Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:缓存、Checkpoint
4. 缓存
缓存的意义
缓存相关的 API
缓存级别以及最佳实践
4.1. 缓存的意义
- 使用缓存的原因 - 多次使用 RDD
-
需求: 在日志文件中找到访问次数最少的 IP 和访问次数最多的 IP
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg) val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()这是一个 Shuffle 操作, Shuffle 操作会在集群内进行数据拷贝 在上述代码中, 多次使用到了
interimRDD, 导致文件读取两次, 计算两次, 有没有什么办法增进上述代码的性能? - 使用缓存的原因 - 容错
-

当在计算 RDD3 的时候如果出错了, 会怎么进行容错?
会再次计算 RDD1 和 RDD2 的整个链条, 假设 RDD1 和 RDD2 是通过比较昂贵的操作得来的, 有没有什么办法减少这种开销?
上述两个问题的解决方案其实都是 缓存, 除此之外, 使用缓存的理由还有很多, 但是总结一句, 就是缓存能够帮助开发者在进行一些昂贵操作后, 将其结果保存下来, 以便下次使用无需再次执行, 缓存能够显著的提升性能.
所以, 缓存适合在一个 RDD 需要重复多次利用, 并且还不是特别大的情况下使用, 例如迭代计算等场景.
4.2. 缓存相关的 API
- 可以使用
cache方法进行缓存 -
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.cache() val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()缓存 方法签名如下
cache(): this.type = persist()cache 方法其实是
persist方法的一个别名
- 也可以使用 persist 方法进行缓存
-
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist(StorageLevel.MEMORY_ONLY) val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()缓存 方法签名如下
persist(): this.type
persist(newLevel: StorageLevel): this.typepersist方法其实有两种形式,persist()是persist(newLevel: StorageLevel)的一个别名,persist(newLevel: StorageLevel)能够指定缓存的级别
- 缓存其实是一种空间换时间的做法, 会占用额外的存储资源, 如何清理?
-
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf) val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist() interimRDD.unpersist() val resultLess = interimRDD.sortBy(item => item._2, ascending = true).first()
val resultMore = interimRDD.sortBy(item => item._2, ascending = false).first() println(s"出现次数最少的 IP : $resultLess, 出现次数最多的 IP : $resultMore") sc.stop()清理缓存 根据缓存级别的不同, 缓存存储的位置也不同, 但是使用
unpersist可以指定删除 RDD 对应的缓存信息, 并指定缓存级别为NONE
4.3. 缓存级别
其实如何缓存是一个技术活, 有很多细节需要思考, 如下
是否使用磁盘缓存?
是否使用内存缓存?
是否使用堆外内存?
缓存前是否先序列化?
是否需要有副本?
如果要回答这些信息的话, 可以先查看一下 RDD 的缓存级别对象
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.persist()
println(interimRDD.getStorageLevel)
sc.stop()打印出来的对象是 StorageLevel, 其中有如下几个构造参数

根据这几个参数的不同, StorageLevel 有如下几个枚举对象
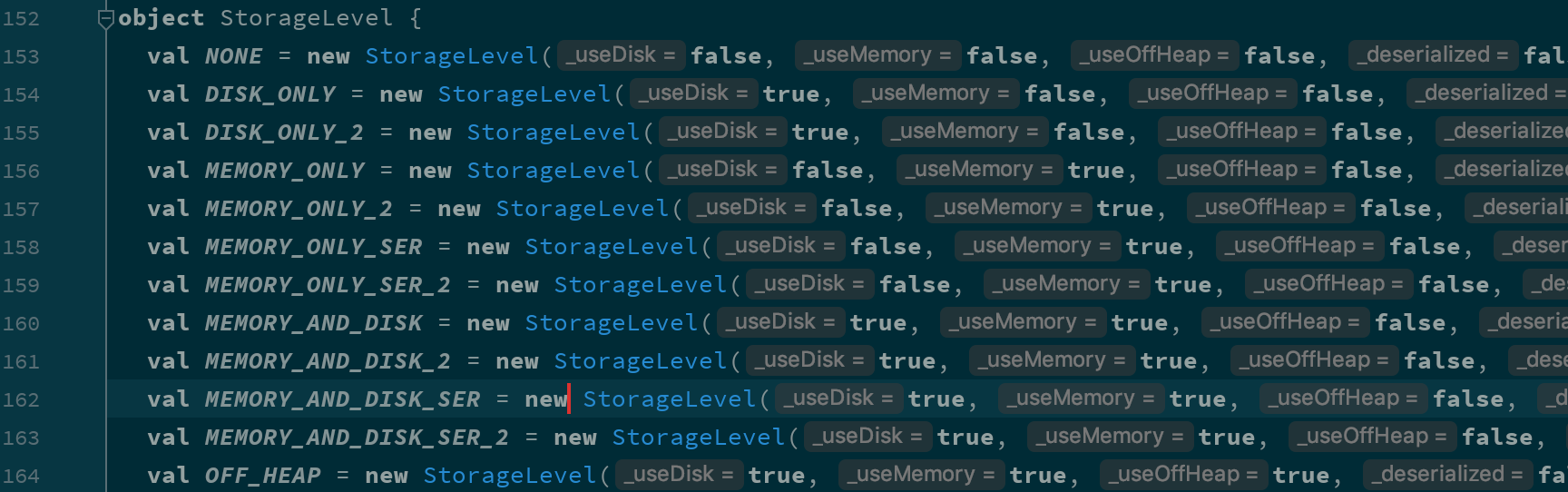
| 缓存级别 | userDisk 是否使用磁盘 |
useMemory 是否使用内存 |
useOffHeap 是否使用堆外内存 |
