unittest测试
标签(空格分隔): unittest
unittest介绍:
python里面也有单元测试框架-unittest,相当于是一个python版的junit。
一、unittest简介
1.先导入unittest,用help函数查看源码解析
python的单元测试框架,是像java的junit框架:
#!/usr/bin/env python
# coding=utf-8
import unittest
class InTestCase(unittest.TestCase):
def testAdd(self):
self.assertEqual((1+2),3)
self.assertEqual(0+1,1)
def testM(self):
self.assertEqual((0*10),0)
self.assertEqual((5*8),40)
if __name__ == '__main__':
unittest.main()
2.第一行是导入unittest这个模块
3.class这一行是定义一个测试的类,并继承unittest.TestCase这个类
4.接下来是定义了两个测试case名称:testAdd和testM
- 测试用例的名称要以test开头;
5.然后是断言assert,这里的断言方法是assertEqual-判断两个是否相等,这个断言可以是一个也可以是多个
最后的结果是:
..
----------------------------------------------------------------------
Ran 2 tests in 0.000s
OK
案例:
#!/usr/bin/env python
# coding=utf-8
import unittest
class InTestCase(unittest.TestCase):
def testMinus(self):
u'''这是测试减法'''
result = 6-5
hope=1
self.assertEqual(result,hope)
def testDivide(self):
u'''这里测试除法'''
result= 7/2
hope=3.5
self.assertEqual(result,hope)
if __name__ == '__main__':
unittest.main()
执行结果:
AssertionError: 3 != 3.5
前置和后置
1.setUp:在写测试用例的时候,每次操作其实都是基于打开浏览器输入对应网址这些操作,这个就是执行用例的前置条件。
2.tearDown:执行完用例后,为了不影响下一次用例的执行,一般有个数据还原的过程,这就是执行用例的后置条件。
3.前置和后置都是非必要的条件,如果没有也可以写pass
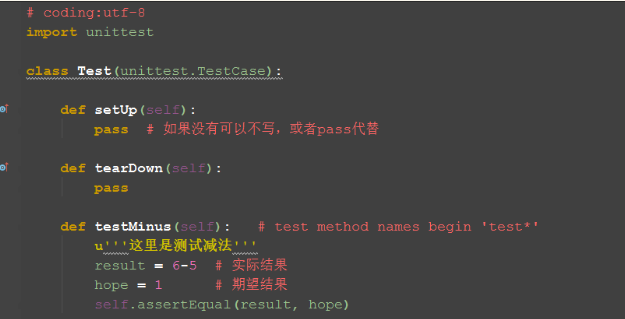
unittest的执行顺序:
例如:
#!/usr/bin/env python
# coding=utf-8
import unittest
import time
class Test(unittest.TestCase):
def setUp(self):
print("start!")
def tearDown(self):
time.sleep(1)
print("end!")
def test01(self):
print("执行测试用例01")
def test03(self):
print("执行测试用例03")
def test02(self):
print("执行测试用例02")
def addtest(self):
print("add方法")
执行结果:
start!
执行测试用例01
end!
start!
执行测试用例02
.end!
start!
执行测试用例03
..
end!
----------------------------------------------------------------------
Ran 3 tests in 3.002s
OK
先执行的前置setUp,然后执行的用例(test),最后执行的后置tearDown
测试用例(test)的执行顺序是根据01-02-03执行的,也就是说根据用例名称来顺序执行的
addtest(self)这个方法没执行,说明只执行test开头的用例
unittest 的断言:
在测试用例中,执行完测试用例后,最后一步是判断测试结果是pass还是fail,自动化测试脚本里面一般把这种生成测试结果的方法称为断言(assert)。
用unittest组件测试用例的时候,断言的方法还是很多的,下面介绍几种常用的断言方法:assertEqual、assertIn、assertTrue
#!/usr/bin/env python
# coding=utf-8
import unittest
import time
class Test(unittest.TestCase):
def test01(self):
'''判断 a == b '''
a = 1
b = 1
self.assertEqual(a, b)
def test02(self):
'''判断 a in b '''
a = "hello"
b = "hello world!"
self.assertIn(a, b)
def test03(self):
'''判断 a is True '''
a = True
self.assertTrue(a)
def test04(self):
'''失败案例'''
a = "上海wing"
b = "wing"
self.assertEqual(a, b)
if __name__ == '__main__':
unittest.main()
执行结果:
Traceback (most recent call last):
File "G:/boke/boke.py", line 24, in test04
self.assertEqual(a, b)
AssertionError: '上海wing' != 'wing'
- 上海wing
? --
+ wing
----------------------------------------------------------------------
Ran 4 tests in 0.001s
FAILED (failures=1)
assertEqual分析:
1.以assertEqual为例分析:
assertEqual(self, first, second, msg=None)
Fail if the two objects are unequal as determined by the ''
operator.
