python爬虫(BeautifulSoup)爬取B站视频字幕
比如“https://www.bilibili.com/video/BV1zU4y1p7L3”这个视频,有1.2万条弹幕
首先,B站视频的弹幕是有专门的接口传递数据的:http://comment.bilibili.com/***.xml,中间的*号是播放视频的id,怎么获取?
播放视频的时候按F12键,选择找到heartbeat,拉到最下方formdata内有cid字样即视频id
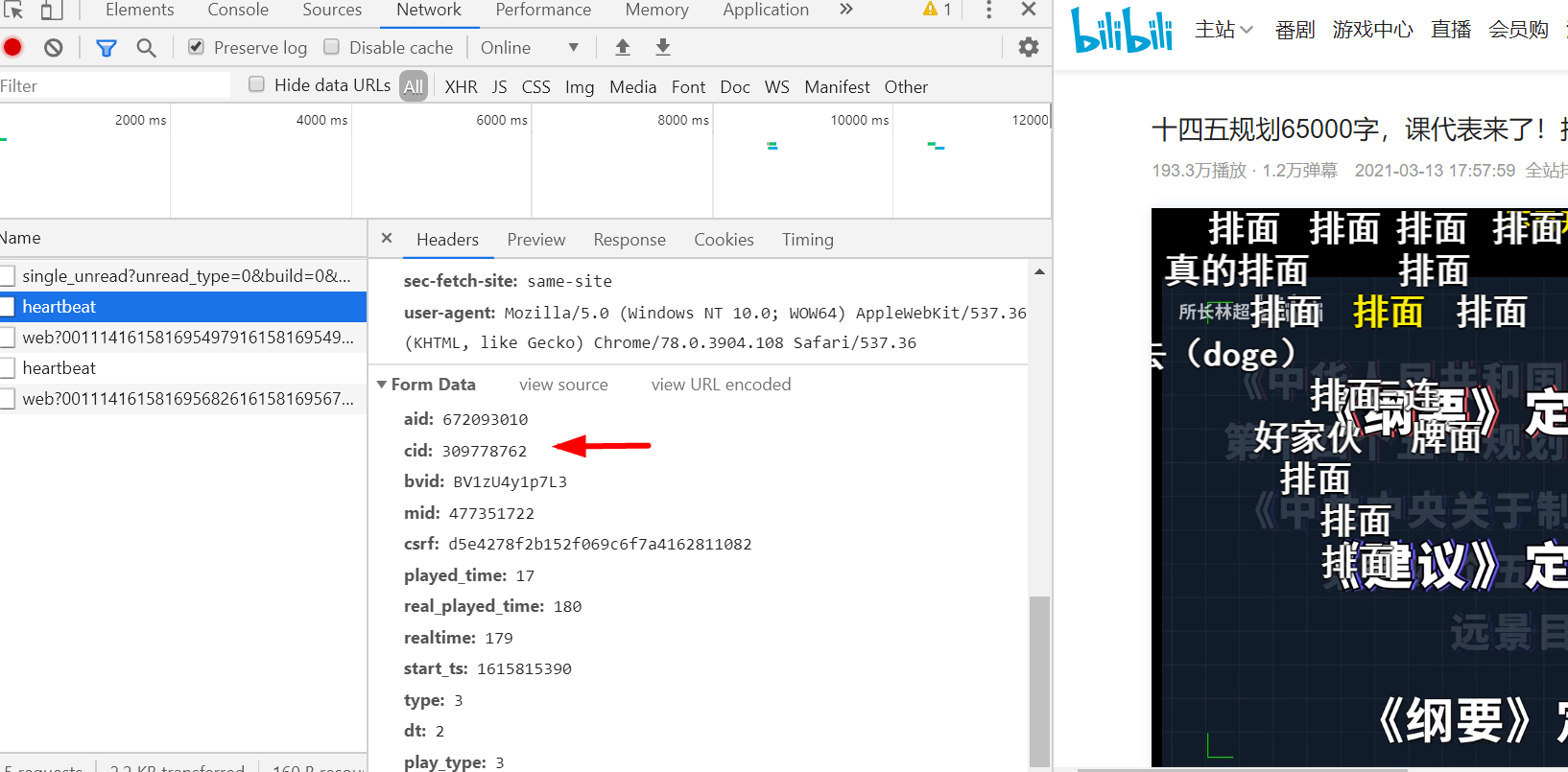
访问地址,http://comment.bilibili.com/309778762.xml拿到弹幕,但是这个接口只提供1000多条弹幕数据

