CDP与Selenium相结合——玩转网页端自动化数据采集/爬取程序
Selenium
Selenium 是一款开源且可移植的自动化软件测试工具,专门用于测试网页端应用程序或者采集网页端数据。它能够在不同的浏览器和操作系统上运行,具有很强的跨平台能力。Selenium可以帮助测试人员更高效地自动化测试基于Web网页端的应用程序,也可以帮忙开发者方便地完成网页端数据的采集工作。
Chrome Dev Tools
Chrome Dev Tools 是直接内置于 Chrome 浏览器中的调试工具。它为开发人员提供了一整套用于检查、调试、分析和优化 Web 网页端应用程序的工具。下面举例讲述 Chrome Dev Tools 支持的一些功能:
元素选项卡
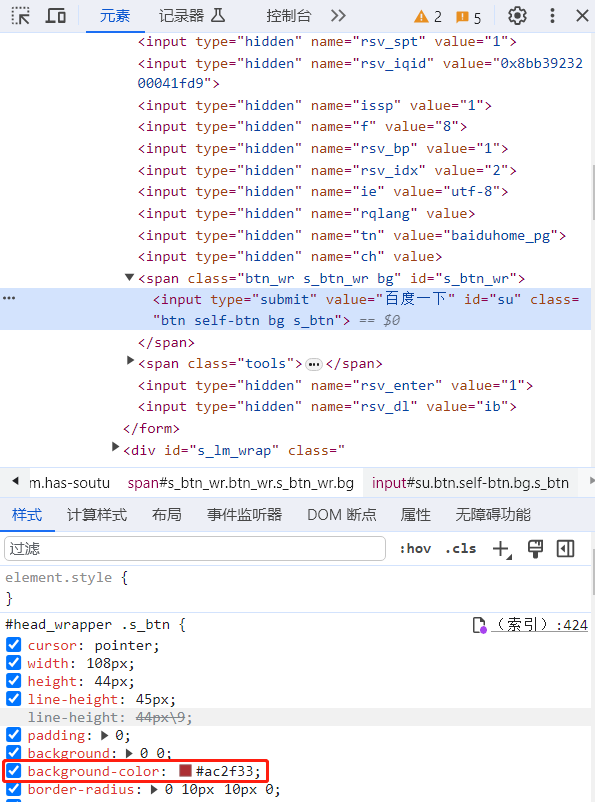
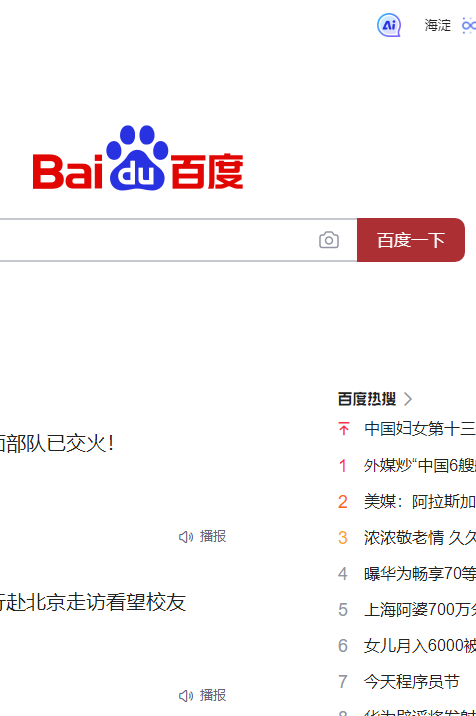
元素选项卡可以显示当前页面的 DOM 树,使用者也可以通过该功能实时修改当前页面的 DOM 树。举例来讲,我们现在想修改百度搜索按钮背景颜色成红色,我们就可以通过元素选项卡来完成。我们在元素选项卡中选中搜索框的按钮并且将 background-color 样式设置为红色即可,下方截图是实现的效果。
控制台选项卡
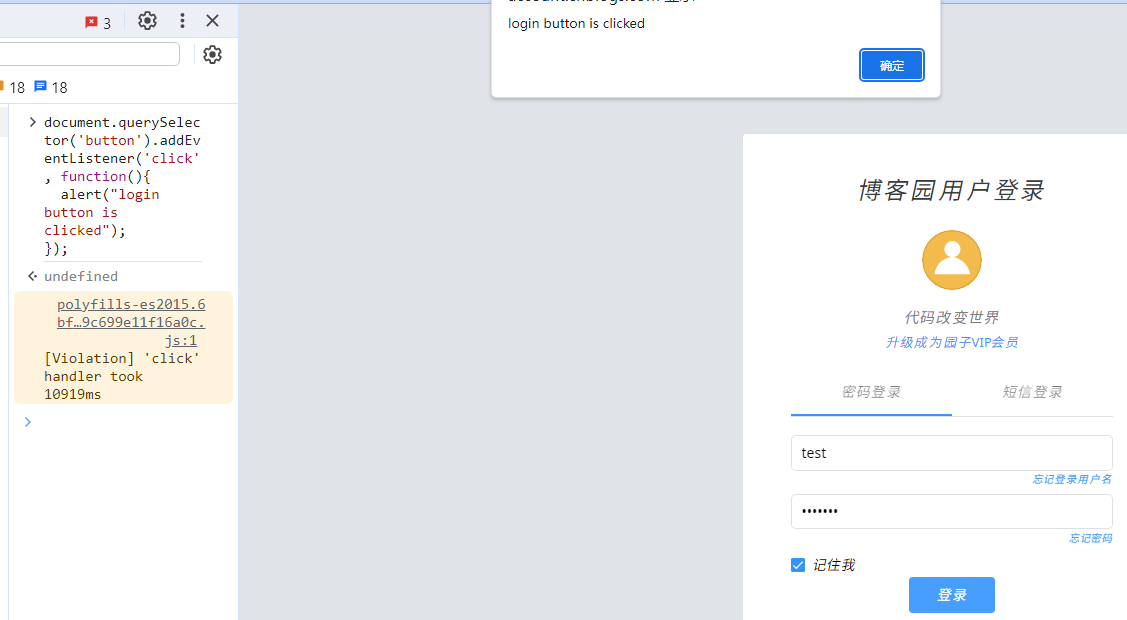
控制台选项卡类似于交互式的终端,我们可以在这里看到JavaScript代码打印的日志信息,方便我们定位问题,也可以在这里输入 JavaScript 代码,并且可以让这些代码实时生效,甚至改变原有网页的行为。例如,我们打开某个网站的登录页面并且在控制台选项卡中输入如下的代码:
document.querySelector('button').addEventListener('click', function(){
alert("login button is clicked");
});
通过网页中注入上面的代码,我们可以监控到该页面上面所有 button 元素的点击操作,当用户点击登录按钮的时候就会弹窗显示消息“login button is clicked”。具体情形如下图所示:
源代码选项卡
源代码选项卡可以查看完整的网页源代码,对源代码进行单步调试,观察代码的调用堆栈,也可以动态修改代码变量。为了能够更加清晰地说明源代码选项卡的作用,我简单编写了一个 HTML 页面。其内容如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>example page 1</title>