deserialized是否以反序列化形式存储 |
replication 副本数 |
|---|---|---|---|---|---|
|
|
false |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
1 |
|
|
true |
false |
false |
false |
2 |
|
|
false |
true |
false |
true |
1 |
|
|
false |
true |
false |
true |
2 |
|
|
false |
true |
false |
false |
1 |
|
|
false |
true |
false |
false |
2 |
|
|
true |
true |
false |
true |
1 |
|
|
true |
true |
false |
true |
2 |
|
|
true |
true |
false |
false |
1 |
|
|
true |
true |
false |
false |
2 |
|
|
true |
true |
true |
false |
1 |
Spark 的存储级别的选择,核心问题是在 memory 内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择:
如果您的 RDD 适合于默认存储级别(MEMORY_ONLY),leave them that way。这是 CPU 效率最高的选项,允许 RDD 上的操作尽可能快地运行.
如果不是,试着使用 MEMORY_ONLY_SER 和 selecting a fast serialization library 以使对象更加节省空间,但仍然能够快速访问。(Java和Scala)
不要溢出到磁盘,除非计算您的数据集的函数是昂贵的,或者它们过滤大量的数据。否则,重新计算分区可能与从磁盘读取分区一样快.
如果需要快速故障恢复,请使用复制的存储级别(例如,如果使用 Spark 来服务 来自网络应用程序的请求)。All 存储级别通过重新计算丢失的数据来提供完整的容错能力,但复制的数据可让您继续在 RDD 上运行任务,而无需等待重新计算一个丢失的分区.
5. Checkpoint
Checkpoint 的作用
Checkpoint 的使用
5.1. Checkpoint 的作用
Checkpoint 的主要作用是斩断 RDD 的依赖链, 并且将数据存储在可靠的存储引擎中, 例如支持分布式存储和副本机制的 HDFS.
- Checkpoint 的方式
-
可靠的 将数据存储在可靠的存储引擎中, 例如 HDFS
本地的 将数据存储在本地
- 什么是斩断依赖链
-
斩断依赖链是一个非常重要的操作, 接下来以 HDFS 的 NameNode 的原理来举例说明
HDFS 的 NameNode 中主要职责就是维护两个文件, 一个叫做
edits, 另外一个叫做fsimage.edits中主要存放EditLog,FsImage保存了当前系统中所有目录和文件的信息. 这个FsImage其实就是一个Checkpoint.HDFS 的 NameNode 维护这两个文件的主要过程是, 首先, 会由
fsimage文件记录当前系统某个时间点的完整数据, 自此之后的数据并不是时刻写入fsimage, 而是将操作记录存储在edits文件中. 其次, 在一定的触发条件下,edits会将自身合并进入fsimage. 最后生成新的fsimage文件,edits重置, 从新记录这次fsimage以后的操作日志.如果不合并
edits进入fsimage会怎样? 会导致edits中记录的日志过长, 容易出错.所以当 Spark 的一个 Job 执行流程过长的时候, 也需要这样的一个斩断依赖链的过程, 使得接下来的计算轻装上阵.
- Checkpoint 和 Cache 的区别
-
Cache 可以把 RDD 计算出来然后放在内存中, 但是 RDD 的依赖链(相当于 NameNode 中的 Edits 日志)是不能丢掉的, 因为这种缓存是不可靠的, 如果出现了一些错误(例如 Executor 宕机), 这个 RDD 的容错就只能通过回溯依赖链, 重放计算出来.
但是 Checkpoint 把结果保存在 HDFS 这类存储中, 就是可靠的了, 所以可以斩断依赖, 如果出错了, 则通过复制 HDFS 中的文件来实现容错.
所以他们的区别主要在以下两点
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中
Checkpoint 可以斩断 RDD 的依赖链, 而 Persist 和 Cache 不行
因为 CheckpointRDD 没有向上的依赖链, 所以程序结束后依然存在, 不会被删除. 而 Cache 和 Persist 会在程序结束后立刻被清除.
