DAPO浅析
论文地址 https://arxiv.org/abs/2503.14476
参考实验:DAPO + vLLM v1 + VeRL —— VOC性能比较
Motivation
没有完整的GRPO训练R1-32B的框架
目标:
- 降低错误样本的长度 (token-level loss)
- 训练更加稳定 (overlong filter)
- 避免generation entropy的塌陷(higher clip)
- 提高训练效率(dynamic sample)
Method
整体优化目标如下
s.t.\ 0<|\{o_i|is\_equivalent(o_i,a)\}|<G
\]
其中
\]
这里DAPO剔除了KL散度惩罚项,它认为
在RLHF场景下,RL的目标是在不偏离原是模型分布下对齐人类偏好(即仅学习人类偏好,而不改变模型原有知识能力),因此需要添加KL惩罚项。
然而在训练long-cot的reasoning模型时,其目标是为了提升模型的能力(math、推理、code等)训练前后的模型分布可以是显著不一样的,KL惩罚项可能会限制模型的探索新知识的能力,因此去除。
分为以下四个方面
1. Raise the Ceiling: Clip-Higher
考虑到clip的是一个概率的比值\(\frac{\pi_{\theta}}{\pi_{old}}\),在\(\pi_{old}\)不同的情况下,会影响clip的范围
例如 \(\pi_{old}=0.1, \pi_{\theta}=0.2\), 此时比值为\(2\),此时policy会认为模型前后变化过大,而不训练此数据。但这条数据是值得训练的,只是old的概率比较小。
虽然比值是2倍,但其实数值上只多了0.1,因此还是需要被训练的,并没有影响收敛。
同时,实验也验证了上面发现的问题。实验发现GRPO中 被clip掉的token的平均概率的最大值均小于0.2 ,即
\]
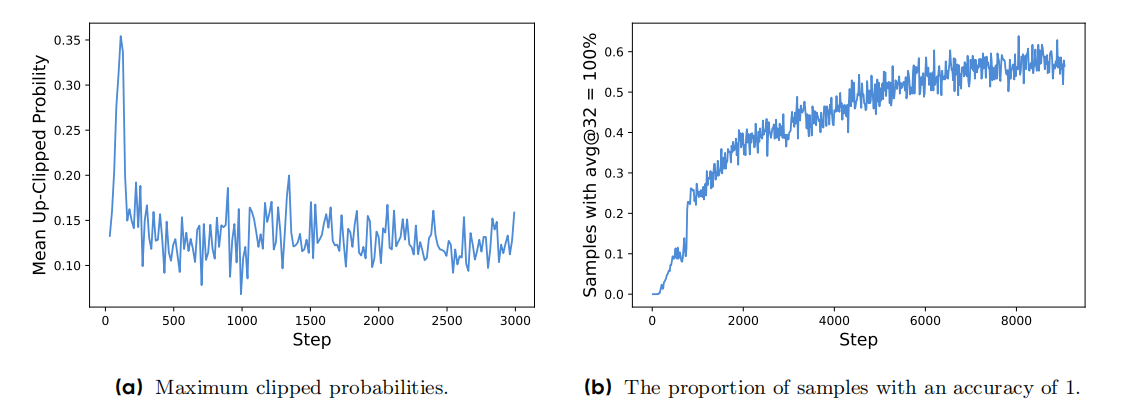
大量小概率的token被clip掉了,这验证了\(\epsilon_{high}\)阻碍了低概率token 概率的增长。
因此可以提高上限\(\epsilon_{high}\)来提高A>0的低概率token的概率,从而避免entropy变小的过快,输出单一化。
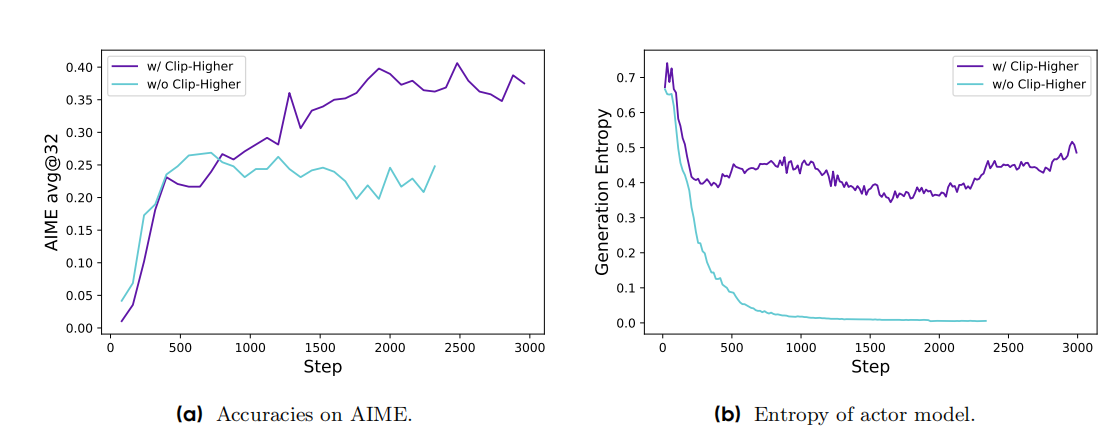
