阿里IM技术分享(七):闲鱼IM的在线、离线聊天数据同步机制优化实践
本文由阿里闲鱼技术团队书闲分享,原题“如何有效缩短闲鱼消息处理时长”,有修订和改动,感谢作者的分享。
1、引言
闲鱼技术团队围绕IM这个技术范畴,已经分享了好几篇实践性总结文章,本篇将要分享的是闲鱼IM系统中在线和离线聊天消息数据的同步机制上所遇到的一些问题,以及实践性的解决方案。

学习交流:
- 移动端IM开发入门文章:《新手入门一篇就够:从零开发移动端IM》
- 开源IM框架源码:https://github.com/JackJiang2011/MobileIMSDK
(本文已同步发布于:http://www.52im.net/thread-3856-1-1.html)
2、系列文章
本文是系列文章的第7篇,总目录如下:
- 《阿里IM技术分享(一):企业级IM王者——钉钉在后端架构上的过人之处》
- 《阿里IM技术分享(二):闲鱼IM基于Flutter的移动端跨端改造实践》
- 《阿里IM技术分享(三):闲鱼亿级IM消息系统的架构演进之路》
- 《阿里IM技术分享(四):闲鱼亿级IM消息系统的可靠投递优化实践》
- 《阿里IM技术分享(五):闲鱼亿级IM消息系统的及时性优化实践》
- 《阿里IM技术分享(六):闲鱼亿级IM消息系统的离线推送到达率优化》
- 《阿里IM技术分享(七):闲鱼IM的在线、离线聊天数据同步机制优化实践》(* 本文)
3、问题背景
随着用户数的快速增长,闲鱼IM系统也迎来了前所未有的挑战。
历经多年的业务迭代,客户端侧IM的代码已经因为多年的迭代层次结构不足够清晰,之前一些隐藏起来的聊天数据同步问题,也随着用户数的增大而被放大。
这里面的具体流程在于:后台需要同步到用户端侧的数据包,后台会根据数据包的业务类型划分成不同的数据域,数据包在对应域里面存在唯一且连续的编号,每一个数据包发送到端侧并且被成功消费后,端侧会记录当前每一个数据域已经同步过的版本编号,下一次数据同步就以本地数据域的编号开始,不断的同步到客户端。
当然用户不会一直在线等待消息,所以之前端侧采用了推拉结合的方式保证数据的同步。
具体就是:
- 1)客户端在线时:使用ACCS实时的将最新的数据内容推送到客户端(ACCS是淘宝无线向开发者提供全双工、低延时、高安全的通道服务);
- 2)客户端从离线状态启动后:根据本地的数据域编号,拉取不在线时候的数据差;
- 3)当数据获取出现黑洞时:触发数据同步拉取(“黑洞”即指数据包Version不连续的状态)。
4、问题分析
当前的聊天数据同步策略确实是可以基本保障IM的数据同步的,但是也伴随着一些隐含的问题。
这些隐含的问题主要有:
- 1)短时间密集数据推送时,会快速的触发多次数据域同步。域同步回来的数据如果存在问题,又会触发新一轮的同步,造成网络资源的浪费。冗余数据包/无效的数据内容会占用有效内容的处理资源,又对CPU和内存资源造成浪费;
- 2)数据域中的数据包客户端是否正常消费,服务端侧无感知,只能被动地根据当前数据域信息返回数据;
- 3)数据收取/消息数据体解析/存储落库逻辑拆分不够清晰,无法针对性的对某一层的代码拆分替换进行ABTest。
针对上述问题,我们对闲鱼IM进行了分层改造——即抽离数据同步层。这样优化,除了希望以后这个数据的同步内容可以用在IM之外,也希望随着稳定性的增加,赋能其他的业务场景。
接下来的内容,我们重点来看下解决客户端侧闲鱼IM聊天数据同步问题的一些实践思路。
5、优化思路
5.1 分层拆分
对于服务端来说:业务侧产出数据包后,会拼接上当前的数据域信息,然后通过数据同步层将数据推送到端侧。
对于客户端来说:接收到数据包后,会根据当前的数据域信息,来确定需要消费数据包的业务方,确保数据包在数据域内完整连续后,将数据体脱壳后交于业务侧消费,并且应答消费的状况。
