么如何将训练和测试分开操作呢? TF给出了模型的加载与保存操作,看了网上都是很简单的使用了一下,这里给出一个神经网络的小程序去测试. 本 ...
- Tensorflow同时加载使用多个模型
在Tensorflow中,所有操作对象都包装到相应的Session中的,所以想要使用不同的模型就需要将这些模型加载到不同的Session中并在使用的时候申明是哪个Session,从而避免由于Sessi ...
- PIE SDK 多数据源的复合数据集加载
1. 功能简介 GIS遥感图像数据复合是将多种遥感图像数据融合成一种新的图像数据的技术,是目前遥感应用分析的前沿,PIESDK通过复合数据技术可以将多幅幅影像数据集(多光谱和全色数据)组合成一幅多波段 ...
随机推荐
- 如何在git搭建自己博客
1.安装Node.js和配置好Node.js环境,打开cmd命令行输入:node v.2.安装Git和配置好Git环境,打开cmd命令行输入:git --version.3.Github账户注册和新建 ...
- ls-remote -h -t git://github.com/adobe-webplatform/eve.git
npm WARN deprecated bfj-node4@5.3.1: Switch to the `bfj` package for fixes and new features! npm WAR ...
- TCP三次握手四次挥手过程梳理
1. 数据传输的大致示意图 1.1 TCP数据报文首部内部 1.2 TCP连接的几种状态说明 即命令 netstat 结果中的所有状态: 2. TCP连接建立的全过程 2.1 TCP三次握手建立TCP ...
- 杭电-------2047阿牛的eof牛肉串(C语言写)
/* 主要看最后一个是否为O,若为O,则倒数第二个不能为O,则为a[n-2]*1*2; 若不为O,则最后一个有两个选择则为a[n-1]*2 */ #include<stdio.h> ] = ...
- Linux部署.NetCore站点 使用Supervisor进行托管部署
前言 之前终于在Linux上部署好了.NetCore站点,但是这个站点非常“脆弱”.当我的ssh连接关闭或者我想在当前连接执行其他命令时候就必须关闭dotnet站点的执行程序.这显然不是我想要达到的效 ...
- html基本介绍,了解html与css,html语法和结构
一般来说,制作自己第一个网页通常书写的文字是"hello world!你好,全世界",代码如下展示: <!DOCTYPE html> <html lang=&qu ...
- 了解JavaScript的语法基础,值和变量
通过JavaScript语法基础学习了解到1.怎么使用js/*通常js的引入和css一样,分为内部,外部和行内引入,执行自上而下,有着先后顺序*/:2.js的语法/*2.1js是用字母,数字.特殊字符 ...
- VSCode 完美整合前后端框架(angular2+.NET core)
首先打开命令行查看本地.NET版本. 通过命令行安装模板. dotnet new --install Microsoft.AspNetCore.SpaTemplates::* 创建demo目录,并用v ...
- c++输入输出,保留几位小数
#include <iomanip> //头文件 //第一种写法 cout<<setiosflags(ios::); //第二种写法 cout.setf(ios::fixed) ...
- Expert C Programming(C专家编程) 读书笔记
目录 几个比较奇葩的指针赋值 int (* fun())() int (* foo())[] int (*foo[])() const 关键词的意义是什么? char const (*next )() ...