</head>
<body>
<input type = "button" value = "点击我" onclick = "hello('World')" />
<script>
function hello(name) {
let phrase = `Hello, ${name}!`;
say(phrase);
}
function say(phrase) {
alert(phrase);
}
</script>
</body>
</html>
首先,我们在 Chrome 浏览器中打开上面的网页内容,进入到开发者工具,切换到源代码选项卡,我们会看到下面的视图:
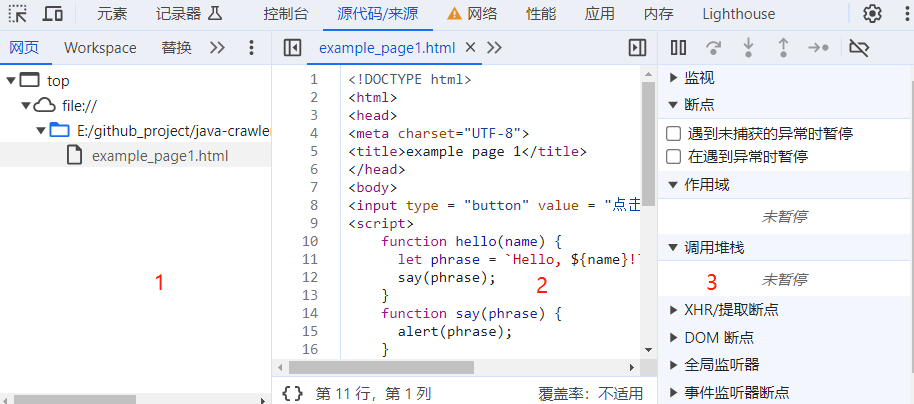
如上图所示,源代码选项卡主要由3个部分组成:
文件导航窗口:文件导航窗口中列举了整个网页相关的文件列表和路径,主要包括:HTML,JavaScript,CSS 和浏览器扩展插件等。
代码编辑窗口:源代码选项卡的第二个窗口是一个源代码编辑器,我们可以在这里查看和编辑各个文件的源代码,也可以在这里设置调试断点。
调试信息窗口:调试信息窗口展示了当前设置的断点信息和调用堆栈信息等。
我们有两种方法可以给当前页面的代码设置断点。
设置断点的第一种方法是在代码编辑窗口中点击对应的行号设置断点。具体视图如下所示:
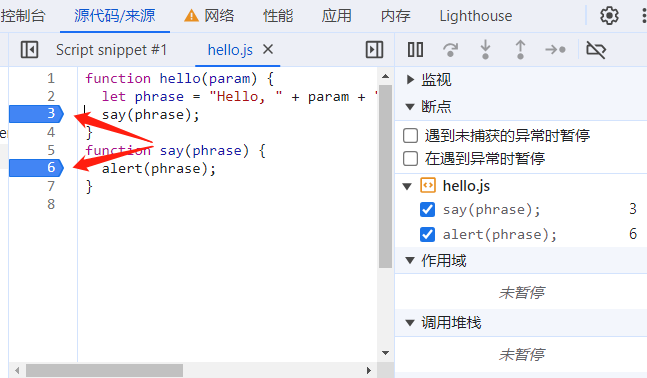
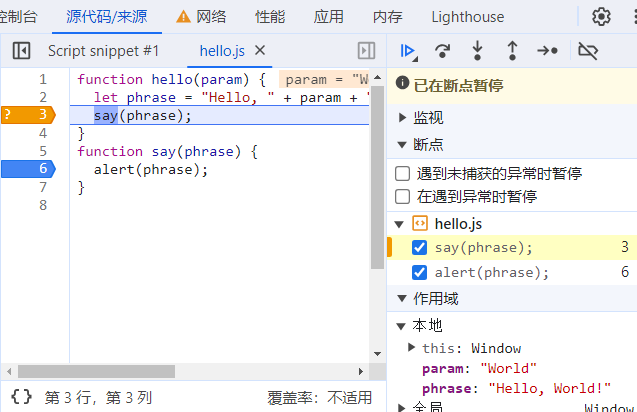
调试信息窗口中会展示我们设置的所有断点信息。除了设置普通的断点,我们还可以设置条件断点(Conditional Breakpoints)。现在,我们将上图中的第一个断点修改为条件断点,设置只有当 param 变量等于 World 的时候才会触发断点。设置后的效果如下图所示:
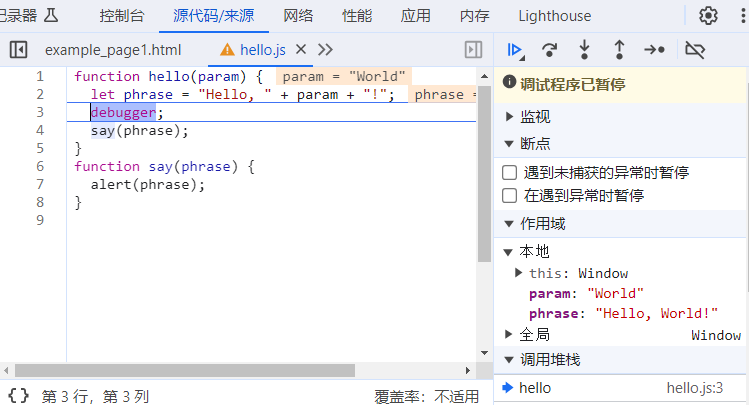
设置断点的第二种方式是直接在代码编辑窗口中插入 debugger 命令。具体效果如下图所示:
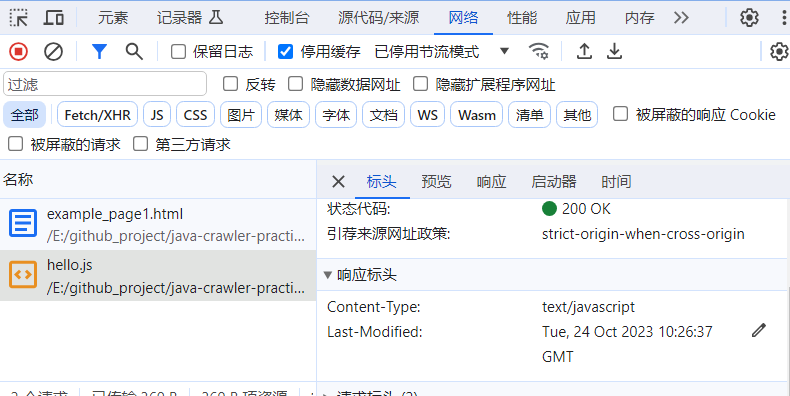
网络选项卡
通过网络选项卡,我们可以观察到网络流量的情况以及网络的请求和响应。对于爬虫开发者来说,最感兴趣的内容应该是各个文件的具体请求和响应信息。通过网络选项卡,我们会看到浏览器实时发送和接收的每个请求。通过点击每个请求,我们可以可以访问请求和响应的具体信息,cookie 和耗时等。
Chrome DevTools Protocol (CDP)