数据同步层的抽取:把数据同步中的加壳、脱壳、校验、重试流程封装到一起,可以让上层业务只需要关心自己需要监听的数据域信息,然后当这些数据域更新数据的时候,可以获取到这些数据进行消费,而不再需要关心数据包是否完整。
这样做的话:
- 1)业务侧只需要关心业务侧对接的协议;
- 2)数据侧只需要关心数据侧包装的协议;
- 3)网络层负责真实的数据传输。
整体的架构原理如下:
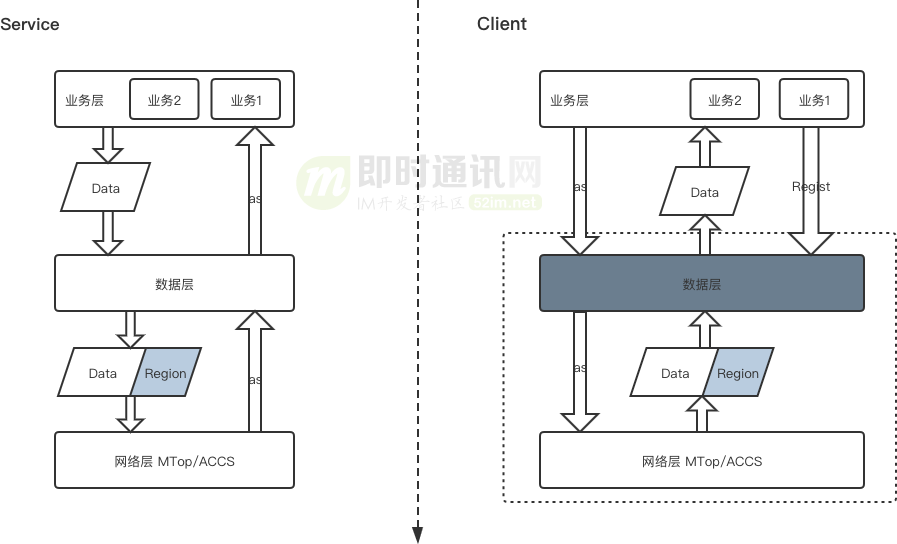
总结一下就是:
- 1)对齐数据层数据传输协议、描述当前数据包体数据域信息;
- 2)将消息的处理/合并/落库抽离成数据消费者;
- 3)上下楼依赖抽象化,去除对于具体实现的依赖。
5.2 数据层结构模型
基于对于数据模型剥离和对当下遇见问题的解决方案规整,将数据同步层拆分为下图这样的架构。

具体的实施思路就是:
- 1)App启动时建立ACCS长链接服务,保证推推送信道链接,并且根据当前本地数据域信息触发一次数据拉取;
- 2)数据消费者注册消费者信息和需要监听的数据域信息,这里是一对多的关系;
- 3)新的数据抵达端侧后,将数据包放到指定的数据域的缓冲池,批量数据归纳结束后,重新出发数据的读取;
- 4)根据当前数据域优先级弹出最高优的数据包,判断数据域版本是否符合消费者要求,符合则将数据包脱壳后丢给消费者消费,不符合则根据上一次正确的数据包的域信息触发增量的数据域同步拉取;
- 5)触发数据域同步拉取时,block数据读取,此时通过ACCS触达的数据依旧会在继续归纳到指定的数据域队列中,等待数据域同步拉取结果,将数据包进行排序、去重,合并到对应的数据域队列中。然后重新激活数据读取;
- 6)数据包体被消费者正确消费后,更新域信息并且通过上行信道告知服务端已经正确处理的数据域信息。
* 数据域同步协议:
Region中携带的数据不必过多,但需将数据包的内容描述清楚,具体是:
- 1)目标用户的ID,用以确定目标数据包是否正确;
- 2)数据域ID和优先级信息;
- 3)当前数据包的域优先级版本。
* 排序策略:
针对于域数据归纳,无论是在写入数据的时候进行排序还是在读取的时候进行查找都需要进行一次排序的操作,时间复杂度最优也是O(logn)级别的。
在实际coding中发现由于在一个数据域里面,数据包的Version信息是连续唯一并且不存在断层的,上一个稳定消费的数据体的Version信息自增就是下一个数据包的Version,所以这里采用了以Versio为主键的Map存储,既降低了时间复杂度,也使得唯一标识的数据包后抵达端侧的包内容可以覆盖之前的包内容。
6、新的问题及解决策略
6.1 多数据来源和唯一数据消费的平衡
每当产生一条针对于当前用户的数据包:
- 1)如果当前ACCS长链接存在,就会通过ACCS将数据包推送到客户端;
- 2)如果App切换到后台一段时间,或者直接被杀死,ACCS链接断开,那么只能通过离线推送到用户的通知面板。
所以:每当App切换到活跃状态,都需要根据当前本地存储的数据域信息从后台触发一次数据同步。
数据包触达到客户端侧的来源主要是ACCS长链接的推送和域同步时的拉取,但是数据包的消费是根据数据域的监听划分的唯一消费者,也就是同一时间内只能消费一个数据包。
在压力测试中:当后台短时间内密集的将数据包通过ACCS推送到端侧时,端侧接收到的数据包并不有序,不连续的数据包域版本又会触发新的数据域同步,导致同样的一份数据包会通过两个不同的渠道多次的触达到端侧,浪费了不必要的流量。
当数据域同步时:这个时间节点产生的新数据包也会推送到端侧,数据体有效,并且需要被正确的消费。
针对上述这些问题的解决策略:
即在数据消费和数据获取中间装载一个数据中间层,当触发数据域同步的时候block数据的读取并且ACCS推送下来的数据包会被存放在一个数据的中转站里面,当数据域同步拉取的数据回来后,对数据进行合并后再重启数据读取流程。
6.2 数据域优先级
