selenium自动化方式爬取豆瓣热门电影
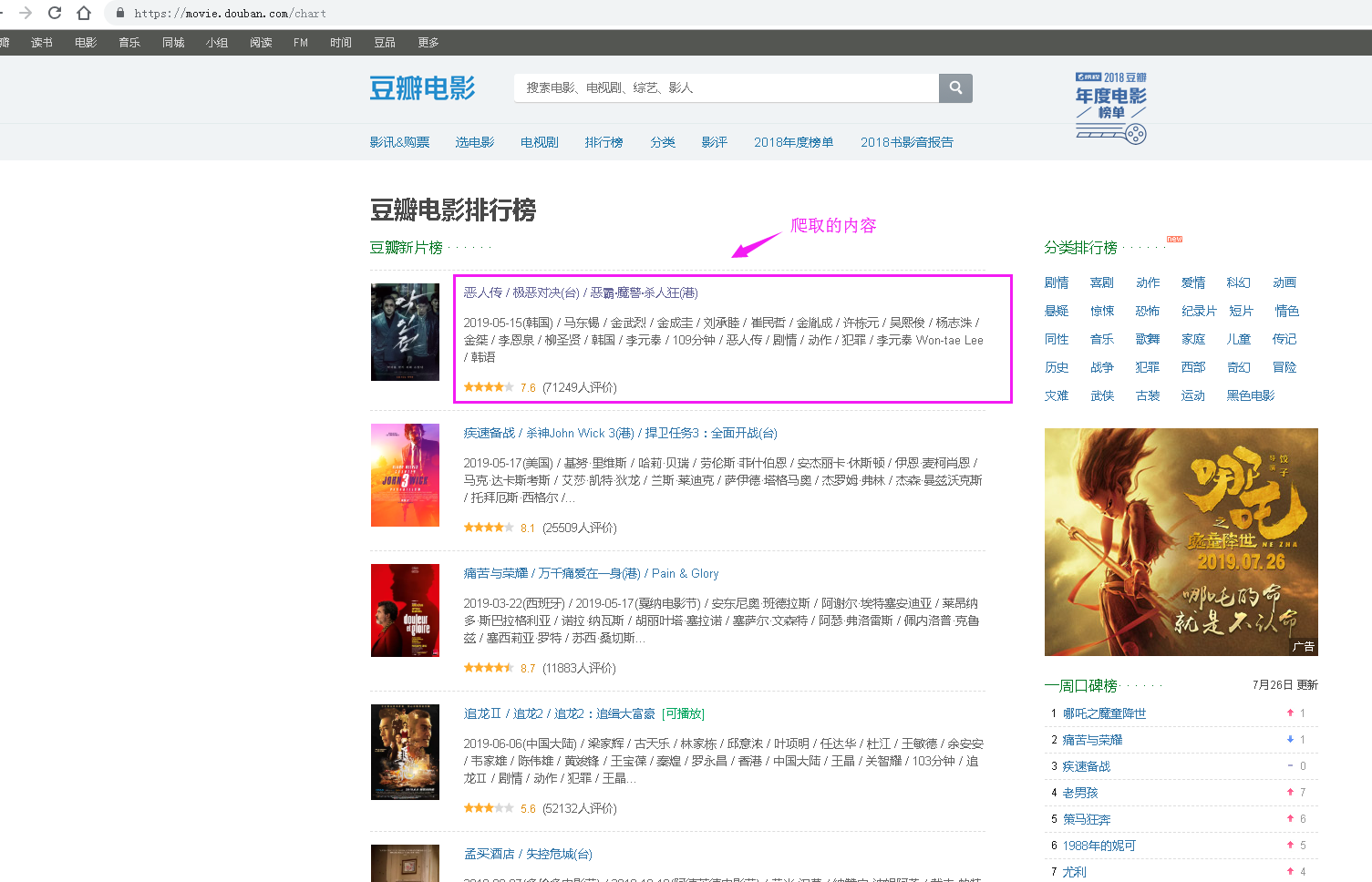
爬取的代码如下:
from selenium import webdriver
from bs4 import BeautifulSoup
import time
#发送请求,获取响应
def get_PageItem():
# 准备url
url='https://movie.douban.com/chart'
#创建一个浏览器对象
driver=webdriver.Chrome()
#发送请求
driver.get(url)
#print(driver.page_source)
page_code=BeautifulSoup(driver.page_source,"lxml")
#print(page_code)
#获取所有的inden类下面的所有table标签
items=page_code.select('.indent table')
return items def start():
"""启动程序"""
#获取当前时间
start_time=time.time()
#接收table标签
items=get_PageItem()
print("用时:",time.time()-start_time,"秒")
for item in items:
#查找电影标题 找到P12的div里面的a标签
name1=item.select("div.pl2 a")[0].text #也可以写成:name=item.select(".p12 a")[0].text
name2=name1.replace(" ","").replace("\n","")
#获取演员列表,上映时间和电影类型
time_person=item.select(".pl")[0].text
#获取评价人数
num=item.select("span.pl")[0].text
#获取评分
score=item.select("span.rating_nums")[0].text
get_star(score)
with open("a.txt",'a',encoding = 'utf-8')as f:#使用with open在使用完成后会直接进行关闭,而直接使用open在使用完成后需要进行关闭,否则会占用内存
f.write("%s\n%s\n%s\n%s\n"%
("电影名称:%s"%name2,
"演员列表:%s"%time_person,
"评分和人数%s%s%s"%(get_star(score),score,num),
"*"*200)) #根据评分显示星星数量
def get_star(score):
#打印出score的数据类型,在python中只有相同的数据类型才能进行乘法和除法操作。
#print(type(score))#打印出来,score是str类型,str类型是不能进行乘法和除法的操作
str1=''
for i in range(0,5):
# # 把score进行强转,转成float类型
if int(float(score)/2 )>i:
str1+="★"
else:
str1 += "☆"
return str1 start()
执行代码后,在a.txt文档中存放爬取的内容如下:

selenium自动化方式爬取豆瓣热门电影的更多相关文章
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- requests库爬取豆瓣热门国产电视剧数据并保存到本地
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subject ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python3爬取豆瓣top250电影
