机器学习-文本数据-文本的相关性矩阵 1.cosing_similarity(用于计算两两特征之间的相关性)
函数说明:
1. cosing_similarity(array) 输入的样本为array格式,为经过词袋模型编码以后的向量化特征,用于计算两两样本之间的相关性
当我们使用词频或者TFidf构造出词袋模型,并对每一个文章内容做词统计以后,
我们如果要判断两个文章内容的相关性,这时候我们需要对数字映射后的特征做一个余弦相似度的匹配:即a.dot(b) / sqrt(a^2 + b^2)
在sklearn中使用metrics.pairwise import cosine_similarity
代码:
第一步: 对数据使用DataFrame化,并进行数组化
第二步:对数据进行分词,并去除停用词,使用' '.join连接列表
第三步:np.vectorizer向量化函数,调用函数进行分词和停用词的去除
第四步:使用TF-idf词袋模型,对特征进行向量化数字映射
第五步:使用 from sklearn.metrics.pairwise import cosine_similarity, 对两两样本之间做相关性矩阵,使用的是余弦相似度计算公式
import pandas as pd
import numpy as np
import re
import nltk #pip install nltk corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
] labels = ['weather', 'weather', 'animals', 'animals', 'weather', 'animals'] # 第一步:构建DataFrame格式数据
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus, 'categoray': labels}) # 第二步:构建函数进行分词和停用词的去除
# 载入英文的停用词表
stopwords = nltk.corpus.stopwords.words('english')
# 建立词分割模型
cut_model = nltk.WordPunctTokenizer()
# 定义分词和停用词去除的函数
def Normalize_corpus(doc):
# 去除字符串中结尾的标点符号
doc = re.sub(r'[^a-zA-Z0-9\s]', '', string=doc)
# 是字符串变小写格式
doc = doc.lower()
# 去除字符串两边的空格
doc = doc.strip()
# 进行分词操作
tokens = cut_model.tokenize(doc)
# 使用停止用词表去除停用词
doc = [token for token in tokens if token not in stopwords]
# 将去除停用词后的字符串使用' '连接,为了接下来的词袋模型做准备
doc = ' '.join(doc) return doc # 第三步:向量化函数和调用函数
# 向量化函数,当输入一个列表时,列表里的数将被一个一个输入,最后返回也是一个个列表的输出
Normalize_corpus = np.vectorize(Normalize_corpus)
# 调用函数进行分词和去除停用词
corpus_norm = Normalize_corpus(corpus) # 第四步:使用TfidVectorizer进行TF-idf词袋模型的构建
from sklearn.feature_extraction.text import TfidfVectorizer Tf = TfidfVectorizer(use_idf=True)
Tf.fit(corpus_norm)
vocs = Tf.get_feature_names()
corpus_array = Tf.transform(corpus_norm).toarray()
corpus_norm_df = pd.DataFrame(corpus_array, columns=vocs)
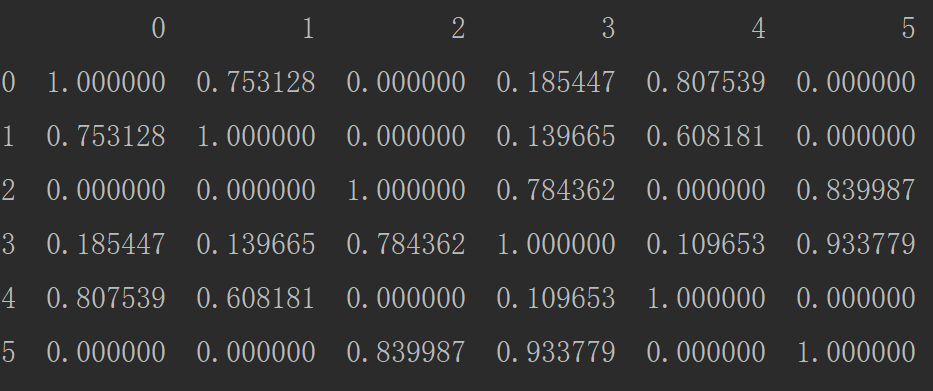
print(corpus_norm_df.head()) from sklearn.metrics.pairwise import cosine_similarity similarity_matrix = cosine_similarity(corpus_array)
similarity_matrix_df = pd.DataFrame(similarity_matrix)
print(similarity_matrix_df)