需要推送到客户端侧的数据包,根据业务的不同优先级也有不同的划分。
用户和用户的聊天产生的数据包会比运营类的消息的数据包优先级要高一些,所以要当多优先级的数据包快速的抵达端侧时,高优先级数据域的数据包需要被优先消费,而数据域的优先级也是需要动态调整,需要不断变换的优先级策略。
针对这个问题的解决策略:
不同的数据域,产生不同的数据队列,高优队列里面的数据包会被优先读取消费。
每一个数据包体中带回的数据域信息,都可以标注当前的数据域优先级,当数据域优先级发生变化的时候,调整数据包消费优先级策略。
7、优化后的效果
除去结构上分层梳理,使得数据同步层和依赖的服务内容可便捷解耦/每一个环节可插拔之外,数据同步中对于消息消费时长/流量节省,压力测试场景下优化效果更加明显。
在“500ms内100条全乱序数据包推送”压力测试场景下:
- 1)消息处理时长(接收-上屏)缩短 31%;
- 2)流量损耗(最终拉取到端侧数据包累积大小)降低35%。
8、后续的优化计划
8.1 数据同步层能力提升
数据同步侧的目标,既要保证数据包完整的到达端侧,又要在保证稳定性的前提下尽可能的减少数据的拉取,使得每一次数据的获取都有效。
后续数据同步层会着手于有效数据率和到达率进行更进一步的优化。
针对不同的场景,动态智能调整数据同步的优先级策略。
阻塞式长链接推送,保证同一时间只存在推模式或者拉模式,进一步减少冗余数据包的推送。
8.2 IM端侧整体架构升级
升级数据同步层策略主要还是要提升IM的能力,将数据同步分层后,接下来就是将消息的处理流程化,对每一个流程都可监控可回溯,提升IM数据包的正确解析存储和落库率。
细化一下就是:
- 1)在数据来源侧剥离开后,后续对IM的整改也会逐步的将消息的处理分层剥离;
- 2)消息处理关键节点的流程式上报、建立完整的监控体系,让问题发现先于用户舆情;
- 3)消息完整性的动态自检,最小化数据补偿补全。
9、参考资料
[1] IM单聊和群聊中的在线状态同步应该用“推”还是“拉”?
[3] 一套高可用、易伸缩、高并发的IM群聊、单聊架构方案设计实践
[4] 一套亿级用户的IM架构技术干货(下篇):可靠性、有序性、弱网优化等
[5] 从新手到专家:如何设计一套亿级消息量的分布式IM系统
[7] 移动端IM中大规模群消息的推送如何保证效率、实时性?
[10] IM消息送达保证机制实现(一):保证在线实时消息的可靠投递
[11] IM消息送达保证机制实现(二):保证离线消息的可靠投递
[12] 零基础IM开发入门(四):什么是IM系统的消息时序一致性?
[13] IM开发干货分享:我是如何解决大量离线消息导致客户端卡顿的
(本文已同步发布于:http://www.52im.net/thread-3856-1-1.html)
阿里IM技术分享(七):闲鱼IM的在线、离线聊天数据同步机制优化实践的更多相关文章
- 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路
本文来自知乎官方技术团队的“知乎技术专栏”,感谢原作者陈鹏的无私分享. 1.引言 知乎存储平台团队基于开源Redis 组件打造的知乎 Redis 平台,经过不断的研发迭代,目前已经形成了一整套完整自动 ...
- 融云技术分享:解密融云IM产品的聊天消息ID生成策略
本文来自融云技术团队原创分享,原文发布于“融云全球互联网通信云”公众号,原题<如何实现分布式场景下唯一 ID 生成?>,即时通讯网收录时有部分改动. 1.引言 对于IM应用来说,消息ID( ...
- Cocos2d-x手游技术分享(1)-【天天打蚊子】数据存储与音效篇
前言: 手游项目<天天打蚊子>终于上线,特地写几篇技术分享文章,分享一下其中使用到的技术,其中使用cocos2d-x引擎,首选平台iOS,也请有iPhone或者iPad的朋友帮忙下载好评. ...
