CMU-15445 LAB1:Extendible Hash Table, LRU, BUFFER POOL MANAGER
概述
最近又开了一个新坑,CMU的15445,这是一门介绍数据库的课程。我follow的是2018年的课程,因为2018年官方停止了对外开放实验源码,所以我用的2017年的实验,但是问题不大,内容基本没有变化。想要获取实验源码的同学可以上github搜,或者直接clone我的代码,找到最早的commit就ok了,仓库地址在文末。课程配套教材是《
Database System Concepts》,https://book.douban.com/subject/4740662/ 最好看原版的,中文版的貌似页数和课程中的对不上。
言归正传,本lab将实现一个Buffer Pool Manager,又分为三个子任务:
- 实现一个Extendible Hash Table
- 实现一个LRU Page Replacement Policy
- 实现Buffer Pool Manager
Extendible Hash Table
Extendible Hash Table是动态hash的一种,动态是相对静态来说的。hash的原理是通过hash函数,f(key)->B,将key映射到一个Bucket地址集合中,如果B集合选的比较小,那么当key增多后,越来越多的key会落在同一个Bucket中,这样查找效率会下降。如果B集合一开始就选的很大,那么有很多Bucket处于未满状态,浪费空间。为了解决这个问题,就引入动态hash的概念。
静态hash存在上述问题主要是hash函数确定好后就不能再变了。动态hash就没有这个问题。
数据结构
Extendible Hash Table数据结构如下:
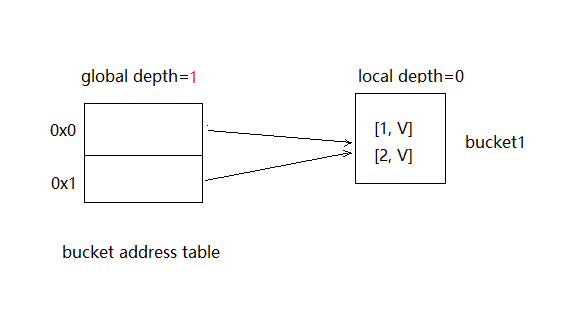
- bucket address table是一个数组,保存bucket的地址。
- global depth是一个整数值。
- 每个bucket都有一个local depth也是一个整数值,且小于等于global depth。每个bucket能装的键值对的最大值为bucketMaxSize。
查询
比如要查找key=1对应的value值,首先取h(1)对应的二进制前global depth位,作为bucket address table的下标,找到存放该key的bucket,然后在相应的bucket中查找。
插入
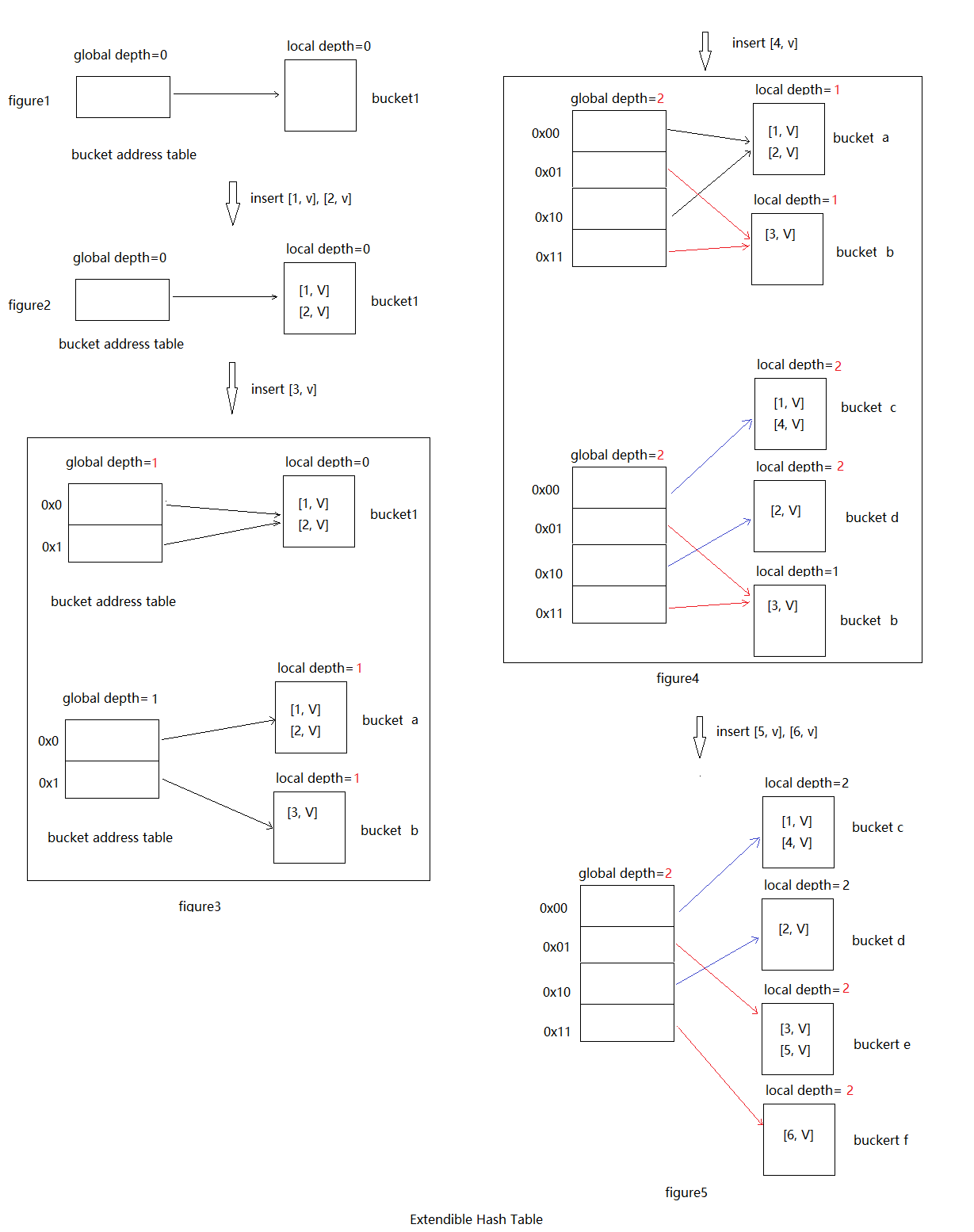
如上图,假设bucketMaxSize为2.
最开始的情况如figure1,我们插入[1, v], [2, v],因为这时global depth=0所以,全部落在bucket1中,也就是figure2。