值得注意的现象,提高\(\epsilon_{higher}\)之后:
- RL的avg@32更高的
- 避免了熵塌的现象(因为高的\(\epsilon_{higher}\)鼓励模型探索原先小概率的正向轨迹,提高了多样性)
此外,old模型小概率sample并没有影响原有\(\epsilon_{low}\)
这是因为,\(\epsilon_{low}\)是在A<0的sample起作用,若重要性采样的比值很大,并不会对A<0的token进行裁剪。
2. The More the Merrier: Dynamic Sampling
考虑到如果一个sample的G个rollout的奖励
\(\{R_i\}_{i=1}^G\)都是0或都是1,那么所有的优势A都是0,这并不会更新policy,会导致效率低下
因此使用动态采样的方法,一直采样直到一个sample的G个rollout的R 不全是0 或不全是1.
\]
上述公示的含义是,对于QA对\((q,a)\),\(o_i\)和答案\(a\)相同的个数在\((0,G)\)的区间内。
3. Rebalancing Act: Token-Level Policy Gradient Loss
DAPO任务 sample-level的loss(每个rollout的贡献度是一样的),然后不同rollout的长度不一样,过长的样本对模型的影响更大一些:
- 过长的样本会导致模型难以学习推理模式 【置信度低,困惑度高】
- 过长的样本中存在一些不必要的 重复的话【长度增长过快】
因此使用token-level的技术,长度越大的rollout,贡献度越大。
通过grpo sample-level loss得知,grpo并不在意response的长短(不同长度的sample的贡献度均为相同),然而长度越长A越大,因此response的长度会快速的增加。
但是DAPO认为长度越长的sample的贡献度越大,因此过长的sample是对的会重点强化(提高概率),但是错了的话,会重点惩罚,从而减小错的长response的概率,即
\(P(len(o_i)>\delta|A<0)\)下降。
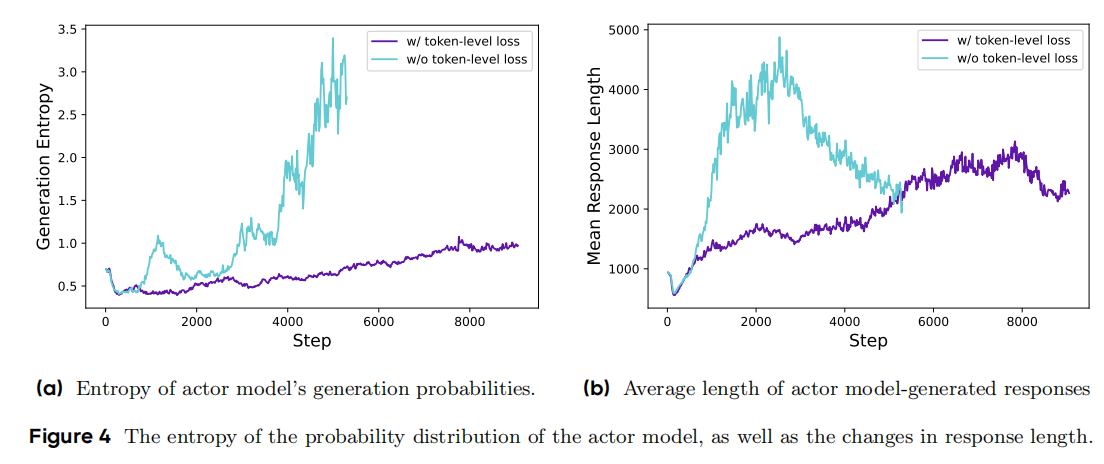
同时,通过实验发现,DAPO的response的平均长度并没有无脑、快速增长。
Hide and Seek: Overlong Reward Shaping
考虑到过长的response会被截断无法得到结果,这会导致奖励极低,
