final year project:C++手写numpy并移植到RISC-V上——纪念我在中科院实习的日子
我毕设做的项目是用C++去实现一个Numpy,因为我是大数据专业,Numpy又是跟数据分析有关的工具,所以我打算自己动手去实现一个小型的Numpy,目前代码规模大概在六千多行左右,并且可以成功移植到OpenEuler RISC-V上面。在这个项目当中,我实现了比较多的数学函数,并且用到了各种高性能有关的技术,如:SIMD,OpenMP,OpenBlas,分别用来做数学运算的加速,向量化循环以及矩阵运算加速,我首先是在x86架构下完成了项目的大部分,后面才移植到了RISC-V上面,目前RISC-V有关的优化只有OpenMP以及OpenBlas,这两者都已经在OpenEuler RISC-V上成功移植并且可以成功运行。至于RVV指令集,目前该操作系统似乎还不太支持,所以如果有时间后面我再另外想办法。
template <typename T>
class ndarray {
private:
std::vector<T> __data;
std::vector<size_t> __shape;
std::vector<size_t> __strides;
size_t __size;
void compute_strides();
size_t calculate_offset(size_t row, size_t col) const noexcept;
...
}项目的数据结构大概如上,__data用于存储实际的数据,不管是一维还是二维的数据,都存在__data里面,至于二维怎么存,可以通过__strides数组结合calculate_offset去映射到一维数组上面;__shape是存储形状的数据结构,如果数组是一维的并且有五个元素,那么__shape就是{5},如果是二乘三的数组,那么__shape就是{2, 3};__size则是存储数组实际元素数量,也就是__data字段的大小。
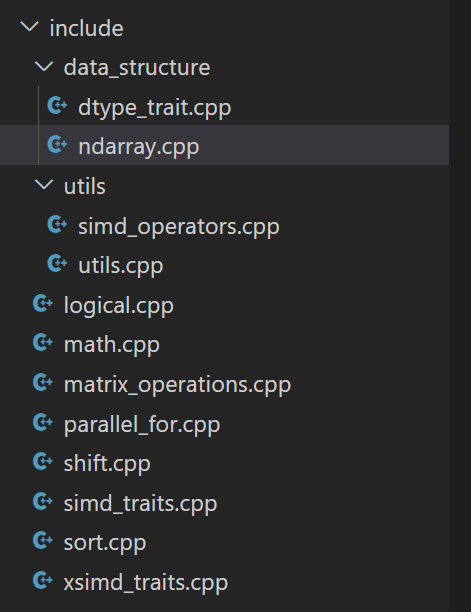
这是项目的结构,logical部分包含了位运算的实现代码,math部分包含了数学函数的实现,shift部分包含了位移的部分,matrix_operations部分包含了矩阵算法的部分,sort是排序部分,parallel_for是向量化for循环的部分。而simd_traits.cpp和xsimd_traits.cpp则负责编译期萃取类型,因为SIMD函数有很多类型,我将它封装成了一个结构体,里面各类型的函数都封装成一个统一接口,这样就能减少很多重复代码。
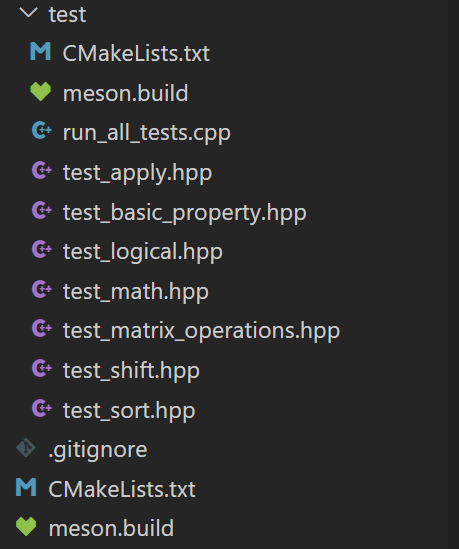
这里则是单元测试部分,我目前使用了GoogleTest对其进行了单元测试,分别对一维数组和二维数组的各种数学函数,并且也有异常相关的测试。该项目提供了CMake和Meson的构建方式,用户可以一键式构建,只需要提前下载gcc、GoogleTest、OpenBlas以及xsimd即可,SIMD指令集以及OpenMP套件一般在GNU工具链里面有。
template <typename T>
std::vector<T> add1(const std::vector<T>& A, const std::vector<T>& B) {
static_assert(std::is_arithmetic_v<T>, "Type must be arithmetic");
static_assert(!std::is_same_v<T, char>);
if (A.size() != B.size()) {
throw std::invalid_argument("Vector dimension mismatch");
}
size_t N = A.size();
std::vector<T> C(N);
if constexpr (std::is_same_v<T, float>) {
cblas_scopy(N, B.data(), 1, C.data(), 1);
cblas_saxpy(N, 1.0, A.data(), 1, C.data(), 1);
} else if constexpr (std::is_same_v<T, double>) {
cblas_dcopy(N, B.data(), 1, C.data(), 1);
cblas_daxpy(N, 1.0, A.data(), 1, C.data(), 1);
} else {
std::vector<float> float_A(N), float_B(N), float_C(N);
for (size_t i = 0; i < N; ++i) {
float_A[i] = static_cast<float>(A[i]);
float_B[i] = static_cast<float>(B[i]);
}
cblas_scopy(N, float_B.data(), 1, float_C.data(), 1);
cblas_saxpy(N, 1.0, float_A.data(), 1, float_C.data(), 1);
for (size_t i = 0; i < N; ++i) {
C[i] = static_cast<T>(float_C[i]);
}
}
return C;
}这里是向量加法部分,因为OpenBlas的函数接口有单精度和双精度类型的,所以我用了编译期条件判断去选择相应的函数实现,对于非浮点数类型,则将其转换为浮点类型再调用Blas的接口(因为Blas实在是快!),但其实这里还有优化的点,后面有时间再想想。
template <typename T>
struct round_simd_traits;
template <>
struct round_simd_traits<float> {
using scalar_type = float;
using simd_type = __m256;
static constexpr size_t step = 8;
static simd_type load(const scalar_type *ptr) noexcept {
return _mm256_loadu_ps(ptr);
}
static void store(scalar_type *ptr, simd_type val) noexcept {