需求:爬取豆瓣电影top250的排名.电影名称.评分.评论人数和一句话影评 环境:python3.6.5 准备工作: 豆瓣电影top250(第1页)网址:https://movie.douban.co ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- 爬虫之爬取豆瓣top250电影排行榜及爬取斗图啦表情包解读及爬虫知识点补充
今日内容概要 如何将爬取的数据直接导入Excel表格 #如何通过Python代码操作Excel表格 #前戏 import requests import time from openpyxl impo ...
- 爬取豆瓣TOP250电影
自己跟着视频学习的第一个爬虫小程序,里面有许多不太清楚的地方,不如怎么找到具体的电影名字的,那么多级关系,怎么以下就找到的是那个div呢? 诸如此类的,有许多,不过先做起来再说吧,后续再取去弄懂. i ...
随机推荐
- react+redux+react-redux练习项目
一,项目目录 二.1.新建pages包,在pages中新建TodoList.js: 2.新建store包,在store包中新建store.js,reducer.js,actionCreater.js, ...
- LeetCode第一题—— Two Sum(寻找两数,要求和为target)
题目描述: Given an array of integers, return indices of the two numbers such that they add up to a speci ...
- Python-基本运算符与流程控制
目录 基本运算符 算术运算符 比较运算符 赋值运算符 逻辑运算符 身份运算符 位运算符 成员运算符 运算符优先级 流程控制 if 判断 单分支结构 双分支结构 多分支结构 while 循环 while ...
- laravel框架中使用QueryList插件采集数据
laravel框架中使用queryList 采集数据 采集数据对我们来说真家常便饭,那么苦苦的写正则采集那么一点点东西,花费了自己大把的时间和精力而且没有一点技术含量,这个时候就是使用我们的好搭档Qu ...
- HOOK NtCreateSection
本程序使用了hde32反汇编引擎,所以性能更加稳定! #pragma once #include <ntddk.h> NTSYSAPI NTSTATUS NTAPI NtCreateSec ...
- SPSS实例教程:多重线性回归,你用对了么
SPSS实例教程:多重线性回归,你用对了么 在实际的医学研究中,一个生理指标或疾病指标往往受到多种因素的共同作用和影响,当研究的因变量为连续变量时,我们通常在统计分析过程中引入多重线性回归模型,来分析 ...
- Django自带的认证系统
Django自带的用户认证 我们在开发一个网站的时候,无可避免的需要设计实现网站的用户系统.此时我们需要实现包括用户注册.用户登录.用户认证.注销.修改密码等功能,这还真是个麻烦的事情呢. Djang ...
- Android笔记之让Debug和Release模式使用相同的签名
方法如下图 完整的build.gradle如下 apply plugin: 'com.android.application' android { compileSdkVersion 29 build ...
- Spring Cloud各组件
讲的不错:http://www.ityouknow.com/springcloud/2017/05/16/springcloud-hystrix.html Spring Cloud技术应用从场景上可以 ...
- 从NoSQL到NewSQL数据库