2.翻译:如果两个对象不能相等,就返回失败,相当于return: firstsecond
3.这里除了相比较的两个参数first和second,还有第三个参数msg=None,这个msg参数就是遇到异常后自定义输出信息
raceback (most recent call last):
File "G:/boke/boke.py", line 24, in test04
self.assertEqual(a, b)
AssertionError: '上海wing' != 'wing'
- 上海wing
? --
+ wing
----------------------------------------------------------------------
Ran 4 tests in 0.001s
FAILED (failures=1)
unittest 常用的断言:
1.assertEqual(self,first,second,msg=None)
判断两个参数相等:first == second
2.assertNotEqual(self,first,second,msg=None)
判断两个参数不相等:first != second
3.assertIn(self,member,container,msg=None)
判断是字符串是否包含:member in container
4.assertNotIn(self, member, container, msg=None)
--判断是字符串是否不包含:member not in container
5.assertTrue(self, expr, msg=None)
--判断是否为真:expr is True
6.assertFalse(self, expr, msg=None)
--判断是否为假:expr is False
7.assertIsNone(self, obj, msg=None)
--判断是否为None:obj is None
8.assertIsNotNone(self, obj, msg=None)
--判断是否不为None:obj is not None
案例:
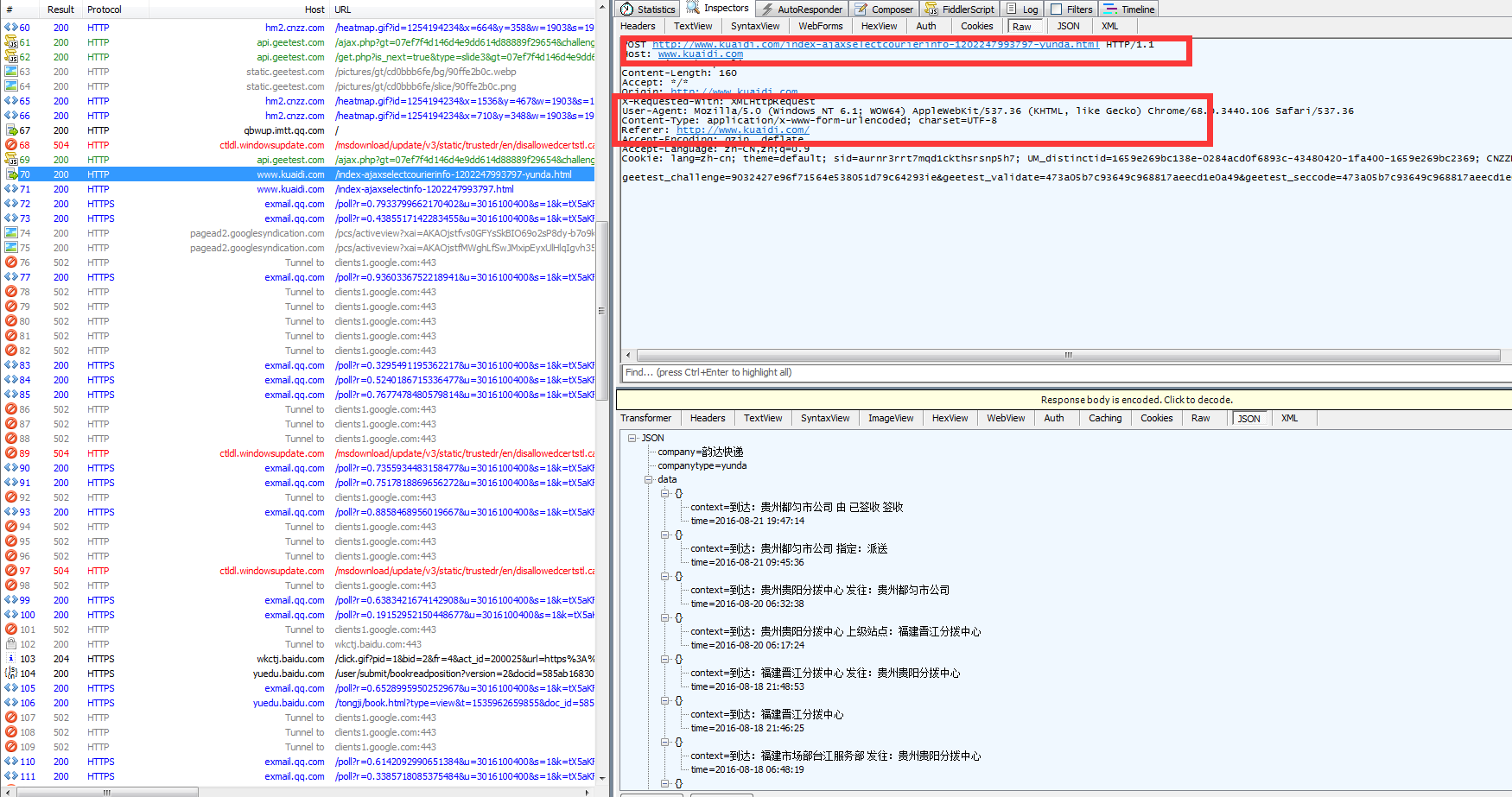
以一下抓包接口为例:
运单号为:1202247993797
快递公司为:韵达
http://www.kuaidi.com/index-ajaxselectcourierinfo-1202247993797-yunda.html
#!/usr/bin/env python
# coding=utf-8
import unittest