在figure2基础上,再插入[3, v],这时还是应该插到bucket1中,但是bucket1已经满了,同时bucket1的local depth = global depth = 1。这时先将bucket address table扩大一倍,同时global depth加1。然后重新创建两个新的bucket a, bucket b,local depth在原来local depth基础上加1(由0变为1),再将bucket 1中的[1, v], [2, v]分配到新的两个bucket中,分配规则如下:
如果h(key)的第local depth(1)位是0,那么放到bucket a中,如果为1那么放到bucket b中。分配完毕后,重新调整bucket address table中指向原来bucket 1的指针指向,这里index 0和1的指针原来都指向bucket 1,所以都需要调整,调整规则如下:
index的第local depth(1)位为0的指向bucket a, 为1的指向bucket b。
最后在插入[3, v], 假设h(3)的前global depth为1,那么插入到bucket b中。最终的效果如figure3。
在figure3基础上再插入[4, v],算法和前面一样,假设[4, v]本应插入到bucket a中,但是bucket a满了,且global depth = bucket 1的local depth。所以先将bucket address table扩大一倍。然后重新创建两个新的bucket, bucket c和bucket d,再将bucket a中的[1, v], [2, v]重新分配到bucket c和bucket d中。在调整buckert address table指针指向,最后再插入[4, v]。最终效果如figure 4。
在figure4基础上,再插入[5, v], [6, v],假设都落在bucket b中,那么插入[5, v]后bucket b将满,再插入[6, v]的时候bucket b已经满了。这时和前面不一样,此时global depth(2) > bucket b的local depth(1)。所以不需要扩大bucket address table。只需要创建两个新的bucket, bucket e和bucket f。将原来bucket b中的[3, v], [5, v]分配到bucket e和bucket f中。然后调整原来指向bucket b的指针指向bucket e和bucket f。最后在插入[6, v]。最终效果如figure 5。
LRU PAGE REPLACEMENT POLICY
实现最近最少使用算法,说白了就是给你一些序列,比如1, 2, 3, 1,这时哪个是最近最少使用到的。可以画下图,越下面的越久没有使用到。先用了1,再用了2,那么2比1新,所以2在1上面,然后用了3,那么3应该在2的上面,最后用了1,那么把1从最下面调到最上面,同时2变到了最下面,至此2应该是最近最久没有使用的。
1 2 3 1
1 2 3
1 2
那么用什么数据结构来存储呢?