_mm256_storeu_ps(ptr, val);
}
static simd_type op(simd_type a) noexcept {
return _mm256_round_ps(a, _MM_FROUND_TO_NEAREST_INT);
}
};
template <>
struct round_simd_traits<double> {
using scalar_type = double;
using simd_type = __m256d;
static constexpr size_t step = 4;
static simd_type load(const scalar_type *ptr) noexcept {
return _mm256_loadu_pd(ptr);
}
static void store(scalar_type *ptr, simd_type val) noexcept {
_mm256_storeu_pd(ptr, val);
}
static simd_type op(simd_type a) noexcept {
return _mm256_round_pd(a, _MM_FROUND_TO_NEAREST_INT);
}
};这里是SIMD萃取的过程,这样子外部调用的时候就可以直接统一用OP去调用,省去了函数重载的过程。
template <typename T>
std::vector<T> acos1_simd(const std::vector<T>& A) {
if (A.size() < 32)
return apply_unary_op_plain(A, [](const T& a) {
return std::acos(a);
});
#ifdef __riscv
return apply_unary_op_plain(A, [](const T& a) {
return std::acos(a);
});
#endif
#ifdef __AVX2__
return apply_unary_op_simd<T, acos_simd_traits<T>>(A, [](const T& a) {
return std::acos(a);
});
#endif
}这里是math函数部分,对于数据规模较小的,直接调用朴素循环,对于RISC-V架构,目前我的做法也是直接调用朴素循环(还可以优化),如果是支持AVX2的环境,则可以调用SIMD版本的函数。
if(CMAKE_SYSTEM_PROCESSOR MATCHES "x86_64|AMD64|i386|i686")
add_definitions(-mavx2 -fopenmp -O3)
elseif(CMAKE_SYSTEM_PROCESSOR MATCHES "riscv64")
add_definitions(-fopenmp -march=rv64gcv -O3)
endif()像CMake部分,经过我的测试,在O3优化的情况下性能最高,所以我开了O3优化。还有一点区别就是RISC-V需要开V扩展,而x86开-mavx2用来支持AVX2指令集。
name: CI
on:
push:
branches:
- main
pull_request:
branches:
- main
workflow_dispatch:
jobs:
build-and-test:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest]
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Install system dependencies
run: |
if [[ "${{ matrix.os }}" == "ubuntu-latest" ]]; then
sudo apt-get update
sudo apt-get install -y cmake build-essential libopenblas-dev libxsimd-dev libboost-all-dev
elif [[ "${{ matrix.os }}" == "fedora-latest" ]]; then
sudo dnf update -y
sudo dnf install -y cmake make gcc-c++ openblas-devel xsimd-devel boost-devel
fi
- name: Download and install Google Test
run: |
git clone https://github.com/google/googletest.git
cd googletest
mkdir build
cd build
cmake ..
make
sudo make install
- name: Create build directory
run: mkdir -p build
- name: Configure CMake
working-directory: build
run: cmake ..
- name: Build project
working-directory: build
run: make -j$(nproc)
- name: Run tests
working-directory: build/test
run: ./run_all_tests另外项目当中还提供了Ubuntu最新版的CI/CD,也就是Ubuntu 24.04,项目已开源,有时间我会多多commit,欢迎关注~
项目地址:https://github.com/Thomas134/numpy_project.git
final year project:C++手写numpy并移植到RISC-V上——纪念我在中科院实习的日子的更多相关文章
- 如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP, ...
- Android 手写Binder 教你理解android中的进程间通信
关于Binder,我就不解释的太多了,网上一搜资料一堆,但是估计还是很多人理解的有困难.今天就教你如何从 app层面来理解好Binder. 其实就从我们普通app开发者的角度来看,仅仅对于androi ...
