Graph Regularized Feature Selection with Data Reconstruction
Abstract
• 从图正则数据重构方面处理无监督特征选择;
• 模型的思想是所选特征不仅通过图正则保留了原始数据的局部结构,也通过线性组合重构了每个数据点;
• 所以重构误差成为判断所选特征质量的自然标准。
• 通过最小化重构误差,选择最好保留相似性和判别信息的特征;
1 Introduction
• 目前有两大类无监督特征选择算法:Similarity preserving 和 clustering performance maximization;Similarity preserving 算法选择最好保留原始数据的局部结构的代表性特征。例如,如果数据点在原始空间分布很近,那么在选择的特征上也应该分布很近;clustering performance maximization 选择能最大化某个聚类标准的判别特征。例如,引入伪标签选择最大化数据聚类效果的判别特征。
• 模型的目标是选择能同时最好保留数据在原始空间的局部结构和判别信息的特征。
• highlight:
(1)从图正则数据重构的角度考虑无监督特征选择问题。通过最小化图正则重构误差,我们选择了最好保留数据结构和判别信息的特征;
(2)通过在混合目标函数上的稀疏学习考虑特征选择问题。引入了一个 l1-norm 稀疏项作用于特征选择矩阵,特征选择矩阵的稀疏性减少了冗余和噪声特征;
(3)提出了一个迭代梯度算法。
2 Related Work
2.1 Similarity Preserving Based Feature Selection
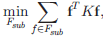
f 是特征向量,K 是预先定义的 Affinity 矩阵。因此,与流形结构相一致的特征被认为是重要的。
2.2 Clustering Based Feature Selection
clustering based feature selection 目标是选择判别特征
3 The Problem Of Graph Regularized Feature Selection With Data Reconstruction
进行了一些符号说明
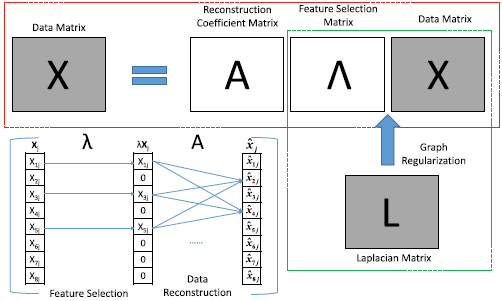
特征选择矩阵的学习同时保留了数据重构过程和图正则化过程。
4 The Objective Function
• 我们希望原始数据在所选特征上有一个紧致的表示,即 信息损失最小以及数据的局部结构也得到保留;
• 从所选特征上重构原始数据第 i 维的信息损失表示为:
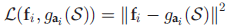
全局数据重构误差为:
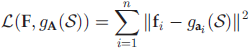
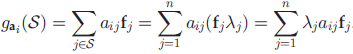
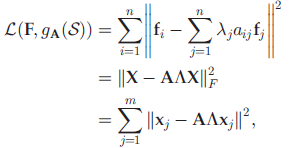 • 进一步,局部不变性。如果两个数据点在原始空间距离相近,那么在所选特征的投影上距离也相近。
• 进一步,局部不变性。如果两个数据点在原始空间距离相近,那么在所选特征的投影上距离也相近。
通过最小化下式,保留数据在所选特征上的局部几何信息:
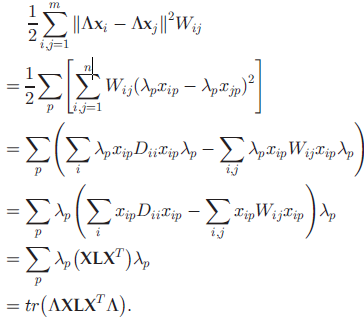
• 模型为:
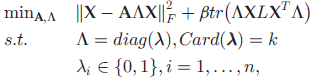
但是上述模型难以求解,需要分支定界法。于是将约束放松
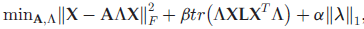
beta 是平衡对判别信息和相似性的保留。当 beta 较大时,保留相似性。当 beta 较小时,保留判别信息;alpha 控制所选特征的数目。
5 The Optimization
6 Experiment Results
7 Conclusion
判别信息通过最小化数据重构误差保留,相似性通过图正则保留。
Graph Regularized Feature Selection with Data Reconstruction的更多相关文章
- 【转】[特征选择] An Introduction to Feature Selection 翻译
中文原文链接:http://www.cnblogs.com/AHappyCat/p/5318042.html 英文原文链接: An Introduction to Feature Selection ...