5.2. 使用 Checkpoint
val conf = new SparkConf().setMaster("local[6]").setAppName("debug_string")
val sc = new SparkContext(conf)
sc.setCheckpointDir("checkpoint")
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
interimRDD.checkpoint()
interimRDD.collect().foreach(println(_))
sc.stop()1)在使用 Checkpoint 之前需要先设置 Checkpoint 的存储路径, 而且如果任务在集群中运行的话,这个路径必须是 HDFS 上的路径
2)开启 Checkpoint
一个小细节:
val interimRDD = sc.textFile("dataset/access_log_sample.txt")
.map(item => (item.split(" ")(0), 1))
.filter(item => StringUtils.isNotBlank(item._1))
.reduceByKey((curr, agg) => curr + agg)
.cache()
interimRDD.checkpoint()
interimRDD.collect().foreach(println(_))
checkpoint 之前先 cache 一下, 准没错
应该在 checkpoint 之前先 cache 一下, 因为 checkpoint 会重新计算整个 RDD 的数据然后再存入 HDFS 等地方.
所以上述代码中如果 checkpoint 之前没有 cache, 则整个流程会被计算两次, 一次是 checkpoint, 另外一次是 collect。
Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:缓存、Checkpoint的更多相关文章
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:算子和分区
一.reduce和reduceByKey: 二.:RDD 的算子总结 RDD 的算子大部分都会生成一些专用的 RDD map, flatMap, filter 等算子会生成 MapPartitions ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- Update(Stage4):Spark原理_运行过程_高级特性
如何判断宽窄依赖: =================================== 6. Spark 底层逻辑 导读 从部署图了解 Spark 部署了什么, 有什么组件运行在集群中 通过对 W ...
- halcon基础算子介绍(窗口创建,算子运行时长,是否启用更新函数)
前言 halcon有有大约1500个算子,我总结一些简单大家用得到的算子,比如创建窗口的方式有3种,接下来结束这方式,及其异同点等! 1.窗口创建的三种方式 1.1使用dev_open_window算 ...
- Update(Stage4):spark_rdd算子:第1节 RDD_定义_转换算子:深入RDD
一. 二.案例:详见代码.针对案例提出的6个问题: 假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理? 放在集群中, 利用集群多台计算机来并行处理 如何放在集群中运行? 简单来讲, 并行 ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- Update(Stage4):sparksql:第1节 SparkSQL_使用场景_优化器_Dataset & 第2节 SparkSQL读写_hive_mysql_案例
目标 SparkSQL 是什么 SparkSQL 如何使用 Table of Contents 1. SparkSQL 是什么 1.1. SparkSQL 的出现契机 1.2. SparkSQL 的适 ...
- Update(Stage4):sparksql:第5节 SparkSQL_出租车利用率分析案例
目录: 1. 业务2. 流程分析3. 数据读取5. 数据清洗6. 行政区信息 6.1. 需求介绍 6.2. 工具介绍 6.3. 具体实现7. 会话统计 导读 本项目是 SparkSQL 阶段的练习项目 ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
随机推荐
- Web 安全工具篇:Burp Suite 使用指南
真的是一点都不过分,了解详情请继续往下读. Burp Suite 介绍 Burp Suite 是用于攻击 web 应用程序的集成平台.它包含了许多工具,并为这些工具设计了许多接口,以促进加快攻击应用程 ...
- 解决async 运行多线程时报错RuntimeError: There is no current event loop in thread 'Thread-2'
原来使用: loop = asyncio.get_event_loop()task = asyncio.ensure_future(do_work(checker))loop.run_until_co ...
- POJ 2018 Best Cow Fences(二分答案)
题目链接:http://poj.org/problem?id=2018 题目给了一些农场,每个农场有一定数量的奶牛,农场依次排列,问选择至少连续排列F个农场的序列,使这些农场的奶牛平均数量最大,求最大 ...
- Java - 集合 - Map
Map 1.Map实现类:HashMap.Hashtable.LinkedHashMap.TreeMap HashMap 新增元素/获取元素 1 void contextLoads() { 2 //声 ...
- opencv:二值图像的概念
灰度图像与二值图像 二值分割 #include <opencv2/opencv.hpp> #include <iostream> using namespace cv; usi ...
- 两台linux之间传输文件
scp传输 当两台LINUX主机之间要互传文件时可使用SCP命令来实现 scp传输速度较慢,但使用ssh通道保证了传输的安全性 复制文件 将本地文件拷贝到远程 scp local_file remot ...
- 【代码总结】Spring MVC数据校验
1.实验介绍 --------------------------------------------------------------------------------------------- ...
- 二次封装 Reponse,视图家族
复习 """ 1.整体修改与局部修改 # 序列化 ser_obj = ModelSerializer(model_obj) # 反序列化,save() => cre ...
- MSYS2与mingw32和mingw64的安装
由于编译OpenBLAS接触到MSYS2. 下载MSYS:https://mirror.tuna.tsinghua.edu.cn/help/msys2/ 安装,并按照下面的配置,然后可以安装mingw ...
- Ansible - 模块 - shell
概述 ansible 的 shell 模块 准别 ansible 控制节点 ansible 2.8.1 远程节点 OS CentOS 7.5 无密码登录 已经打通 1. 模块 概述 ansible 功 ...