import time
import unittest
import requests
class Test_Kuaidi(unittest.TestCase):
def setUp(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"} # get方法其它加个ser-Agent就可以了
def test_yunda(self):
danhao = '1202247993797'
kd = 'yunda'
# 这里对url的单号参数了
self.url = "http://www.kuaidi.com/index-ajaxselectcourierinfo-%s-%s.html" % (danhao, kd)
print(self.url)
# 第一步发送请求
r = requests.get(self.url, headers=self.headers, verify=False)
result = r.json()
# 第二步获取结果
print(result['company']) # 获取公司名字
data = result['data'] # 获取data里面的内容
print(data[0]) # 获取data里面最上边一个
get_result = data[0]['context'] # 获取已经签收的状态
print(get_result)
# 断言:测试结果和期望结果的比较
self.assertEqual(u'韵达快递', result['company'])
self.assertIn(u'已签收', get_result)
def test_tiantian(self):
danhao = '560697415000'
kd = 'tiantian'
# 这里对url的单号参数了
self.url = "http://www.kuaidi.com/index-ajaxselectcourierinfo-%s-%s.html" % (danhao, kd)
print(self.url)
# 第一步发送请求
r = requests.get(self.url, headers=self.headers, verify=False)
result = r.json()
# 第二步获取结果
print(result['company']) # 获取公司名字
data = result['data'] # 获取data里面的内容
print(data[0]) # 获取data里面最上边一个
get_result = data[0]['context'] # 获取已经签收的状态