因此采用mask的方式,在训练的时候过滤掉过长response的损失。
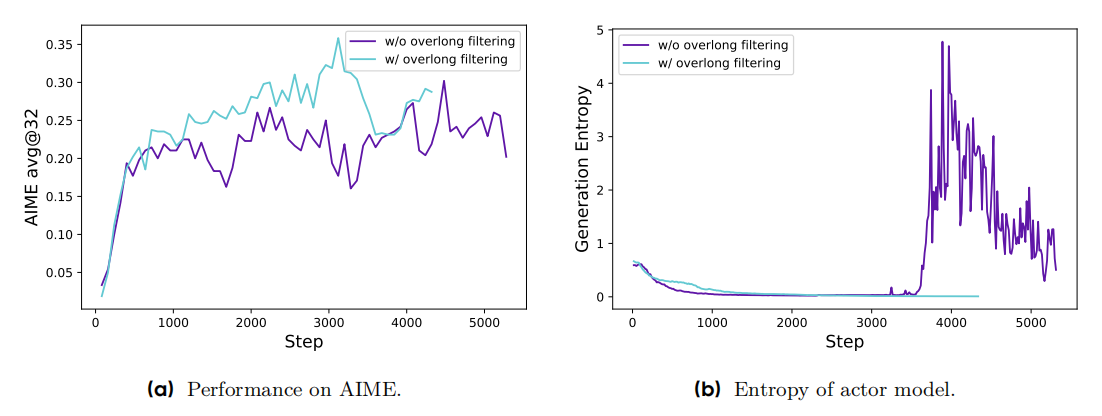
实验发现,添加overlong filter之后,训练更加稳定(entropy,acc上),避免了noise。
DAPO进一步提出了soft overlong punishment,其实是基于长度的奖励,就不用进行filter操作了,直接赋予低的R就可以了,有利于降低response的长度。添加了一个cache的缓冲区,从而soft。
0, &|y|\leq L_{max}-L_{cache}\\
-\frac{|y|-(L_{max}-L_{cache})}{L_{cache}}, &L_{max}-L_{cache}<|y|\leq L_{max}\\
-1, &L_{max}<|y|
\end{cases}
\]
代码解析待更新(verl实现dapo部分)
DAPO浅析的更多相关文章
- SQL Server on Linux 理由浅析
SQL Server on Linux 理由浅析 今天的爆炸性新闻<SQL Server on Linux>基本上在各大科技媒体上刷屏了 大家看到这个新闻都觉得非常震精,而美股,今天微软开 ...
- 【深入浅出jQuery】源码浅析--整体架构
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- netty5 HTTP协议栈浅析与实践
一.说在前面的话 前段时间,工作上需要做一个针对视频质量的统计分析系统,各端(PC端.移动端和 WEB端)将视频质量数据放在一个 HTTP 请求中上报到服务器,服务器对数据进行解析.分拣后从不同的 ...
- Jvm 内存浅析 及 GC个人学习总结
从诞生至今,20多年过去,Java至今仍是使用最为广泛的语言.这仰赖于Java提供的各种技术和特性,让开发人员能优雅的编写高效的程序.今天我们就来说说Java的一项基本但非常重要的技术内存管理 了解C ...
- 从源码浅析MVC的MvcRouteHandler、MvcHandler和MvcHttpHandler
熟悉WebForm开发的朋友一定都知道,Page类必须实现一个接口,就是IHttpHandler.HttpHandler是一个HTTP请求的真正处理中心,在HttpHandler容器中,ASP.NET ...