Chrome DevTools Protocol(CDP)是一套用于与基于Chromium内核浏览器进行通信的 API。它允许开发者通过发送命令和接收事件来与浏览器进行交互,以实现自动化测试、性能分析、调试等功能。CDP 在自动化测试、前端开发和爬虫程序开发等很多领域都发挥着重要的作用。
Chrome 浏览器的开发者将 Chrome DevTools 的功能领域划分为大约50个,每个版本的浏览器支持的功能领域可能会有些许差异。具体的功能领域划分我们可以通过官方文档链接进行查询,https://chromedevtools.github.io/devtools-protocol/。打开浏览器的开发者工具,我们可以开启实验特性下的协议监视器(protocol monitor)功能来查看当前浏览器页面发送的所有 CDP 指令。
Selenium与CDP协议结合使用
在 Selenium 4 框架中,提供了两种与 Chrome Devtools 进行交互的方法,分别是 DevTools.send 方法和 ChromiumDriver.executeCdpCommand 方法。
DevTools 是 Selenium 框架为 CDP 协议编写的一个封装类,它内置了部分 CDP 协议指令。
ChromiumDriver 对象中的 executeCdpCommand 方法则是根据 CDP 协议指令的定义采用更加原始的方式直接向 Chrome 浏览器内核发送 CDP 协议指令。两种发送指令方式的差异性如下图所示:

接下来,我们分别采用DevTools.send方法和ChromiumDriver.sendCdpCommand方法来发送CDP协议指令来展示Selenium与CDP协议是如何结合在一起使用的。
示例1:捕获网络请求数据和网络响应数据
首先,我们来看一看如何使用 DevTools 对象来操作 CDP 协议指令。假设,我们在进行数据采集的时候,希望能够实时记录某一个网站针对特定 URL 的请求数据和响应数据。这个时候,我们可以利用 CDP 协议中的 Network 领域功能来跟踪页面的相关网络活动。要实现捕获网络请求和响应数据的功能,我们首先需要使用 Network.enable 方法来开启页面的网络活动追踪功能,然后监听 Network.requestWillBeSent 事件和 Network.responseReceived 事件。具体代码示例如下所示:
DevTools devTools = chromeDriver.getDevTools();
devTools.createSession();