print(get_result)
# 断言:测试结果和期望结果的比较
self.assertEqual(u'韵达快递', result['company'])
self.assertIn(u'已签收', get_result)
if __name__ == '__main__':
unittest.main()
登陆接口
以博客园的登陆接口为案例:
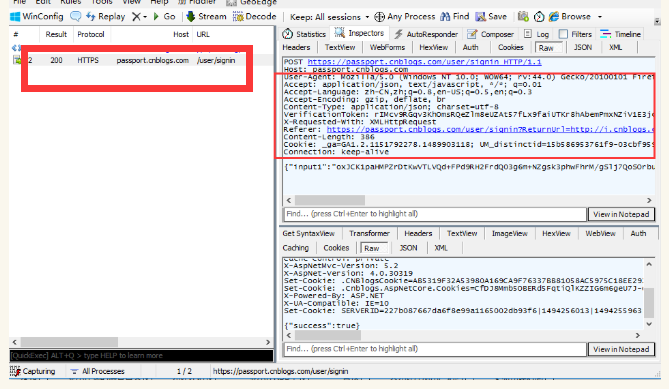
参考代码如下:
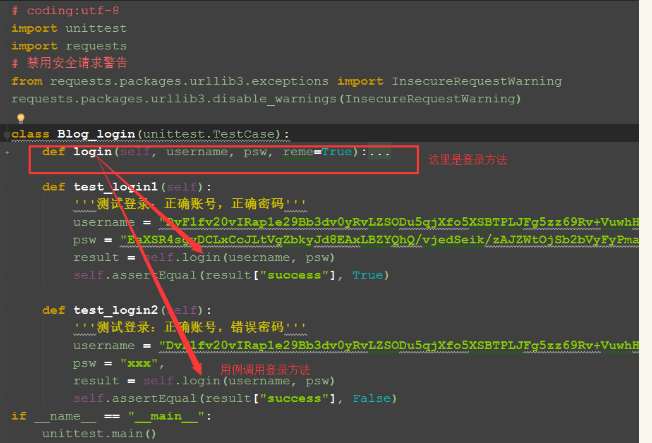
批量执行discover
一、例如:如图在自己的工作目录下,创建一个文件叫:runn_all.py
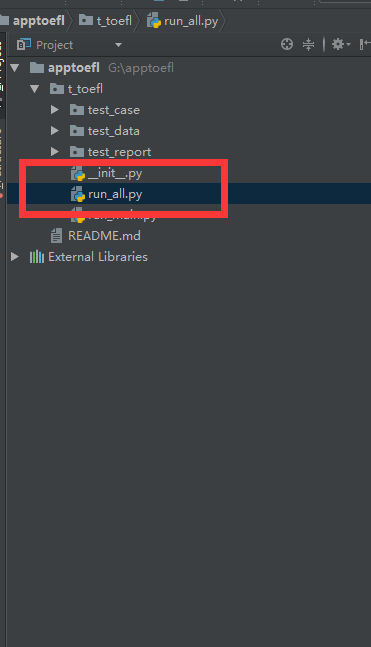
二、discover加载测试用例
1.discover方法里面有三个参数:
-case_dir:这个是待执行用例的目录。
-pattern:这个是匹配脚本名称的规则,test*.py意思是匹配test开头的所有脚本。
-top_level_dir:这个是顶层目录的名称,一般默认等于None就行了。
2.discover加载到的用例是一个list集合,需要重新写入到一个list对象testcase里,这样就可以用unittest里面的TextTestRunner这里类的run方法去执行。
例如:代码如下:(run_all.py)自己的项目中用到的,大家可以直接拿过来用;(注意报告或者testcase的文件名字,大家自行修改)
#!/usr/bin/env python
# coding=utf-8
import unittest
import os
import HTMLTestRunner
# 用例路径
case_path = os.path.join(os.getcwd(), "test_data")
print(case_path)
# 报告存放路径
report_path = os.path.join(os.getcwd(), "test_report")
print(report_path)
def all_case():
discover = unittest.defaultTestLoader.discover(case_path,
pattern="test*.py",
top_level_dir=None)
print(discover)
return discover
if __name__ == "__main__":