- 单因素特征选择--Univariate Feature Selection
An example showing univariate feature selection. Noisy (non informative) features are added to the i ...
- Feature Selection Can Reduce Overfitting And RF Show Feature Importance
一.特征选择可以减少过拟合代码实例 该实例来自机器学习实战第四章 #coding=utf-8 ''' We use KNN to show that feature selection maybe r ...
- highly variable gene | 高变异基因的选择 | feature selection | 特征选择
在做单细胞的时候,有很多基因属于noise,就是变化没有规律,或者无显著变化的基因.在后续分析之前,我们需要把它们去掉. 以下是一种找出highly variable gene的方法: The fea ...
- 机器学习-特征选择 Feature Selection 研究报告
原文:http://www.cnblogs.com/xbinworld/archive/2012/11/27/2791504.html 机器学习-特征选择 Feature Selection 研究报告 ...
- the steps that may be taken to solve a feature selection problem:特征选择的步骤
參考:JMLR的paper<an introduction to variable and feature selection> we summarize the steps that m ...
- The Practical Importance of Feature Selection(变量筛选重要性)
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- [Feature] Feature selection
Ref: 1.13. Feature selection Ref: 1.13. 特征选择(Feature selection) 大纲列表 3.1 Filter 3.1.1 方差选择法 3.1.2 相关 ...
- [Feature] Feature selection - Embedded topic
基于惩罚项的特征选择法 一.直接对特征筛选 Ref: 1.13.4. 使用SelectFromModel选择特征(Feature selection using SelectFromModel) 通过 ...
随机推荐
- 本地与github建立连接,本地代码上传到github
1,已有github账号 2,本地已经安装git 3,本地创建ssh-key 在git bash中输入后直接回车. $ ssh-keygen -t rsa -C "your_email@yo ...
- 01、Git安装教程(windows)
首先如下图:(点击next) 第二步:文件位置存储,可根据自己盘的情况安装 第三步:安装配置文件,自己需要的都选上,下一步 第四步:不创建启动文件夹,下一步: 第五步:选择默认的编辑器,我们直接用推荐 ...
- jni和线程
JNI官方规范中文版——在程序中集成JVM需要注意的JNI特征 翻译 我们已经讨论了JNI在写本地代码和向本地应用程序中集成JVM时的特征.本章接下来的部分分介绍其它的JNI特征. 8.1 JNI和线 ...
- Elasticsearch编程操作
1.创建工程导入依赖 <dependency> <groupId>org.elasticsearch</groupId> <artifactId>ela ...
- ts中基本数据类型(上)
/* 定义数组*/ var arr: number[] = [1, 2, 3]; var arr1: Array<number> = [1, 2, 3]; var arr2: [str ...
- MySQL 8 复制
MySQL 8.0 支持的复制方法: 传统方法(基于二进制日志文件位置) 新方法(基于GTID) MySQL 8.0 支持的同步类型: 异步复制(内置) 同步复制(NDB集群) 半同步复制(半同步复制 ...
- kali linux 渗透入门之基础准备-Burp Suite 代理设置
一:安装火狐浏览器-插件与设置中文 打开浏览器,复制粘贴这条url: https://addons.mozilla.org/en-US/firefox/addon/chinese-simplified ...
- 【Git】git使用 - 冲突conflict的解决演示
冲突的解决 (如果git使用不熟练)建议在push不了时,pull之前.在本地创建一个新的分支并commit到local,以保证本地有commit记录,万一出什么问题,可以找回代码,以免代码丢失. ( ...
- 浅谈python的第三方库——pandas(一)
pandas作为python进行数据分析的常用第三方库,它是基于numpy创建的,使得运用numpy的程序也能更好地使用pandas. 1 pandas数据结构 1.1 Series 注:由于pand ...
- 浅谈python的第三方库——numpy(三)
numpy库中矩阵的常用方法 1 矩阵转置 从上图可以看出:使用方法a.T可以将矩阵a转置. 2 均值与方差 注意:方法a.mean()会对矩阵a的所有元素求均值,a.var()也是考虑矩阵a的所有元 ...