- 【深入浅出jQuery】源码浅析2--奇技淫巧
最近一直在研读 jQuery 源码,初看源码一头雾水毫无头绪,真正静下心来细看写的真是精妙,让你感叹代码之美. 其结构明晰,高内聚.低耦合,兼具优秀的性能与便利的扩展性,在浏览器的兼容性(功能缺陷.渐 ...
- 浅析匿名函数、lambda表达式、闭包(closure)区别与作用
浅析匿名函数.lambda表达式.闭包(closure)区别与作用 所有的主流编程语言都对函数式编程有支持,比如c++11.python和java中有lambda表达式.lua和JavaScript中 ...
- word-break|overflow-wrap|word-wrap——CSS英文断句浅析
---恢复内容开始--- word-break|overflow-wrap|word-wrap--CSS英文断句浅析 一 问题引入 今天在再次学习 overflow 属性的时候,查看效果时,看到如下结 ...
- 编写轻量ajax组件02-AjaxPro浅析
前言 上一篇介绍了在webform平台实现ajax的一些方式,并且实现一个基类.这一篇我们来看一个开源的组件:ajaxpro.虽然这是一个比较老的组件,不过实现思想和源码还是值得我们学习的.通过上一篇 ...
随机推荐
- spring-ai 学习系列(7)-MCP 安全认证
继续先前的MCP学习,实际企业级应用中,很多信息都是涉及商业敏感数据,需要考虑安全认证,不可能让MCP Server在网上裸奔.spring web开发中,提供了拦截器功能,最简单的思路,在Clien ...
- Rust中的匿名函数与闭包
一.匿名函数 语法:"|参数名| 语句" 参考下面的这个示例: fn add(a: i32, b: i32) -> i32 { a + b } fn main() { let ...
- 图论 III
本文主要讲解:网络流,二分图染色,2-sat,差分约束 定义与记号 基本定义 图:一张图 \(G\) 由若干个点和连接这些点的边构成.点的集合称为 点集 \(V\),边的集合称为 边集 \(E\),记 ...
- 2023年7月最新全国省市区县和乡镇街道行政区划矢量边界坐标经纬度地图数据 shp geojson json
发现个可以免费下载全国 geojson 数据的网站,推荐一下.支持全国.省级.市级.区/县级.街道/乡镇级以及各级的联动数据,支持导入矢量地图渲染框架中使用,例如:D3.Echarts等 geojso ...
- unity A星寻路教程
核心代码 使用说明: 需要自行设置,地图数据,起点,终点 直接调用 AStarPath.FindPath 即可 using System.Collections; using System.Co ...
- 虚拟机-Linux开发板交叉编译问题记录
遇到一堆很久之前见过的问题,重新解决一次. 1.虚拟机没法上网 发现虚拟机浏览器上不了网,运行ifconfig查看,发现要么没有IP地址,要么只有IPv6的地址.最后发现是昨天VMware卡死了,启动 ...
- MySQL Group Replication (MGR) 主节点故障自动切换和选举过程
MySQL Group Replication (MGR) 在主节点(单主模式下)故障时,其自动故障切换(Failover) 的核心在于其分布式故障检测机制和基于最新数据的共识选举 ...
- DHTMLX Gantt 甘特图导出全数据图/PDF-----使用官方方法
注意:以下方案是DHTMLX Gantt官方提供的免费版调用接口,需要在线联网访问官网export.dhtmlx.com 的服务器,断网或内网局域网用不了该免费版调用接口.最近有个需求,将项目甘特图导 ...
- CsGrafeq:用C#实现一个几何画板
简介 CsGrafeq是一项用C# AvaloniaUI实现的开源几何画板,支持AOT发布, 无需安装 .NET Core 运行时,无需携带大量动态链接库. CsGrafeq目前支持的几何图形包含线, ...
- 管中窥豹----.NET Core到.NET 8 托管堆的变迁
https://www.cnblogs.com/lmy5215006/p/18515971 在研究.NET String底层结构时,我所观察到的情况与<.NET Core底层入门>,< ...