# runner = unittest.TextTestRunner()
# runner.run(all_case())
# html报告文件路径
report_abspath = os.path.join(report_path, "result.html")
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case())
fp.close()
上述的代码也包含了生成html报告的文件:
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的。
unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTestRunner
一、导入HTMLTestRunner
1.这个模块下载不能通过pip安装了,只能下载后手动导入,下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
2.Download下HTMLTestRunner.py文件就是我们需要下载的包。
3.下载后手动拖到python安装文件的Lib目录下
二、demo解析
1.下载Download下的第二个文件test_HTMLTestRunner.py,这个就是官方给的一个测试demo了,从这个文件可以找到该模块的用法。
2.找到下图这段,就是官方给的一个demo了,test_main()里上半部分就是加载测试case,我们不需要搞这么复杂。
3.最核心的代码是下面的红色区域,就行了,我们只用到这么多。
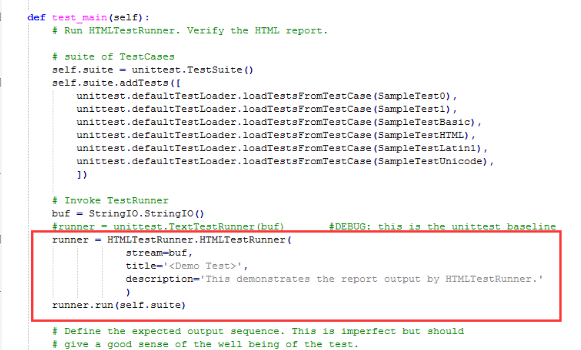
三、生成html报告
1.我们只需把上面红色区域代码copy到上一篇的基础上稍做修改就可以了,这里主要有三个参数:
--stream:测试报告写入文件的存储区域
--title:测试报告的主题
--description:测试报告的描述
2.report_path是存放测试报告的地址
if __name__ == "__main__":
# runner = unittest.TextTestRunner()
# runner.run(all_case())
# html报告文件路径
report_abspath = os.path.join(report_path, "result.html")
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 调用add_case函数返回值
runner.run(all_case())
fp.close()
四、查看报告:
