转:增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型
大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM)。它们具有的一个共同性质就是马尔可夫性(无后效性),也就是指系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。
马尔可夫决策过程(Markov Decision Process, MDP)也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下 棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考 虑更早之前的状态和动作,即s’是根据s和a随机生成的。
我们用一个二维表格表示一下,各种马尔可夫子模型的关系就很清楚了:
| 不考虑动作 | 考虑动作 | |
| 状态完全可见 | 马尔科夫链(MC) | 马尔可夫决策过程(MDP) |
| 状态不完全可见 | 隐马尔可夫模型(HMM) | 不完全可观察马尔可夫决策过程(POMDP) |
2. 马尔可夫决策过程
一个马尔可夫决策过程由一个四元组构成M = (S, A, Psa, R)
MDP 的动态过程如下:某个智能体(agent)的初始状态为s0,然后从 A 中挑选一个动作a0执行,执行后,agent 按Psa概率随机转移到了下一个s1状态,s1∈ Ps0a0。然后再执行一个动作a1,就转移到了s2,接下来再执行a2…,我们可以用下面的图表示状态转移的过程。
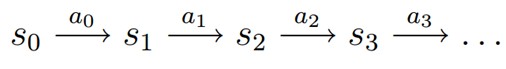
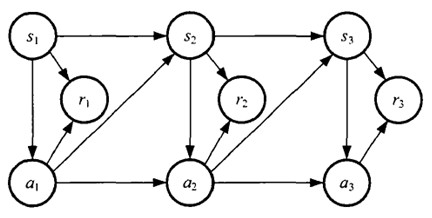
如果回报r是根据状态s和动作a得到的,则MDP还可以表示成下图:
3. 值函数(value function)
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value function,又叫效用函数)来表明当前状态下策略π的长期影响。
用Vπ(s)表示策略π下,状态s的值函数。ri表示未来第i步的立即回报,常见的值函数有以下三种:
a)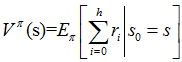
b)
c)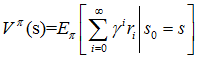
其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。接下来我们只讨论第三种形式,
现在将值函数的第三种形式展开,其中ri表示未来第i步回报,s'表示下一步状态,则有:

给定策略π和初始状态s,则动作a=π(s),下个时刻将以概率p(s'|s,a)转向下个状态s',那么上式的期望可以拆开,可以重写为:
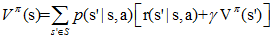
上面提到的值函数称为状态值函数(state value function),需要注意的是,在Vπ(s)中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
定义动作值函数(action value functionQ函数)如下:
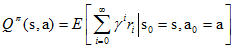
给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:
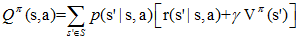
在Qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是Qπ(s,a)和Vπ(a)的主要区别。
知道值函数的概念后,一个MDP的最优策略可以由下式表示:
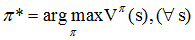
即我们寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
4. 值函数与Q函数计算的例子
上面的概念可能描述得不够清晰,接下来我们实际计算一 下,如图所示是一个格子世界,我们假设agent从左下角的start点出发,右上角为目标位置,称为吸收状态(Absorbing state),对于进入吸收态的动作,我们给予立即回报100,对其他动作则给予0回报,折合因子γ的值我们选择0.9。
为了方便描述,记第i行,第j列的状态为sij, 在每个状态,有四种上下左右四种可选的动作,分别记为au,ad,al,ar。(up,down,left,right首字母),并认为状态按动作a选择的方向转移的概率为1。
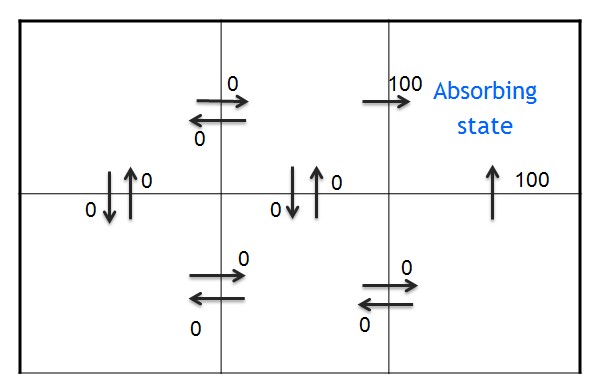
1.由于状态转移概率是1,每组(s,a)对应了唯一的s'。回报函数r(s'|s,a)可以简记为r(s,a)
如下所示,每个格子代表一个状态s,箭头则代表动作a,旁边的数字代表立即回报,可以看到只有进入目标位置的动作获得了回报100,其他动作都获得了0回报。 即r(s12,ar) = r(s23,au) =100。
2. 一个策略π如图所示:

3. 值函数Vπ(s)如下所示

根据Vπ的表达式,立即回报,和策略π,有
Vπ(s12) = r(s12,ar) = r(s13|s12,ar) = 100
Vπ(s11)= r(s11,ar)+γ*Vπ(s12) = 0+0.9*100 = 90
Vπ(s23) = r(s23,au) = 100
Vπ(s22)= r(s22,ar)+γ*Vπ(s23) = 90
Vπ(s21)= r(s21,ar)+γ*Vπ(s22) = 81
4. Q(s,a)值如下所示

