Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理
- 服务端安装部署:


.png)

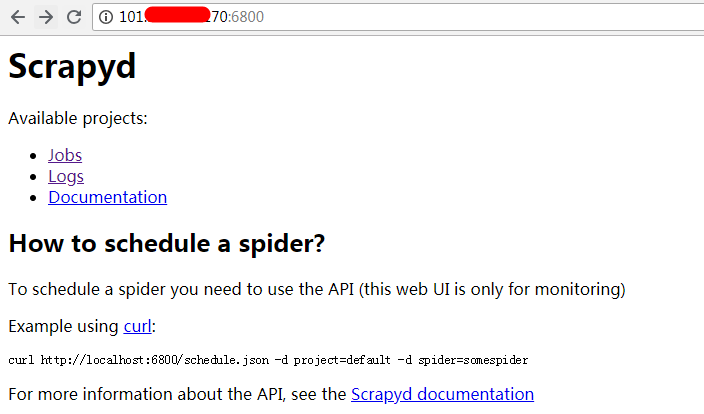
.png)
- 客户端安装部署:
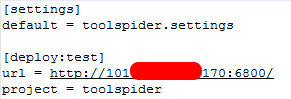
.png)
.png)


.png)
.png)


.png)
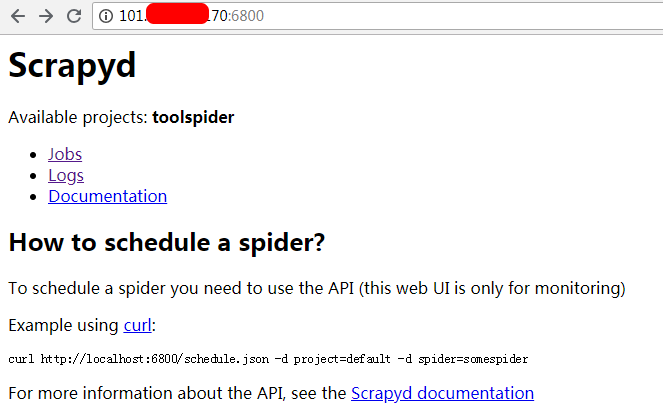
.png)
.png)


.png)

.png)
.png)


.png)
.png)

.png)


.png)
.png)

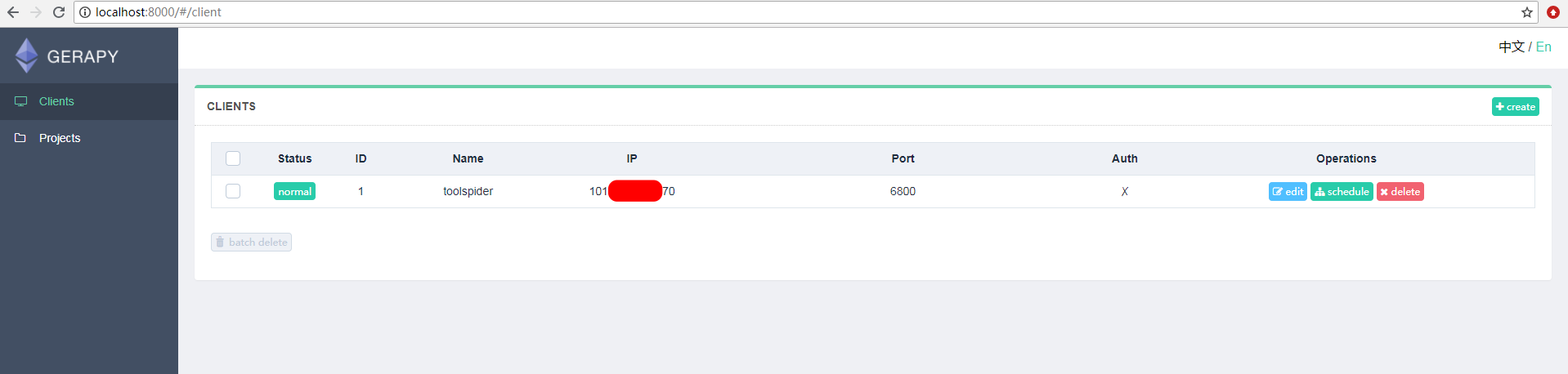
.png)
.png)

Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理的更多相关文章
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- 使用Scrapyd部署Scrapy爬虫到远程服务器上
1.准备好爬虫程序 2.修改项目配置 找到项目配置文件scrapy.cnf,将里面注释掉的url解开来 本代码需要连接数据库,因此需要修改对应的数据库配置 其实就是将里面的数据库地址进行修改,变成远程 ...
- Docker部署Portainer搭建轻量级可视化管理UI
1. 简介 Portainer是一个轻量级的可视化的管理UI,其本身也是运行在Docker上的单个容器,提供用户更加简单的管理和监控宿主机上的Docker资源. 2. 安装Docker Doc ...
- Scrapy爬虫基本使用
一.Scrapy爬虫的第一个实例 演示HTML地址 演示HTML页面地址:http://python123.io/ws/demo.html 文件名称:demo.html 产生步骤 步骤1:建议一个Sc ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- scrapy可视化管理工具spiderkeeper使用笔记
http://www.scrapyd.cn/doc/156.html 入门中文教程 spiderkeeper是一款开源的spider管理工具,可以方便的进行爬虫的启动,暂停,定时,同时可以查看分布式 ...
- Scrapy可视化管理软件SpiderKeeper
通常开发好的Scrapy爬虫部署到服务器上,要不使用nohup命令,要不使用scrapyd.如果使用nohup命令的话,爬虫挂掉了,你可能还不知道,你还得上服务器上查或者做额外的邮件通知操作.如果使用 ...
随机推荐
- 如何配置Linux的服务设置为自动启动或崩溃重新启动后
介绍 在本教程中,自动启动 Linux 服务,我们将退后一步,更详细地解释 init 进程. 你应该很好地了解它们如何控制守护进程的启动行为. 在第一部分本系列教程我们分享使用 MySQL 的如何崩溃 ...
- Redis学习---面试基础知识点总结
[学习参考] https://www.toutiao.com/i6566017785078481422/ https://www.toutiao.com/i6563232898831352323/ 0 ...
- C++设计模式 ==> 装饰(者)模式
简介 装饰模式指的是在不必改变原类文件和使用继承的情况下,动态地扩展一个对象的功能.它是通过创建一个包装对象,也就是装饰来包裹真实的对象.装饰模式使用对象嵌套的思想,实现对一个对象动态地进行选择性的属 ...
- Hadoop HBase概念学习系列之HLog(二)
首先,明确,HRegion服务器包含两大部分:HLog和HRegion. HLog用来存储数据日志,采用的是先写日志的方式. 当用户需要更新数据的时候,数据会被分配到对应的HRegion服务器上提交修 ...
- 团队作业——Alpha冲刺 7/12
团队作业--Alpha冲刺 冲刺任务安排 杨光海天 今日任务:将编辑界面与标题栏合并.与同队成员,讨论部分功能合并的问题. 明日任务:编辑界面与另一队员完成的字体设置弹窗合并. 郭剑南 今日任务:使用 ...
- Terminal Service 终端链接
2008 64位前有这项服务,之后就与远程管理合并了 如果要设置他的连接数可以去 桌面 --> 管理工具 --> 远程桌面服务 最大数设置成1个好了
- JDK 环境变量 Windows配置
安装完成JDK后需要配置环境变量,下面是环境变量的配置方法 1.配置环境变量: 对于Java程序开发而言,主要会使用JDK的两个命令:javac.exe.java.exe.路径:C:\Java\jdk ...
- 利用gulp 插件gulp.spritesmith 完成小图合成精灵图,并自动输出样式文件
安装依赖 yarn add gulp yarn add gulp.spritesmith 本次依赖的版本是: "gulp": "^3.9.1" "gu ...
- __init__函数
初始化函数,类似于c++的构造函数 在创建一个对象时默认被调用,不需要手动调用.self后面接的形参,在类实例化的时候必须传递,__init__函数里的参数都属于成员变量
- XmlSpy / XSD以及验证
很早以前看过一句话:“XML就象空气”,在企业应用开发中XML是一个重要的数据交换标准.而XSD则可以用来校验XML的数据格式是否正确. 一个典型的XSD文件如下: <?xml version= ...