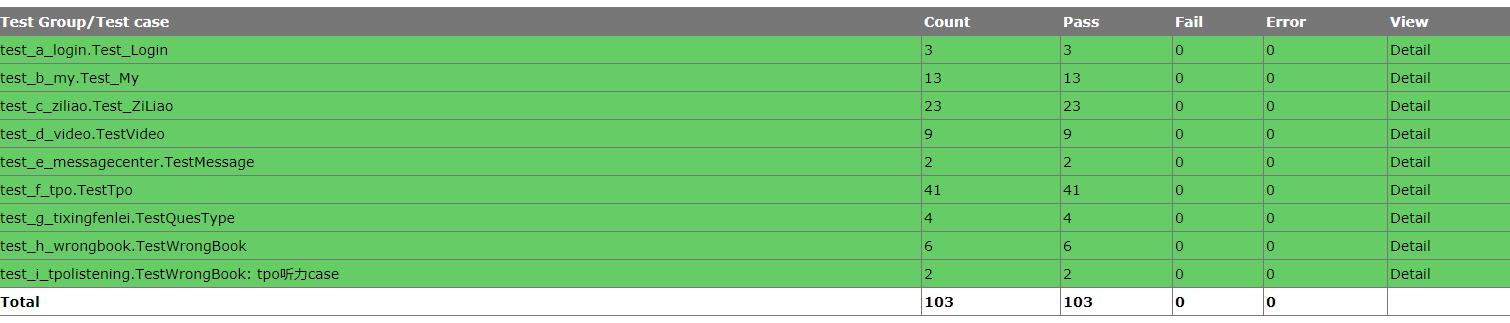
五、邮件里如何显示:具体的用例名称:

六、我们只需要在case里面添加上具体的功能描述就好了;

python2的时候报告会出问题:
python2用HTMLTestRunner生成测试报告时,有中文输出情况会出现乱码,这个主要是编码格式不统一,改下编码格式就行。
下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html
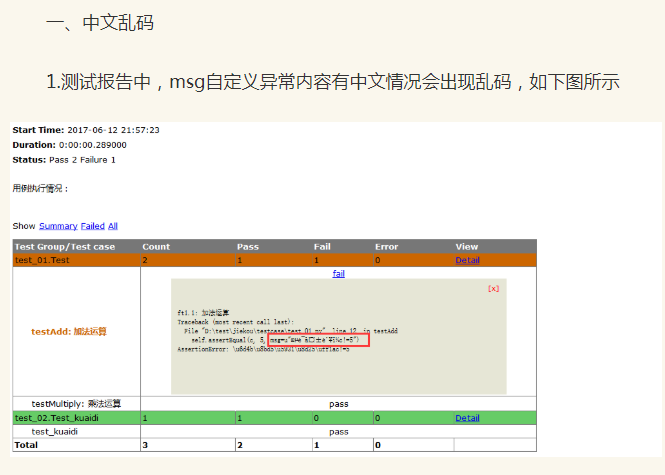
二、修改编码
1.找到HTMLTestRunner.py文件,搜索:uo =
2.找到红色区域设置编码的两个地方
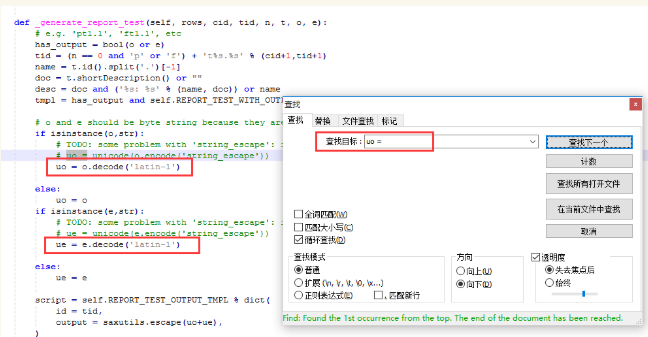
3.注释掉红色区域这两个设置,重新添加编码格式为:uo = o.decode('utf-8') ue = e.decode('utf-8')
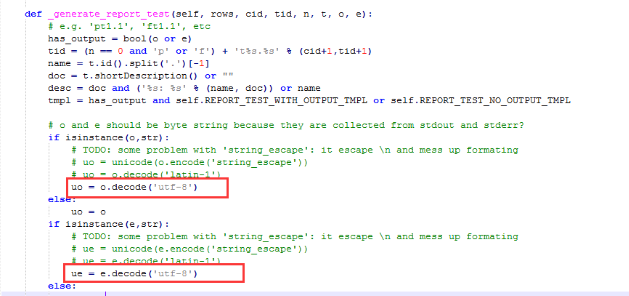
4.修改好之后记得保存,重新运行,乱码问题就解决了
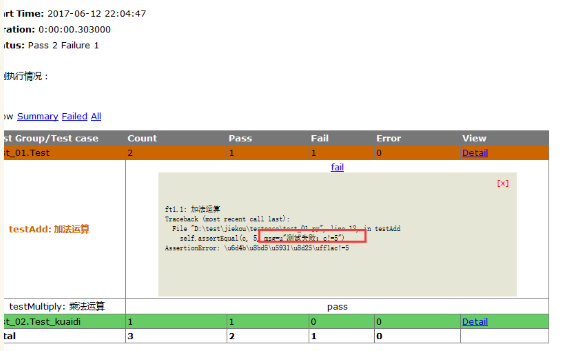
三、python3报告问题
1.python3的小伙伴直接用这个下载地址:http://tungwaiyip.info/software/HTMLTestRunner.html的文件,是不能直接生成报告的,需要稍做修改
2.以及报告美化版本都在如下地址里面
统一下载后放到:C:\python3\Lib对应的目录下就好了
具体的地址放在:
https://pan.baidu.com/s/1lUncNHRMfc7InR4E7nyPqA
密码:nqej
pycharm运行的方式:
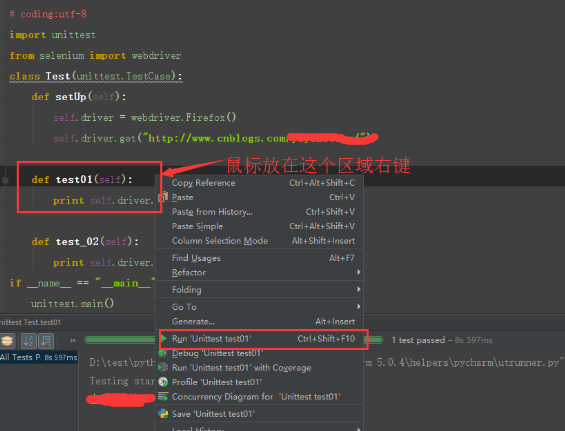
二、unittest运行整个脚本用例
1.如果想当前的脚本上所有的用例一起执行,只需把鼠标放到if name == "main":这句话的后面或者下方就行了
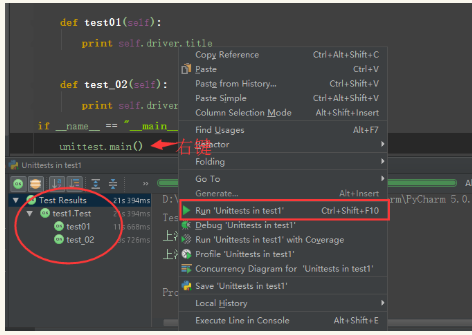
也可以鼠标直接放在:整个py 文件,然后运行;
也可以在命令行运行,大家自行研究一下
unittest测试的更多相关文章
- Python 下的unittest测试框架
unittest测试框架,直接上图吧: data:数据:主要格式为CSV:读取方式:csv.reade: public:封装的模块:通用的模块单独封装,所需参数设置为变量: testcase:测试用例 ...
