Flink CDC 与Hudi整合
介绍
之前写过Flink CDC sink 到 Iceberg中,本篇主要实践如何CDC到hudi中.
什么是hudi?
Hudi is a rich platform to build streaming data lakes with incremental data pipelines
on a self-managing database layer, while being optimized for lake engines and regular batch processing.
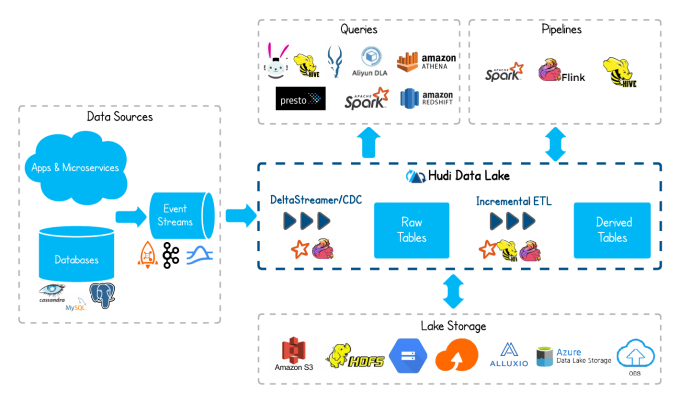
hudi 主要解决什么问题?
- HDFS的可伸缩性限制
- 需要在Hadoop中更快地呈现数据
- 没有直接支持对现有数据的更新和删除
- 快速的ETL和建模
- 要检索所有更新的记录,无论这些更新是添加到最近日期分区的新记录还是对旧数据的更新,Hudi都允许用户使用最后一个检查点时间戳。此过程不用执行扫描整个源表的查询
hudi的特性:
- Upserts, Deletes with fast, pluggable indexing.
- Incremental queries, Record level change streams
- Transactions, Rollbacks, Concurrency Control.
- SQL Read/Writes from Spark, Presto, Trino, Hive & more
- Automatic file sizing, data clustering, compactions, cleaning.
- Streaming ingestion, Built-in CDC sources & tools.
- Built-in metadata tracking for scalable storage access.
- Backwards compatible schema evolution and enforcement.
Flink CDC 与 Hudi整合
版本
Flink: 1.13.1
Hudi: 0.10.1
环境搭建
使用本地环境, hadoop 使用之前虚拟机安装的环境
MySQL Docker 安装个镜像,主要用于模拟数据变更,产生binlog数据
dockerpull mysql:latest
docker run -itd--name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
进入容器,可以使用mysql连接验证:
dockerexec -it 07e946b1fa9a /bin/bash
mysql -uroot -p123456
创建MySQL表:
createtable users
(
id bigint auto_increment primary key,
name varchar(20) null,
birthday timestamp defaultCURRENT_TIMESTAMP not null,
ts timestamp defaultCURRENT_TIMESTAMP not null,
sex int
);
整合代码实践
pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.chaplinthink</groupId>
<artifactId>flink-hudi</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.13.1</version>
</dependency> <!-- <dependency>--> <!-- <groupId>org.apache.flink</groupId>--> <!-- <artifactId>flink-jdbc_2.12</artifactId>--> <!-- <version>1.10.3</version>--> <!-- </dependency>-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.13.1</version>
<type>test-jar</type>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.11</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<!-- add the dependency matching your database -->
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<!-- The dependency is available only for stable releases, SNAPSHOT dependency need build by yourself. -->
<version>2.2.0</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>com.alibaba.ververica</groupId>-->
<!-- <artifactId>flink-connector-mysql-cdc</artifactId>-->
<!-- <version>1.2.0</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-flink-bundle_2.11</artifactId>
<version>0.10.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
</dependencies>
</project>
使用FlinkSQL 创建MySQL数据源表、Hudi目标表,通过
INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users 将数据写入hudi
核心代码:
final EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
final StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
environment.enableCheckpointing(3000);
final StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(environment, fsSettings);
