Python实现KNN算法
Python实现Knn算法
关键词:KNN、K-近邻(KNN)算法、欧氏距离、曼哈顿距离
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
KNN算法的思想总结:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
#coding:utf-8
import requests, json, time, re, os, sys, time
import urllib2
import random
import numpy as np #设置为utf-8模式
reload(sys)
sys.setdefaultencoding( "utf-8" ) #读取文本文件,构建二维数组
def readDataFile(filename,format):
if format:
pass
else:
format = ','
list = []
#去除首位空格
filename = filename.strip()
#判断数据文件是否存在
if os.path.isfile(filename):
pass
file_object = open(filename,'rb')
lines = file_object.readlines()
for line in lines:
tmp = []
line = line.strip()
for value in line.split(format)[:-1]:
tmp.append(float(value))
tmp.append(line.split(format)[-1])
list.append(tmp)
else:
print "%s is not exists " % (filename)
return list #读取文本数据,拆分原始数据为特征和标签,返回特征值和标签值
def createData(filename,format=','):
data_label = readDataFile(filename,format)
if len(data_label) > 0:
label = []
data = []
#data_label = [[1,100,123,'A'],[2,99,123,'A'],[100,1,12,'B'],[99,2,23,'B']]
for each in data_label:
label.append(each[-1])
data.append(each[:-1])
return data,label #根据输入数据和测试数据,进行分类
def calculateDistance(input,data,label,k):
classes = 'Error' if len(data[0])==0 or len(label) == 0:
print 'data or label is null'
pass
elif k > len(data) :
print "k : %s is out of bounds" % (k)
pass
elif len(input) <> len(data[0]):
print "特征变量值不够,输入变量特征个数为:%s,训练特征变量个数为:%s" % (len(input),len(data[0]))
pass
else:
result = []
length = len(input)
for i in range(len(data)):
sum = 0
for j in range(length):
#pow(5,2) 标识5的平方为25,取两点之间的距离的平方并累加
sum = sum + pow(input[j] - data[i][j],2)
#取平方根
sum = pow(sum,0.5)
result.append(sum)
#print result
result = np.array(result) #argsort()根据元素的值从小到大对元素进行排序,返回下标
sortedDistIndex = np.argsort(result) #统计前k个数中各个标签的个数
classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
#dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回默认值None。
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes filename = '/home/shutong/jim/crawl/data.csv'
data,label = createData(filename)
input = [1,20]
k = 4
result = calculateDistance(input,data,label,k)
print input,result
其中测试数据如图:
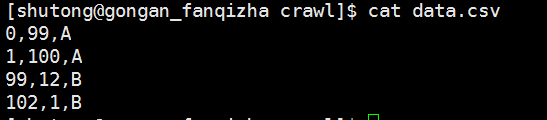
输入数据为:input = [1,20],预测它的标签为A还是B?
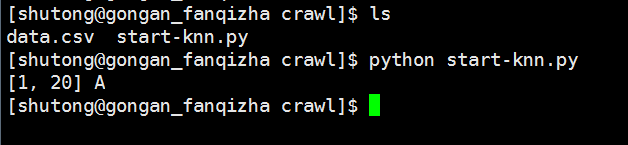
最终预测结果为:A
Python实现KNN算法的更多相关文章
- Python实现KNN算法及手写程序识别
1.Python实现KNN算法 输入:inX:与现有数据集(1xN)进行比较的向量 dataSet:已知向量的大小m数据集(NxM) 个标签:数据集标签(1xM矢量) k:用于比较的邻居数 ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- ML一:python的KNN算法
(1):list的排序算法: 参考链接:http://blog.csdn.net/horin153/article/details/7076321 示例: DisListSorted = sorted ...
- 利用Python实现kNN算法
邻近算法(k-NearestNeighbor) 是机器学习中的一种分类(classification)算法,也是机器学习中最简单的算法之一了.虽然很简单,但在解决特定问题时却能发挥很好的效果.因此,学 ...
- 基于python 实现KNN 算法
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/11/7 14:50 # @Author : gylhaut # @Site ...
- 吴裕雄 python 机器学习-KNN算法(1)
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, ...
- knn算法详解
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习回顾篇(6):KNN算法
1 引言 本文将从算法原理出发,展开介绍KNN算法,并结合机器学习中常用的Iris数据集通过代码实例演示KNN算法用法和实现. 2 算法原理 KNN(kNN,k-NearestNeighbor)算法, ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
随机推荐
- ocx控件针对网页刷新和关闭分别进行区分处理
当ocx加载在网页上时,如果对网页执行F5刷新事件,ocx控件会销毁ocx的窗口类,但是ocx的APP类是不会销毁的. 只有当网页被关闭时,才销毁app类. --------------------- ...
- 你是真的了解ssh吗 说说你不知道的ssh
Ssh命令——基石天赋 主要参数说明: -l 指定登入用户 -p 设置端口号 -f 后台运行,并推荐加上 -n 参数 -n 将标准输入重定向到 /dev/null,防止读取标准输入 -N 不执行远程命 ...
- laravel的模型关联之(一对多的反向)
一对多的反向 一对多的反向就相当于,一个用户有多篇文章,但是在显示文章模型的时候你又想显示这个用户的用户名,但是你只有用户id, 这时候就用到了一对多的反向,你用用户(User)模型里面定义了一对多来 ...
- LoadRunner Controller
1.Controller的引入 1)需要Controller的原因?需要多个用户来模拟并发的时候. 2)一种强大的.成熟的工具的体现. 2. Controller的启动方式 1)LoadRunner ...
- 485. Max Consecutive Ones最长的连续1的个数
[抄题]: Given a binary array, find the maximum number of consecutive 1s in this array. Example 1: Inpu ...
- 2-chrome无法添加扩展程序
1.更多工具->拓展程序->打开开发者模式->重启浏览器 2.将拓展程序拖入,确认安装
- Android NDK打印log到logcat的方法
头文件 : <android/log.h> 函数: __android_log_print(ANDROID_LOG_XXX,LOG_TAG,content) 第一个参数是Log级别,比如: ...
- Linux mii-tool命令
一.简介 mii-tool 是一个用来查看,管理介质的网络接口的状态的工具. 二.选项 usage: mii-tool [-VvRrwl] [-A media,... | -F media] [int ...
- Laravel Gate 授权方式的使用指南
参考链接:An Introduction to Laravel Authorization Gates 本文使用 Laravel 的 Gate 授权方式 实现一个基于用户角色的博客发布系统. 在系统包 ...
- IDEA+DevTools实现热部署功能
开发IDE: Intellij IDEA 2018.1 SpringBoot:1.5.9.RELEASE 热部署 大家都知道在项目开发过程中,常常会改动页面数据或者修改数据结构,为了显示改动效果, ...