- 【转】python模块分析之unittest测试(五)
[转]python模块分析之unittest测试(五) 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块分析之typing(三) p ...
- python内置模块之unittest测试(五)
系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块分析之typing(三) python模块分析之logging日志(四) pytho ...
- python利用unittest测试框架组织测试用例的5种方法
利用unittest测试框架可以编写测试用例,执行方式分两大类:利用main方法和利用testsuite,其中利用测试套件来组织测试用例可以有4种写法. 在此之前,先了解几个概念 TestCase:所 ...
- unittest 测试
unittest 测试 单元测试是用来对一个模块.一个函数或者一个类来进行正确性检验的测试工作. 比如对函数abs(),我们可以编写出以下几个测试用例: 输入正数,比如1.1.2.0.99,期待返回值 ...
- Python接口测试实战3(下)- unittest测试框架
如有任何学习问题,可以添加作者微信:lockingfree 课程目录 Python接口测试实战1(上)- 接口测试理论 Python接口测试实战1(下)- 接口测试工具的使用 Python接口测试实战 ...
- <day002>Selenium基本操作+unittest测试框架
任务1:Selenium基本操作 from selenium import webdriver # 通用选择 from selenium.webdriver.common.by import By # ...
- 基于Python的接口自动化-unittest测试框架和ddt数据驱动
引言 在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用 ...
- unittest测试驱动之HTMLTestRunner.py
对于自动化来说,测试报告是必须的,在敏捷化的团队中,团队中的成员需要自动化这边提供自动化的测试报告,来判断系统的整体质量以及下一步的测试策略.单元测试库生成测试输出到控制台的窗口上,但是这样的结果看起 ...
- (引用) unittest测试驱动之执行测试(三)
转载:http://www.wtoutiao.com/p/ydeoyY.html 在unittest的模块中,提供了TestRunner类来进行运行测试用例,在实际的应用中,经常使用的是TextTes ...
随机推荐
- python生成器异步使用
import dis,time # 反汇编 import threading def request(): print('start request') v = yield print(v) def ...
- spring boot 自定义视图路径
boot 自定义访问视图路径 . 配置文件 目录结构 启动类: html页面 访问: 覆盖boot默认路径引用. 如果没有重新配置,则在pom引用模板. 修改配置文件. 注意一定要编译工程
- python入门-python处理csv文件格式相关
python入门-python处理csv文件格式相关 处理 下载的csv格式文件 直接上代码和效果图 import csv from datetime import datetime from mat ...
- spark 运行架构
spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成. 其中SparkContext负责 ...
- RDD、DataFrame、Dataset
RDD是Spark建立之初的核心API.RDD是不可变分布式弹性数据集,在Spark集群中可跨节点分区,并提供分布式low-level API来操作RDD,包括transformation和actio ...
- C# 中的 ConfigurationManager类引用方法
c#添加了Configuration;后,竟然找不到 ConfigurationManager 这个类,后来才发现:虽然引用了using System.Configuration;这个包,但是还是不行 ...
- AspxGridView使用手记
AspxGridView使用手记 一. 基本使用方法 4 1.导入Dll文件 4 2.Asp.Net页面控件注册 4 3. Asp.Net页面控件声明 5 4.删除licenses. ...
- beego api 服务允许跨域访问,解决前端访问报Access-Control-Allow-Origin问题
背景: golang做了个简单服务,前端get请求拿数据,报错:No 'Access-Control-Allow-Origin' header is present on the requested ...
- 【版本发布】JAVA微服务开发框架,Jeecg-P3 1.0.0 重构版本发布
1.项目介绍 Jeecg-P3是一个微服务框架,采用插件式模式开发:业务插件以JAR方式提供,松耦合可插拔支持独立部署,也可无缝集成Jeecg平台中,目前jeecg已经提供了在线聊天,我的邮箱等一系列 ...
- shell脚本运行springboot项目jar包
#!/bin/bash APP_NAME=AutomationGuide-0.0.1-SNAPSHOT.jar #使用说明,用来提示输入参数 usage() { echo "please e ...