devTools.send(Network.enable(Optional.empty(), Optional.empty(), Optional.empty()));
ThreadUtils.sleepQuietly(Duration.ofSeconds(5));
devTools.addListener(Network.responseReceived(), response -> {
if(response.getResponse().getUrl().contains("token") || response.getResponse().getUrl().contains("userinfo")) {
String url = response.getResponse().getUrl();
String responseBody = devTools.send(Network.getResponseBody(response.getRequestId())).getBody();
System.out.println(String.format("request url & response body: %s, %s", url, responseBody));
}
});
chromeDriver.get("https://www.cnblogs.com/");
执行上述代码之后,我们会得到如下所示的打印结果。

示例2:打印网页内容
在第二个示例中,我们采用 executeCdpCommand 方法来直接发送 CDP 指令给浏览器内核。假设我们现在使用的是 v96 版本的 Chrome 浏览器,与该版本浏览器对应的 Selenium DevTools 包装类中并不支持 Page.printToPDF 的 CDP 协议指令,这样我们就不得不使用 executeCdpCommand 方法来直接发送 CDP 协议指令。
首先,我们打开链接:https://chromedevtools.github.io/devtools-protocol/tot/Page/#method-printToPDF,查看具体的 Page.printToPDF 指令定义。
了解完指令定义之后,我们就可以按照指令定义来编写相关代码,具体代码示例如下所示:
chromeDriver.get("https://www.cnblogs.com/");
Thread.sleep(3000);
Map<String, Object> params = Maps.newHashMap();
params.put("displayHeaderFooter", true);
params.put("paperWidth", 11.0f);