有了策略π和立即回报函数r(s,a), Qπ(s,a)如何得到的呢?
对s11计算Q函数(用到了上面Vπ的结果)如下:
Qπ(s11,ar)=r(s11,ar)+ γ *Vπ(s12) =0+0.9*100 = 90
Qπ(s11,ad)=r(s11,ad)+ γ *Vπ(s21) = 72
至此我们了解了马尔可夫决策过程的基本概念,知道了增强学习的目标(获得任意初始条件下,使Vπ值最大的策略π*),下一篇开始介绍求解最优策略的方法。
PS:发现写东西还是蛮辛苦的,希望对大家有帮助。另外自己也比较菜,没写对的地方欢迎指出~~
[注]采用折合因子作为值函数的MDP也可以定义为五元组M=(S, A, P, γ, R)。也有的书上把值函数作为一个因子定义五元组。还有定义为三元组的,不过MDP的基本组成元素是不变的。
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] T.Mitchell. 《机器学习》,2003
[3] 金卓军,逆向增强学习和示教学习算法研究及其在智能机器人中的应用[D],2011
[4] Oliver Sigaud et al,Markov Decision Process in Artificial Intelligence[M], 2010
转:增强学习(二)----- 马尔可夫决策过程MDP的更多相关文章
- 增强学习(二)----- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是 ...
- 马尔可夫决策过程MDP
1. 马尔可夫模型的几类子模型 马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM).它们具有的一个共同性质就是马尔可夫性(无 ...
- <强化学习>马尔可夫决策过程MDP
一.MDP / NFA :马尔可夫模型和不确定型有限状态机的不同 状态自动机:https://www.cnblogs.com/AndyEvans/p/10240790.html MDP和NFA ...
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- 强化学习入门基础-马尔可夫决策过程(MDP)
作者:YJLAugus 博客: https://www.cnblogs.com/yjlaugus 项目地址:https://github.com/YJLAugus/Reinforcement-Lear ...
- David Silver强化学习Lecture2:马尔可夫决策过程
课件:Lecture 2: Markov Decision Processes 视频:David Silver深度强化学习第2课 - 简介 (中文字幕) 马尔可夫过程 马尔可夫决策过程简介 马尔可夫决 ...
- 【RL系列】马尔可夫决策过程——Jack‘s Car Rental
本篇请结合课本Reinforcement Learning: An Introduction学习 Jack's Car Rental是一个经典的应用马尔可夫决策过程的问题,翻译过来,我们就直接叫它“租 ...
- 【cs229-Lecture16】马尔可夫决策过程
之前讲了监督学习和无监督学习,今天主要讲“强化学习”. 马尔科夫决策过程:Markov Decision Process(MDP) 价值函数:value function 值迭代:value iter ...
- [Reinforcement Learning] 马尔可夫决策过程
在介绍马尔可夫决策过程之前,我们先介绍下情节性任务和连续性任务以及马尔可夫性. 情节性任务 vs. 连续任务 情节性任务(Episodic Tasks),所有的任务可以被可以分解成一系列情节,可以看作 ...
随机推荐
- xss挑战赛小记 0x03(xssgame)
0x00 继续做xss吧 这次是xssgame 地址 http://www.xssgame.com/ 一共八关 学到了很多东西 0x01 啥也没有 <svg/onload="alert ...
- P1103 书本整理
P1103 书本整理 题目描述 Frank是一个非常喜爱整洁的人.他有一大堆书和一个书架,想要把书放在书架上.书架可以放下所有的书,所以Frank首先将书按高度顺序排列在书架上.但是Frank发现,由 ...
- cmd中可以运行java,但不能运行javac命令
在cmd中可以运行java,但运行javac命令时提示:'javac' 不是内部或外部命令,也不是可运行的程序或批处理文件. 原因:安装java时把jdk的路径和jre的路径选择成一样,就造成覆盖了. ...
- Android Open Source Projects(汇总与整理)
Android Open Source Projects 目前包括: Android开源项目第一篇——个性化控件(View)篇 包括ListView.ActionBar.Menu.ViewPager ...
- PHP管理供下载的APK文件
当我们开发的APP多的时候,把所有的APK文件统一放到一个目录中管理,是一个不错的选择: 管理的方法有很多,这里说一种: 1..创建目录结构,先创建根目录download,在根目录中创建项目目录,在项 ...
- jmeter的基本使用过程
jmeter的基本使用过程 接下来几周,我将通过视频的方式,录制下来jmeter的基本用法,方便大家参考学习 可能导图会随时调整
- git安装后Gitbase闪退,gui无法使用问题解决
一般是因为null.sys导致,根本原因应该还是你装的盗版系统有问题,解决办法如下 cmd 打开命题提示符后 输入 sc start null 看 null.sys是否有问题,如果有问题,重新 ...
- LeetCode 83 —— 删除排序链表中的重复元素
1. 题目 2. 解答 从前向后遍历链表,如果下一个结点的值和当前结点的值相同,则删除下一个结点,否则继续向后遍历. /** * Definition for singly-linked list. ...
- jira+mysql+破解+中文+compose
1.制作docker-compose.yml 2.安装 $ docker stack deploy -c docker-compose.yml mshk_jira
- BZOJ 4408 FJOI2016 神秘数 可持久化线段树
Description 一个可重复数字集合S的神秘数定义为最小的不能被S的子集的和表示的正整数.例如S={1,1,1,4,13},1 = 12 = 1+13 = 1+1+14 = 45 = 4+16 ...