tableEnvironment.getConfig().setSqlDialect(SqlDialect.DEFAULT);
// 数据源表
String sourceDDL = "CREATE TABLE mysql_users (\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3)\n" +
") WITH (\n" +
" 'connector' = 'mysql-cdc',\n" +
" 'hostname' = '192.168.70.3',\n" +
" 'port' = '3306', " +
" 'username' = 'aa',\n" +
" 'password' = 'aa', " +
" 'server-time-zone' = 'Asia/Shanghai'," +
" 'database-name' = 'test',\n" +
" 'table-name' = 'users'\n" +
" )";
/**
* 触发器策略是在完成五次提交后执行压缩
*/
// 输出目标表
String sinkDDL = "CREATE TABLE hudi_users2\n" +
"(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY (`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' = 'hdfs://ip:8020/hudi/hudi_users2'\n " +
")";
String transformSQL = "INSERT INTO hudi_users2 SELECT *, DATE_FORMAT(birthday, 'yyyyMMdd') FROM mysql_users\n";
tableEnvironment.executeSql(sourceDDL);
tableEnvironment.executeSql(sinkDDL);
tableEnvironment.executeSql(transformSQL);
environment.execute("mysql-to-hudi");
本地启动Flink程序
然后进行MySQL DML 操作
insertinto users (name) values ('hello');
insertinto users (name) values ('world');
insertinto users (name) values ('iceberg');
insertinto users (name) values ('hudi');
update users set name = 'hello spark' where id = 4;
delete from users where id = 5;
查看HDFS上hudi数据路径:

Hudi 默认情况下,MERGE_ON_READ表的压缩是启用的, 触发器策略是在完成五次提交后执行压缩. 在MySQL执行insert、update、delete等操作后,就可以用hive/spark-sql/presto进行查询。
如果没有生成parquet文件,我们建的parquet表是查询不出数据的。
五次提交后可以看到数据文件:

关掉Flink CDC程序, 单独写个FlinkSQL程序读取HDFS 上hudi数据:
public static void main(String[] args) throwsException {
final EnvironmentSettings fsSettings =EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
final StreamExecutionEnvironmentenvironment = StreamExecutionEnvironment.getExecutionEnvironment();
environment.setParallelism(1);
final StreamTableEnvironmenttableEnvironment = StreamTableEnvironment.create(environment, fsSettings);
tableEnvironment.getConfig().setSqlDialect(SqlDialect.DEFAULT);
String sourceDDL = "CREATE TABLEhudi_users2\n" +
"(\n" +
" id BIGINT PRIMARY KEY NOT ENFORCED,\n"+
" name STRING,\n" +
" birthday TIMESTAMP(3),\n" +
" ts TIMESTAMP(3),\n" +
" `partition` VARCHAR(20)\n" +
") PARTITIONED BY(`partition`) WITH (\n" +
" 'connector' = 'hudi',\n" +
" 'table.type' = 'MERGE_ON_READ',\n" +
" 'path' ='hdfs://ip:8020/hudi/hudi_users2',\n" +
" 'read.streaming.enabled' = 'true',\n"+
" 'read.streaming.check-interval' = '1'\n" +
")";
tableEnvironment.executeSql(sourceDDL);
TableResult result2 =tableEnvironment.executeSql("select * from hudi_users2");
result2.print();
environment.execute("read_hudi");
}
FlinkSQL读取到打印的数据:
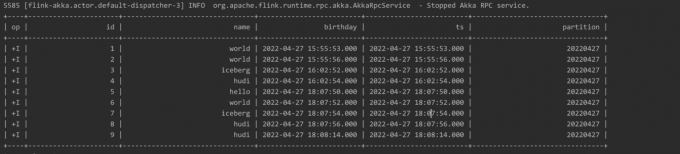
与MySQL 数据库表数据比对可以看到数据是一致的:
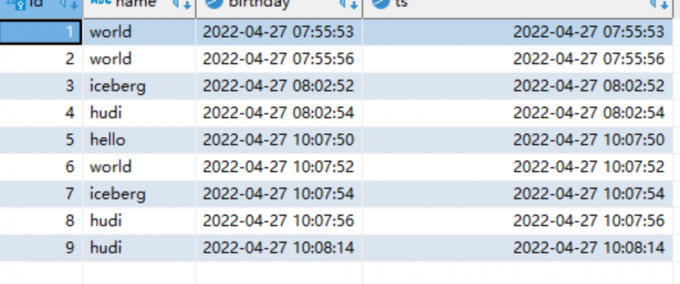
至此flink + hudi 湖仓一体化方案的原型就构建完成了.
总结
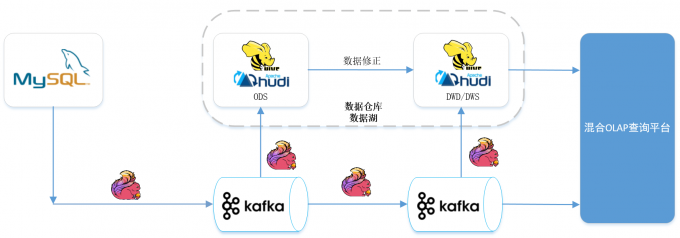
本篇主要讲解Flink CDC与hudi整合实践, 探索新的湖仓一体架构, 业内37手游的湖仓一体架构也可供参考如下:
对频繁增加表字段的痛点需求,同步下游系统的时候希望能够自动加入这个字段,目前还没有完美的解决方案,Flink CDC社区后续看是否提供 Schema Evolution 的支持.