先看下有哪些操作:
void Insert(const T &value);
bool Victim(T &value);
bool Erase(const T &value);
Insert():将value加到最顶部,或者如果value已经在队列中,将其提取到最顶部。
Victim():提取最近最久没有使用的元素,将最底部的元素弹出。
Erase():删除某个元素。
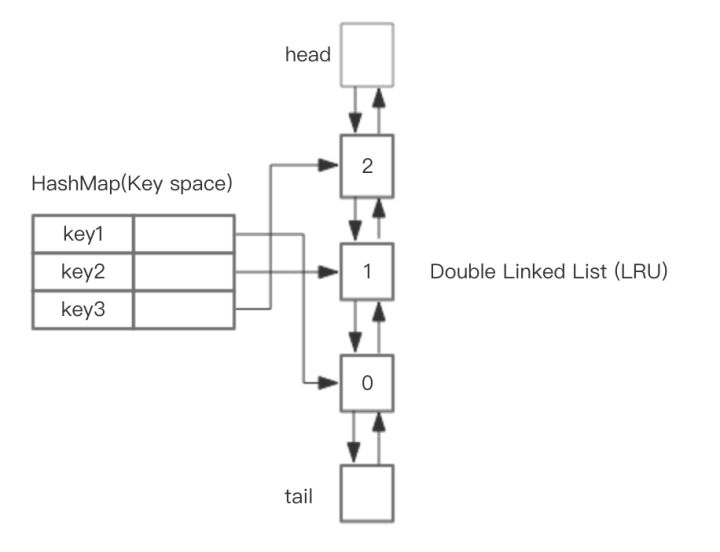
首先想到的是单向链表。但是如果用单向链表的话,Victim()需要访问尾元素,单向链表每次都要从头到尾遍历一遍才能访问尾元素,性能可想而知。
用双向链表就可以解决这个问题,双向链表可以以O(1)的时间访问头尾元素。还有个问题,如果调用Insert(v),按照之前的算法,我先得知道v在不在这个双向链表中,如果不在直接插到头部,如果在的话,将其提取到头部。如果仅仅是双向链表,那么还是需要遍历一遍队列,查询v是不是已经在队列中了。
可以用一个map记录已经在队列中的元素到链表节点的键值对,这样就可以以O(1)的时间查询某个value是否已经在队列中。
最终确定数据结构如下:
BUFFER POOL MANAGER
为什么需要BUFFER POOL MANAGER
假设两种极端的情况:
- 没有缓冲池,那么数据都位于磁盘上,第一次访问一页数据,需要将其从磁盘读取到内存,第二次在访问相同的页时,还需要从磁盘读,非常耗时。
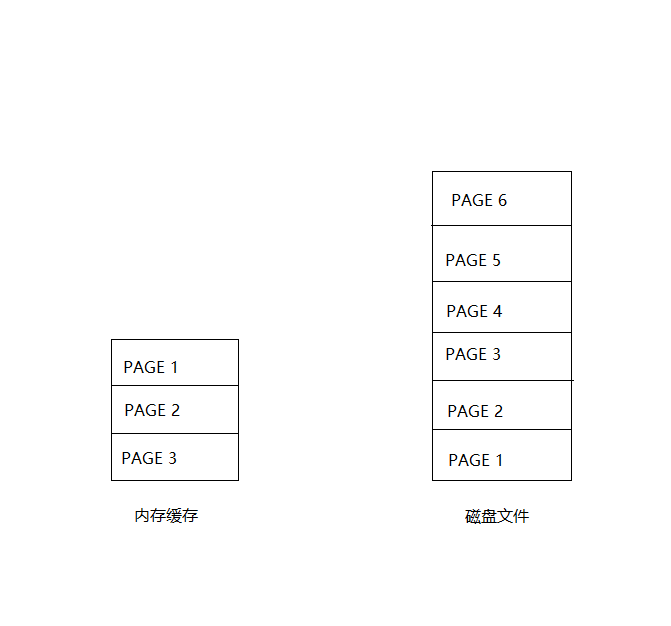
- 假设内存无限大,那么访问一页数据后,将该页数据直接保存到内存,下次再访问该页时,直接访问内存缓存就行。但是现实中内存比磁盘容量小得多,只能缓存有限个数据页,如下图内存只能缓存三个页,依次访问PAGE 1, 2, 3, 现在已经缓存了PAGE 1, 2, 3,假设想读取PAGE 4,那么得先清空一个内存缓存页,用来缓存PAGE 4的数据,那么清除谁呢?。这时候任务2的替换策略就派上用场了,根据LRU替换策略,PAGE 1是最近最久没有被使用过的,那么就将PAGE 1重新写回到磁盘,然后将PAGE 4读取到内存。
所以BUFFER POOL MANAGER的作用是加速数据的访问,同时对使用者来说是透明的。
具体代码就不贴了,可以参考我的实现:https://github.com/gatsbyd/cmu_15445_2018
CMU-15445 LAB1:Extendible Hash Table, LRU, BUFFER POOL MANAGER的更多相关文章
- CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
前言 该实验要求实现一个基于线性探测法的哈希表,但是与直接放在内存中的哈希表不同的是,该实验假设哈希表非常大,无法整个放入内存中,因此需要将哈希表进行分割,将多个键值对放在一个 Page 中,然后搭配 ...