接下来,我们将数据全部爬取下来,本次就不使用xpath爬虫来提取数据,使用BeautifulSoup来提取数据
网上安装BeautifulSoup教程很多,这里不表,导入BeautifulSoup库
from bs4 import BeautifulSoup
import requests
import re
爬取数据部分
url = 'http://comment.bilibili.com/309778762.xml'
html = requests.get(url)
html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml')
results = soup.find_all('d')
前面4行理解起来问题不大,常规步骤,关键在最后一行find内,可以表述问,查找文内所有标签“d”的内容
因为弹幕的内容都存放在标签d内

关于find_all的解析,请参看:https://www.cnblogs.com/keye/p/7868059.html,讲的很清楚
然后就是对获取数据的处理,只需要保留弹幕内容
for i in results:
i = str(i)
i = re.findall('">(.*?)</d>', i, re.S)[0]
print(i)
全部脚本如下
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup
import requests
import re url = 'http://comment.bilibili.com/309778762.xml'
html = requests.get(url)
html.encoding='utf8' soup = BeautifulSoup(html.text,'lxml')
results = soup.find_all('d') for i in results:
i = str(i)
i = re.findall('">(.*?)</d>', i, re.S)[0]
print(i)
打印输出
至于爬出来的数据怎么用,可以统计字频,获取做成词云(下图),那是后面研究的了

python爬虫(BeautifulSoup)爬取B站视频字幕的更多相关文章
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
- Python爬虫一爬取B站小视频源码
如果要爬取多页的话 在最下方循环中 填写好循环的次数就可以了 项目源码 from fake_useragent import UserAgent import requests import time ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬取B站视频信息
该文内容已失效,现已实现scrapy+scrapy-splash来爬取该网站视频及用户信息,由于B站的反爬封IP,以及网上的免费代理IP绝大部分失效,无法实现一个可靠的IP代理池,免费代理网站又是各种 ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
随机推荐
- 富数-AnonymFL
本文学习文章"2022 WAIC|「全匿踪联邦学习」AnonymFL正式发布:破解用户ID暴露难题,实现真正合规可信的隐私计算",记录笔记. 引言 2022年08月26日,富数科技 ...
- linux命令操作android手机
目的 通过一台linux机器操作android手机做一些常用的操作 复杂的操作都是由简单操作开始的, 可以自行发掘 环境 笔记本: thinkpad t480 操作系统: archlinux adb版 ...
- Delphi中IdHttp组件异常非200获取返回JSON数据
参考原文:https://www.atozed.com/forums/thread-771.html?highlight=400+Bad+Request 另外还有一篇文章说明也可参考 http://w ...
- Win10安装MySql步骤
1.下载 下载地址:https://dev.mysql.com/downloads/mysql/ 文件地址:https://dev.mysql.com/get/Downloads/MySQL-8.3/ ...
- Binomial Sum 学习笔记
- OSAL架构
OSAL操作系统最多可以支持16个任务,由任务功耗管理PwrMgr_task_state变量可知,而OSAL每个任务最多只能支持16个事件处理,理论上最大可以执行256个事件处理. 对于一些运算能力不 ...
- OpenCvSharp 打开rtsp视频并录制mp4文件
public class OpenCvSharpUtils { private VideoCapture Capture; private VideoWriter VideoWriter; priva ...
- 探秘Transformer之(8)--- 位置编码
探秘Transformer之(8)--- 位置编码 0x00 概述 位置编码(Positional Embedding)是一种用于处理序列数据的技术,被用来表示输入序列中的单词位置.在Transfor ...
- FormCreate设计器v5.6发布—AI加持的低代码表单设计器正式上线!
近期DeepSeek可谓是刷遍全网,当然,在DeepSeek等AI技术的推动下,人工智能正以惊人的速度改变着各行各业.AI不仅是一种技术趋势,更是未来生产力的核心驱动力. 如今,FormCreate设 ...
- 【ABAQUS脚本】后处理快速出图
效果图: # -*- coding: utf-8 -*- # Do not delete the following import lines from abaqus import * from ab ...