- Tensorflow之基于MNIST手写识别的入门介绍
Tensorflow是当下AI热潮下,最为受欢迎的开源框架.无论是从Github上的fork数量还是star数量,还是从支持的语音,开发资料,社区活跃度等多方面,他当之为superstar. 在前面介 ...
- MLP 之手写数字识别
0. 前言 前面我们利用 LR 模型实现了手写数字识别,但是效果并不好(不到 93% 的正确率). LR 模型从本质上来说还只是一个线性的分类器,只不过在线性变化之后加入了非线性单调递增 sigmoi ...
- 基于Numpy的神经网络+手写数字识别
基于Numpy的神经网络+手写数字识别 本文代码来自Tariq Rashid所著<Python神经网络编程> 代码分为三个部分,框架如下所示: # neural network class ...
- Numpy实现简单BP神经网络识别手写数字
本文将用Numpy实现简单BP神经网络完成对手写数字图片的识别,数据集为42000张带标签的28x28像素手写数字图像.在计算机完成对手写数字图片的识别过程中,代表图片的28x28=764个像素的特征 ...
- 使用神经网络来识别手写数字【译】(三)- 用Python代码实现
实现我们分类数字的网络 好,让我们使用随机梯度下降和 MNIST训练数据来写一个程序来学习怎样识别手写数字. 我们用Python (2.7) 来实现.只有 74 行代码!我们需要的第一个东西是 MNI ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 代码手写UI,xib和StoryBoard间的博弈,以及Interface Builder的一些小技巧
近期接触了几个刚入门的iOS学习者,他们之中存在一个普遍和困惑和疑问.就是应该怎样制作UI界面.iOS应用是非常重视用户体验的,能够说绝大多数的应用成功与否与交互设计以及UI是否美丽易用有着非常大的关 ...
- keras实现mnist数据集手写数字识别
一. Tensorflow环境的安装 这里我们只讲CPU版本,使用 Anaconda 进行安装 a.首先我们要安装 Anaconda 链接:https://pan.baidu.com/s/1AxdGi ...
随机推荐
- Q:oracle如何查询表和视图的等修改时间和创建时间?
要查询表的修改时间,可以使用以下SQL语句: SELECT object_name, object_type, created, last_ddl_time FROM user_objects WHE ...
- Q:浏览器不能上网,但是可以ping通外网ip,dns配置也没问题(TCP/IP 无法建立传出连接)
问题症状 每隔一段时间,浏览器不能访问外网,重启电脑又正常,重置网卡无效 可以ping通外网ip地址,可以ping通外网域名 ping不通外网端口端口 查看日志 每次出现不能上网情况时都会有至少两条T ...
- Luogu P2468 SDOI2010 粟粟的书架 题解 [ 紫 ] [ 可持久化线段树 ] [ 二分 ] [ 前缀和 ]
粟粟的书架:二合一的缝合题. 前一半测试点 此时是 \(200\times 200\) 的二维问题,首先考虑暴力怎么写,显然是每次询问把查的全扔进大根堆里,然后一直取堆顶直到满足要求或者取空. 那么这 ...
- 0帧起手将腾讯混元大模型集成到Spring AI的全过程解析
在前面,我们已经为大家铺垫了大量的知识点,并深入解析了Spring AI项目的相关内容.今天,我们将正式进入实战环节,从零开始,小雨将带领大家一步步完成将第三方大模型集成到Spring AI中的全过程 ...
- C# 心跳检测实现
原文链接: https://blog.csdn.net/yupu56/article/details/72356700 TCP网络长连接 手机能够使用联网功能是因为手机底层实现了TCP/IP协议,可以 ...
- 【杂谈】主键ID如何选择——自增数 OR UUID?
1.生成位置如何影响选择? 数据库往返时间 使用自增数时,ID是由数据库在执行INSERT操作时生成的:而UUID则可以在应用层生成. 考虑这样的场景: 一个方法需要插入A和B两个实体.其中B的数据需 ...
- Openlayers 距离环绘制
思路:利用layer的StyleFunction 来使地图移动或者放缩的时候,使圆保持在地图中心 /** * 绘制距离环 * @param {number} distance 每环间隔距离,单位:米 ...
- 26考研高数习题:1.1. 分段&复合函数
§1.1. 分段&复合函数 更详细的考研数学精讲请访问「荒原之梦考研数学」 Ultra 版:www.zhaokaifeng.com 001 题目 设 \(g\left(x\right) = ...
- Azkaban - [01] 概述
简单的任务调度使用crontab.复杂的任务调度使用oozie.azkaban等开发调度系统. 一.为什么学习Azkaban 一个完整的数据分析系统通常都是由大量任务单元(shell脚本.java ...
- 使用QT开发远程linux服务器过程
1.添加设备为通用linux 2.设置ip用户名 3.创建私钥文件,原来有的qtc那俩个文件删掉. 4.部署公钥,前提是测试链接要出现成功 5.在kits里添加编译环境设置编译器为32位或者64 6. ...