- Spell checker using hash table
Problem description Given a text file, show the spell errors from it. (https://www.andrew.cmu.edu/c ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 散列表(hash table)——算法导论(13)
1. 引言 许多应用都需要动态集合结构,它至少需要支持Insert,search和delete字典操作.散列表(hash table)是实现字典操作的一种有效的数据结构. 2. 直接寻址表 在介绍散列 ...
- 哈希表(Hash Table)
参考: Hash table - Wiki Hash table_百度百科 从头到尾彻底解析Hash表算法 谈谈 Hash Table 我们身边的哈希,最常见的就是perl和python里面的字典了, ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- 几种常见 容器 比较和分析 hashmap, map, vector, list ...hash table
list支持快速的插入和删除,但是查找费时; vector支持快速的查找,但是插入费时. map查找的时间复杂度是对数的,这几乎是最快的,hash也是对数的. 如果我自己写,我也会用二叉检索树,它在 ...
- PHP内核探索之变量(3)- hash table
在PHP中,除了zval, 另一个比较重要的数据结构非hash table莫属,例如我们最常见的数组,在底层便是hash table.除了数组,在线程安全(TSRM).GC.资源管理.Global变量 ...
- php Hash Table(四) Hash Table添加和更新元素
HashTable添加和更新的函数: 有4个主要的函数用于插入和更新HashTable的数据: int zend_hash_add(HashTable *ht, char *arKey, uint n ...
随机推荐
- 洛谷P2480 古代猪文
这道题把我坑了好久...... 原因竟是CRT忘了取正数! 题意:求 指数太大了,首先用欧拉定理取模. 由于模数是质数所以不用加上phi(p) 然后发现phi(p)过大,不能lucas,但是它是个sq ...
- box-sizing border-box 的理解
http://blog.csdn.net/isaisai/article/details/20449827 -webkit-box-sizing: border-box; 则div 设置的宽高将包含 ...
- nginx代理服务器3--高可用(keepalived)
keepalived即健康检查,不停的发送心跳包检查nginx是否活着.Nginx至少两台,一主一备.
- 「Vue」vue cli3项目打包为APP方法及坑点
1.执行npm run build之后生成dist文件夹 2.打开HBuilderX新建一个APP项目 3.把dist文件夹里的所有文件拷贝替换到APP文件夹下 4.打开manifest.json文件 ...
- bzoj千题计划195:bzoj2844: albus就是要第一个出场
http://www.lydsy.com/JudgeOnline/problem.php?id=2844 题意:给定 n个数,把它的所有子集(可以为空)的异或值从小到大排序得到序列 B,请问 Q 在 ...
- 何凯文每日一句打卡||DAY7
- nginx配置伪静态
最近做门户网站,使用了的nginx重写规则 项目目录下写好 nginx.conf文件 然后在打开nginx配置文件,在server引入对应的重写规则的文件就可以了 当然直接写在配置里面 locatio ...
- Spring Mvc + Maven + BlazeDS 与 Flex 通讯 (七)
BlazeDS 说明 BlazeDS是由Adobe开源的基于amf协议的,用于解决flex与java通讯的组件; 基于传统的文本协议的XML传输方式,在抽象层方面会有很大的压力,特别在需要序列化与反序 ...
- Python 装饰器入门(上)
翻译前想说的话: 这是一篇介绍python装饰器的文章,对比之前看到的类似介绍装饰器的文章,个人认为无人可出其右,文章由浅到深,由函数介绍到装饰器的高级应用,每个介绍必有例子说明.文章太长,看完原文后 ...
- 洛谷 P1609 最小回文数 题解
这题其实并不难,重点在你对回文数的了解,根本就不需要高精度. 打个比方: 对于一个形如 ABCDEFGH 的整数 有且仅有一个比它大的最小回文数 有且仅有一个比它小的最大回文数 而整数 ABCDDCB ...