params.put("headerTemplate", "<div style= \"font-size: 8px;\"> <span class=\"url\"></span></div>");
Map<String, Object> response = chromeDriver.executeCdpCommand("Page.printToPDF", params);
Path destination = Paths.get("fullpage-screenshot-chrome.pdf");
Files.write(destination, Base64.getDecoder().decode(response.get("data").toString()));
chromeDriver.quit();
上述代码执行之后,我们会得到一个 PDF 文件。
总结
本文介绍了有关 Chrome DevTools,Chrome DevTools Protocol 以及 Selenium 与 CDP 协议结合应用的一些基本知识。希望它可以您在编写自动化爬取/采集程序的时候帮助到您。
另外,更多有关网络数据采集\爬取、验证码识别和逆向分析等相关知识,可以阅读我最近出版的《Java网络爬虫精解与实践》一书,该书知识结构紧凑,内容覆盖全面。
另外,该书还提供了对应的网络数据采集训练平台:https://benshu.tech/crawler。
CDP与Selenium相结合——玩转网页端自动化数据采集/爬取程序的更多相关文章
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- selenium自动化方式爬取豆瓣热门电影
爬取的代码如下: from selenium import webdriver from bs4 import BeautifulSoup import time #发送请求,获取响应 def get ...
- JS+Selenium+excel追加写入,使用python成功爬取京东任何商品~
之前一直是requests库做爬虫,这次尝试下使用selenium做爬虫,效率不高,但是却没有限制,文章是分别结合大牛的selenium爬虫以及excel追加写入操作而成,还有待优化,打算爬取更多信息 ...
- selenium模拟浏览器对搜狗微信文章进行爬取
在上一篇博客中使用redis所维护的代理池抓取微信文章,开始运行良好,之后运行时总是会报501错误,我用浏览器打开网页又能正常打开,调试了好多次都还是会出错,既然这种方法出错,那就用selenium模 ...