目前MySQL新增字段,是需要修改Flink程序,然后重启.
参考:
- https://hudi.apache.org/cn/
- https://cloud.tencent.com/developer/article/1884134
- https://developer.aliyun.com/article/791526
Flink CDC 与Hudi整合的更多相关文章
- 重磅!解锁Apache Flink读写Apache Hudi新姿势
感谢阿里云 Blink 团队Danny Chan的投稿及完善Flink与Hudi集成工作. 1. 背景 Apache Hudi 是目前最流行的数据湖解决方案之一,Data Lake Analytics ...
- Fllin(七)【Flink CDC实践】
目录 FlinkCDC 1.简介 2.依赖 3.flink stream api 4.flink sql 5.自定义反序列化器 6.打包测试 FlinkCDC 1.简介 CDC是Change Data ...
- 使用Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
近年来出现了从单体架构向微服务架构的转变.微服务架构使应用程序更容易扩展和更快地开发,支持创新并加快新功能上线时间.但是这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难.为了获得更深入和更 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- 基于Apache Hudi + Flink的亿级数据入湖实践
本次分享分为5个部分介绍Apache Hudi的应用与实践 实时数据落地需求演进 基于Spark+Hudi的实时数据落地应用实践 基于Flink自定义实时数据落地实践 基于Flink+Hudi的应用实 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- Apache Hudi核心概念一网打尽
1. 场景 https://hudi.apache.org/docs/use_cases.html 近实时写入 减少碎片化工具的使用 CDC 增量导入 RDBMS 数据 限制小文件的大小和数量 近实时 ...
- Apache Hudi C位!云计算一哥AWS EMR 2020年度回顾
1. 概述 成千上万的客户在Amazon EMR上使用Apache Spark,Apache Hive,Apache HBase,Apache Flink,Apache Hudi和Presto运行大规 ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
随机推荐
- spring手动事务控制
在项目开发中需要用到手动事务进行控制.现说下遇到的问题以及解决方案: 如果程序需要使用嵌套事务,则需要在配置文件中添加一个配置属性,如下: <bean id="transactionM ...
- GPL前世今生
从事Linux开发的朋友一定都听过GPL,那么到底什么是GPL呢?他有什么作用呢?本文给大家做详细讲解. 一.GNU/GPL 在讲解GPL之前,我们必须先了解什么是GNU? 1. 什么是GNU GNU ...
- CD、VCD、DVD、BD 傻傻分不清楚?
CD 激光唱片(Compact Disk, CD),于 1982 年面世,最初用于存储数字音频.容量约 700 MB(80 分钟音频). 激光唱片 | 维基百科 VCD 影音光盘(Video Comp ...
- Kubernetes-1:初识k8s 什么是kubernetes
Kubernetes简介 为什么要用k8s? 容器间(Docker)在夸主机通信时,只能通过在主机做端口映射(DNAT)来实现,这种方式对于很多集群应用来说及其不方便.会影响整体处理速度,所以引入k8 ...
- 18 Python如何操作文件?
本篇是 Python 系列教程第 18 篇,更多内容敬请访问我的 Python 合集 1 打开文件 通常使用内置的 open(文件路径, 模式, encoding="utf-8") ...
- SQL Server 备份方案
参考 SQL Server三种常见备份 SQL Server备份策略 以前写的笔记 目的 在发生意外 (人为删除, 磁盘坏掉) 之后, 让数据可还原到指定时间点上. Backup 的种类 备份分 3 ...
- SaaS业务架构:业务能力分析
大家好,我是汤师爷~ 今天聊聊SaaS业务架构的业务能力分析. 业务能力概述 简单来说,业务能力是企业"做某事的能力". 业务能力描述了企业当前和未来应对挑战的能力,即企业能做什么 ...
- 【赵渝强老师】MongoDB的inMemory存储引擎
一.MongoDB的存储引擎概述 存储引擎(Storage Engine)是MongoDB的核心组件,负责管理数据如何存储在硬盘(Disk)和内存(Memory)上.从MongoDB 3.2 版本开始 ...
- 将 LLMs 精调至 1.58 比特: 使极端量化变简单
随着大语言模型 (LLMs) 规模和复杂性的增长,寻找减少它们的计算和能耗的方法已成为一个关键挑战.一种流行的解决方案是量化,其中参数的精度从标准的 16 位浮点 (FP16) 或 32 位浮点 (F ...
- foobar2000 v2.1.3 汉化版(更新日期:2024.04.02)
foobar2000 v2.1.3 汉化版 -----------------------[软件截图]---------------------- -----------------------[软件 ...