机器学习-文本数据-文本的相关性矩阵 1.cosing_similarity(用于计算两两特征之间的相关性)的更多相关文章
- Python机器学习之数据探索可视化库yellowbrick
# 背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plot ...
- R如何检验类别变量(nominal variable)与其他变量之间的相关性
1.使用Pearson积差相关系性进行检验的话可以判断两个变量之间的相关性是否显著以及相关性的强度 显著性检验 (significant test) 连续变量 vs 类别变量 (continuous ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- NLP相关问题中文本数据特征表达初探
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作.在介绍向量化之前,我们先来了解下词袋模型. 1.词袋模型(Bag of words,简称 BoW ) 词袋模型假设我们不考虑文本中词与词 ...
- scikit-learning教程(三)使用文本数据
使用文本数据 本指南的目标是探讨scikit-learn 一个实际任务中的一些主要工具:分析二十个不同主题的文本文档(新闻组帖子)集合. 在本节中,我们将看到如何: 加载文件内容和类别 提取适用于机器 ...
- 如何使用 scikit-learn 为机器学习准备文本数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 文本数据需要特殊处理,然后才能开始将其用于预测建模. 我们需要解析文本,以删除被称为标记化的单词.然后,这些词还需要被编码为整型或浮点型,以用作 ...
- Bulk Insert:将文本数据(csv和txt)导入到数据库中
将文本数据导入到数据库中的方法有很多,将文本格式(csv和txt)导入到SQL Server中,bulk insert是最简单的实现方法 1,bulk insert命令,经过简化如下 BULK INS ...
- C#大数据文本高效去重
C#大数据文本高效去重 转载请注明出处 http://www.cnblogs.com/Huerye/ TextReader reader = File.OpenText(@"C:\Users ...
随机推荐
- MyBatis 接口的使用
为了简化MyBatis的使用MyBatis的使用,MyBatis提供了接口方式自动化生成调用过程,可以大大简化MyBatis的开发 开发映射文件: <select id="queryO ...
- ipv6下jdbc的连接数据库方式
ipv6下jdbc的连接数据库方式 MySQL: ipv4 Driver URL: jdbc:mysql://127.0.0.1:3306/database ipv6 Driv ...
- GRE协议
一. GRE(Generic Routing Encapsulation) 通用路由封装 是对某些网络层协议(如: IP , IPX , Apple Talk等)的数据报进行封装,使这些被封装的数据报 ...
- Fibonacci数列的两种实现方式
斐波那契数列的形式为:1,1,2,3,5,8,13,21......从第三项开始,后面的每一项都是前面两项的和. 实现的方式有一下 两种: 一:递归方式实现 def fib(n): if n < ...
- 逻辑运算符&逻辑短路
(1)and 逻辑与 全真则真,一假则假 print(True and True) #True print(False and True) #False print(False and False) ...
- iOS NSUserDefaults
一.介绍 NSUserDefaults适合存储请练级的本地数据,对于一些简单的数据(NSString类型)来说是首选,但是如果我们自定义了一个对象,对象保存的是一些信息,这是就不能直接存储到NSUse ...
- MapReduce高级编程
MapReduce 计数器.最值: 计数器 数据集在进行MapReduce运算过程中,许多时候,用户希望了解待分析的数据的运行的运行情况.Hadoop内置的计数器功能收集作业的主要统计信息,可以帮助用 ...
- 微信小程序学习笔记1--小程序的代码构成
最近打算学习一下微信小程序,看了微信公众平台的文档感觉还比较简单,就从这个方向重新找回学习的状态吧: 1.先了解一下小程序的代码构成: 创建项目后会看到四种后缀的文件: .json 后缀的 JSON ...
- 值得收藏的45个Python优质资源
REST API:使用 Python,Flask,Flask-RESTful 和 Flask-SQLAlchemy 构建专业的 REST API https://www.udemy.com/rest- ...
- 30 个 OpenStack 经典面试问题和解答
现在,大多数公司都试图将它们的 IT 基础设施和电信设施迁移到私有云, 如 OpenStack.如果你打算面试 OpenStack 管理员这个岗位,那么下面列出的这些面试问题可能会帮助你通过面试.-- ...