- c++ 实现https网页上的图片爬取
一.主要的原理 我们通过发送一个http请求,获得目标网页的html源代码,然后通过正则表达式获取到图片的URL,把该网页的所有的图片都保存到一个文件夹,这就是整个软件的流程. 二.具体的实践 现在很 ...
- 【Beta】“北航社团帮”发布声明——小程序v2.0与网页端v1.0
目录 Beta版本新功能 小程序v2.0新功能 新功能列表 功能详情图 新功能动图展示 网页端v1.0功能 登录方式 社团信息的修改 新闻的录入和修改 活动的录入和修改 这一版修复的缺陷 Beta版本 ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- Selenium+PhantomJs 爬取网页内容
利用Selenium和PhantomJs 可以模拟用户操作,爬取大多数的网站.下面以新浪财经为例,我们抓取新浪财经的新闻版块内容. 1.依赖的jar包.我的项目是普通的SSM单间的WEB工程.最后一个 ...
随机推荐
- 痞子衡嵌入式:JLink命令行以及JFlash对于下载算法的作用地址范围认定
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是JLink命令行以及JFlash对于下载算法的作用地址范围认定. 最近痞子衡在给一个 RT1170 客户定制一个 Infineon Mi ...
- About CSP
好了,猜猜今年第一题会考什么 linux 终端指令 这样吧 CTH 装了 ubuntu 系统的电脑被人施加了 rm -rf /home/Desktop/ 指令,导致他打不开桌面了,以下哪一个是 CTH ...
- Sqoop简介安装及使用
Sqoop简介 sqoop 是 apache 旗下一款"Hadoop 和关系数据库服务器之间传送数据"的工具. 核心的功能有两个: 导入.迁入 导出.迁出 导入数据:MySQL,O ...
- 北京智和信通PON.EPON.GPON运维解决方案,全面管理OLT.ONU等设备
高质量.高可靠.高安全性的网络已成为助力企事业单位高速发展的基石.PON网络采用先进的无源光纤通信技术与自动化融合,构建新兴一体化网络体系,可以有效构造安全可靠的生产办公网络.因此,交通.制造.能源. ...
- icache的dcache区别
iCache是指指令缓存,DCache是指数据缓存.iCache是专门用于存储指令的高速缓存,DCache是用于存储数据的高速缓存.iCache用于存储指令,在CPU执行时将指令从iCache中读取, ...
- 有没有开发过⼀些vue插件?举例说说 - 批量引入插件
有过,项⽬开发的时间⻓了,沉淀了不少业务通⽤全局组件,想把他们统⼀进⾏注册,就封装了⼀个⼩ 插件 当时其实⼀开始也没有什么思路,后来扒了⼀下 elementUI的源码,仿了⼀下它的写法,流程我还⼤概记 ...
- 在Java程序中监听mysql的binlog
目录 1.背景 2.mysql-binlog-connector-java简介 3.准备工作 1.验证数据库是否开启binlog 2.开启数据库的binlog 3.创建具有REPLICATION SL ...
- HDU-ACM 2024 Day3
T1004 游戏(HDU 7460) 注意到对于两个人,他们 \(t\) 轮后能力值相同的概率只与他们初始时的能力差有关,所以我们先 \(\text{FFT}\) 求出 \(|a_i - a_j| = ...
- 云原生爱好者周刊:K8s Security SIG 发布 Kubernetes 策略管理白皮书
云原生一周动态要闻: Istio 1.13 发布 CNCF 宣布 2021 年云原生调查结果 运行时安全项目 Falco 添加可扩展插件框架 Grafana 8.3.6 发布 开源项目推荐 文章推荐 ...
- 操作系统_MPI程序设计
一.实验环境搭建 本次MPI集群环境是在电脑中安装mpi的sdk和应用程序后在visual studio 2022 上配置MPI环境. VC++目录--->包含目录--->添加MPI的in ...