- 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路
本文原始内容由作者“阳振坤”整理发布于OceanBase技术公众号. 1.引言 OceanBase 是蚂蚁金服自研的分布式数据库,在其 9 年的发展历程里,从艰难上线到找不到业务场景濒临解散,最后在双 ...
- 闲鱼Flutter&FaaS云端一体化架构
讲师介绍 国有,闲鱼架构团队负责人.在7月13号落幕的2019年Archsummit峰会上就近一年来闲鱼在Flutter&FaaS一体化项目上的探索和实践进行了分享. 传统Native+Web ...
- 大数据学习路线:Hadoop集群同步技术分享
今天给大家带来的技术分享是——Hadoop集群同步. 一.同步方式 选择一个机器,作为时间服务器(这里选择hadoop01),所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间. ...
- 美团技术分享:深度解密美团的分布式ID生成算法
本文来自美团技术团队“照东”的分享,原题<Leaf——美团点评分布式ID生成系统>,收录时有勘误.修订并重新排版,感谢原作者的分享. 1.引言 鉴于IM系统中聊天消息ID生成算法和生成策略 ...
- MySQL Replication(数据同步技术)
MySQL Replication(数据同步技术) A 到 B 完成主从复制,意思是数据同步技术 从读取主的二进制日志文件,按照日志中记录对从库进行同样的操 ...
- 阿里钉钉技术分享:企业级IM王者——钉钉在后端架构上的过人之处
本文引用了唐小智发表于InfoQ公众号上的“钉钉企业级IM存储架构创新之道”一文的部分内容,收录时有改动,感谢原作者的无私分享. 1.引言 业界的 IM 产品在功能上同质化较高,而企业级的 IM 产品 ...
- 走近科学,探究阿里闲鱼团队通过数据提升Flutter体验的真相
背景 闲鱼客户端的flutter页面已经服务上亿级用户,这个时候Flutter页面的用户体验尤其重要,完善Flutter性能稳定性监控体系,可以及早发现线上性能问题,也可以作为用户体验提升的衡量标准. ...
随机推荐
- 报名开启|QKE 容器引擎托管版暨容器生态发布会!
当下,"云原生"技术红利正吞噬旧秩序,重塑新世界. 但您的企业是否依然困惑:缺少运维人员或运维团队,想要专注于业务的开发,又不得不兼顾集群的日常运维:在生产环境中,为了保证业务的高 ...
- 数据运算中关于字符串""的拼接问题
例子中准备了3种类型数据,分别针对是否在运算存在空字符串参与运算进行了演示,结果如下: 1 int x = 10; 2 double y = 20.2; 3 long z = 10L; 4 Syste ...
- DRF-Permission组件源码分析及改编源码
1. 权限组件源码分析 PS:下列源码为了方便理解都进行了简化,只保留了权限相关的代码 由于视图函数中继承了APIView,因此permission_classes可在视图类中进行重写. 注意点: 执 ...
- C++之OpenCV入门到提高002:加载、修改、保存图像
一.介绍 今天是这个系列<C++之 Opencv 入门到提高>得第二篇文章.今天这个篇文章很简单,只是简单介绍如何使用 Opencv 加载图像.显示图像.修改图像和保存图像,先给大家一个最 ...
- 在嵌入式设备中实现webrtc的第三种方式②
先贴上效果图以及操作路径. 操作路径为:启动信令服务器,配置浏览器关闭mDNS,双端登录,浏览器端邀请.最终连接成功建立,我们通过datachannel成功通信 (关闭mDNS是因为谷歌浏览器隐藏了局 ...
- NOIP2024模拟赛10:热烈张扬
NOIP2024模拟赛10:热烈张扬 T1 一句话题意:给定一颗树和两个玩家的起点 \(a,b\) 和各自的移动速度 \(da,db\).问:如果二人均以最优策略移动,问最后谁是赢家(先走到对方当前位 ...
- 利用 canvas 实现签名效果
利用 canvas 实现签名效果 使用插件 jSignature github:https://github.com/brinley/jSignature 如果再H5 中使用需要加载 flash ...
- 【问题解决】java.lang.SecurityException: JCE cannot authenticate the provider BC
问题复现 历史项目升级JDK(由1.7升级到8),进行加密/解密时出现报错java.lang.SecurityException: JCE cannot authenticate the provid ...
- Gitlab的基本操作
Gitlab的基本操作 Gitlab添加组 添加组建组有多个项目分支,可以将开发添加到组里面进行设置权限, 不同的组就是公司不同的开发项目或者服务模块,不同的组添加不同的开发即可实现对开发设置权限的 ...
- k8s-部署应用
Deployment # app-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: app-web spec: ...