Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评
爬虫主程序:
import scrapy
from ..items import DoubanmovieItem class MoviespiderSpider(scrapy.Spider):
name = 'moviespider'
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/top250'] def parse(self, response):
movie_items=response.xpath('//div[@class="item"]')
for item in movie_items:
#print(type(item)) movie =DoubanmovieItem()
movie['rank']=item.xpath('div[@class="pic"]/em/text()').extract()
movie['title']=item.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"][1]/text()').extract()
movie['quote'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"][1]/text()').extract()
movie['star'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract() movie['src']=item.xpath(
'div[@class="pic"]/a/img/@src').extract() yield movie
pass #取下一页的地址
nextPageURL = response.xpath('//span[@class="next"]/a/@href').extract()
#print(nextPageURL)
if nextPageURL:
url = response.urljoin(nextPageURL[-1])
#print('url', url)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
items 对象
import scrapy class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank=scrapy.Field()
title=scrapy.Field()
quote=scrapy.Field()
star=scrapy.Field()
src=scrapy.Field()
pass
pipelines 输出管道
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
print('电影排名:{0}'.format(item['rank'][0]))
print('电影名称:{0}'.format(item['title'][0]))
print('电影短评:{0}'.format(item['quote'][0]))
print('评价分数:{0}'.format(item['star'][0]))
print('评价人数:{0}'.format(item['star'][1]))
print('图片链接:{0}'.format(item['src']))
print('-' * 20)
return item
在控制台输出的结果
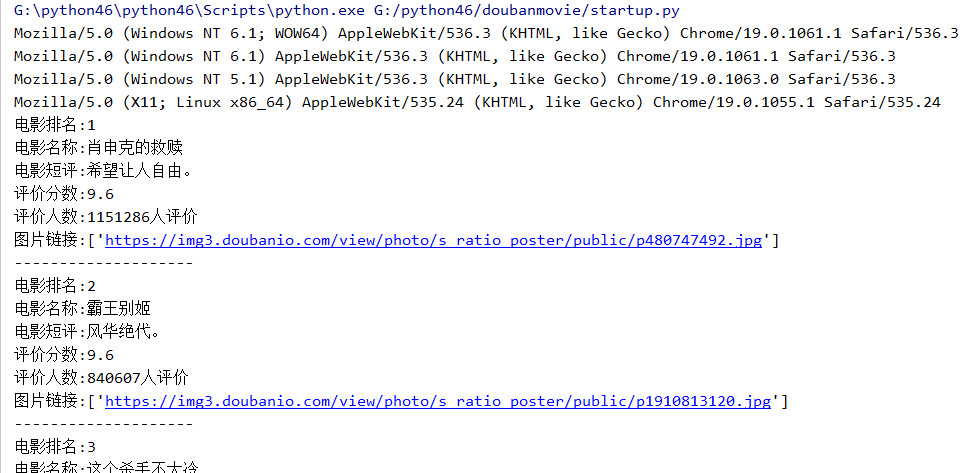
可以通过爬出的图片链接,下载电影的剧照,这就另说了,也可以设置一个插入数据库的管道,将这些数据插入到数据库中
Python的scrapy之爬取豆瓣影评和排名的更多相关文章
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- [超详细] Python3爬取豆瓣影评、去停用词、词云图、评论关键词绘图处理
爬取豆瓣电影<大侦探皮卡丘>的影评,并做词云图和关键词绘图第一步:找到评论的网页url.https://movie.douban.com/subject/26835471/comments ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
随机推荐
- pdf2swf 转换时报错。This file is too complex to render- SWF only supports 65536 shapes at once
在使用swftools转换pdf 到swf的时候报错,有如下说明:if the pdf contains too many images / shapes, pdf2swf will fail wit ...
- geth访问公有链
同步以太坊,配置rpc地址 mkdir /opt/blockchain nohup geth --syncmode "fast" --cache=1024 --maxpeers 3 ...
- 基于配置的Spring AOP
前面几篇学习了Spring的依赖注入,这篇开始学习另一个核心功能——面向切面编程AOP. 通过本文,你可以了解到: 1 Spring xml规范 2 通过配置文件实现面向切面编程 3 对比与传统AOP ...
- Oracle 12C配置EM
12C配置OEM同之前的版本差别较大,没有了emctl,而是直接使用如下方法配置: SQL*Plus: Release 12.1.0.2.0 Production on Tue Jul 19 07:1 ...
- 找出OData service出错根源的小技巧
SAP的Fiori应用是通过OData和后台交互的.在使用Fiori应用时您可能会遇到这样的错误消息: 这个错误消息没有包含有助于partner或者客户定位问题根源的线索. 下面是如何在后台找出问题根 ...
- 让ADO.NET Entity Framework 支持ACCESS数据库
如写的不好请见谅,本人水平有限. 个人简历及水平:. http://www.cnblogs.com/hackdragon/p/3662599.html 接到一个程序和网页交互的项目,用ADO.NET ...
- Android(java)学习笔记33:注册广播接收者
1. 下面我们先看一部分代码,由代码进行进一步的深入: registerReceiver( new BroadcastReceiver() {//onReceive中代码的执行时间不要超过5s,and ...
- Django:ORM关系字段
一,ForeignKey 外键类型在ORM中用来表示外键关联关系,一般把ForeignKey字段设置在 '一对多'中'多'的一方. ForeignKey可以和其他表做关联关系同时也可以和自身做关联关系 ...
- Python语言程序设计基础(3)—— 基本数据类型
天天向上 dayup,dayfactor = 1.0,0.01 for i in range(365): if i % 7 in [6,0]: dayup = dayup*(1-dayfactor) ...
- Wannafly模拟赛
题目描述 给出一个n * m的矩阵.让你从中发现一个最大的正方形.使得这样子的正方形在矩阵中出现了至少两次.输出最大正方形的边长. 输入描述: 第一行两个整数n, m代表矩阵的长和宽: 接下来n行,每 ...