python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬。
这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的知识,做一下总结笔记,方便以后借鉴。
笔记
一.反爬虫机制处理思路:
- 浏览器伪装、用户代理池;
- IP限制--------IP代理池;
- ajax、js异步-------抓包;
- 验证码-------打码平台。
二.散点知识:
- def process_request(): #处理请求
request.meta["proxy"]=.... #添加代理ip - scrapy中如果请求2次就会放弃,说明该代理ip不行。
实战操作
相关代码已经调试成功----2017-4-4
目标网址:http://weixin.sogou.com/weixin?type=2&query=python&ie=utf8
实现:关于python文章的抓取,抓取标题、标题链接、描述。如下图所示。
数据:数据我就没有保存,此实战主要是为了学习IP和用户代理池的设定,推荐一个开源项目关于搜狗微信公众号:基于搜狗微信的公众号文章爬虫
图1
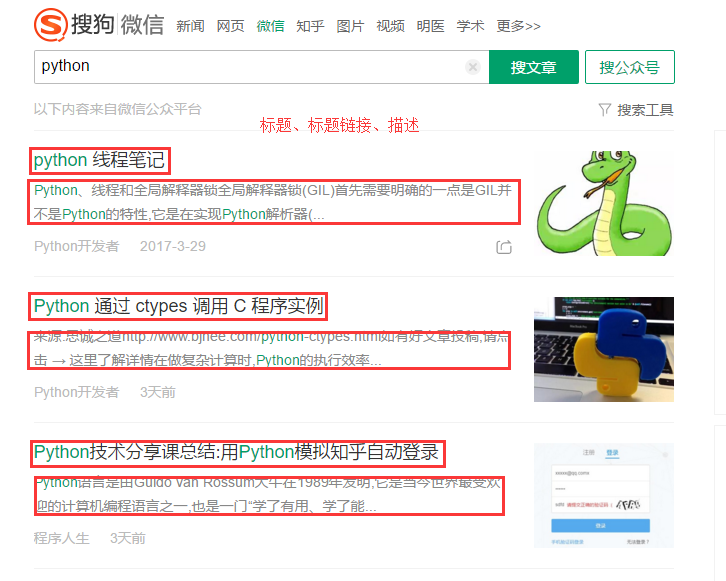
在这里贴出设置IP和用户代理池的代码,完整代码请移步我的github:https://github.com/pujinxiao/weixin
1.middlewares.py主要代码
# -*- coding: utf-8 -*-
import random
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware #代理ip,这是固定的导入
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware #代理UA,固定导入
class IPPOOLS(HttpProxyMiddleware):
def __init__(self,ip=''):
'''初始化'''
self.ip=ip
def process_request(self, request, spider):
'''使用代理ip,随机选用'''
ip=random.choice(self.ip_pools) #随机选择一个ip
print '当前使用的IP是'+ip['ip']
try:
request.meta["proxy"]="http://"+ip['ip']
except Exception,e:
print e
pass
ip_pools=[
{'ip': '124.65.238.166:80'},
# {'ip':''},
]
class UAPOOLS(UserAgentMiddleware):
def __init__(self,user_agent=''):
self.user_agent=user_agent
def process_request(self, request, spider):
'''使用代理UA,随机选用'''
ua=random.choice(self.user_agent_pools)
print '当前使用的user-agent是'+ua
try:
request.headers.setdefault('User-Agent',ua)
except Exception,e:
print e
pass
user_agent_pools=[
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36',
]
2.setting.py主要代码
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware':123,
'weixin.middlewares.IPPOOLS':124,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware' : 125,
'weixin.middlewares.UAPOOLS':126
}
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6665180.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)的更多相关文章
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- Python爬虫实战三之爬取嗅事百科段子
一.前言 俗话说,上班时间是公司的,下班了时间才是自己的.搞点事情,写个爬虫程序,每天定期爬取点段子,看着自己爬的段子,也是一种乐趣. 二.Python爬取嗅事百科段子 1.确定爬取的目标网页 首先我 ...
- python爬虫实战(一)——实时获取代理ip
在爬虫学习的过程中,维护一个自己的代理池是非常重要的. 详情看代码: 1.运行环境 python3.x,需求库:bs4,requests 2.实时抓取西刺-国内高匿代理中前3页的代理ip(可根据需求自 ...
- 路飞学城—Python爬虫实战密训班 第三章
路飞学城—Python爬虫实战密训班 第三章 一.scrapy-redis插件实现简单分布式爬虫 scrapy-redis插件用于将scrapy和redis结合实现简单分布式爬虫: - 定义调度器 - ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
随机推荐
- codevs 1491 取物品
1491 取物品 http://codevs.cn/problem/1491/ 时间限制: 1 s 空间限制: 128000 KB 题目描述 Description 现在有n个物品(有可能 ...
- js javascript变量提升
var:变量提升(无论声明在何处,都会被提至其所在作用域的顶部) let:无变量提升(所在的块内,未到let声明时(即let声明之前),是无法访问该变量的(not defined)),let变量不能重 ...
- SSM框架整合遇到的问题
1.Maven中Dubbo集成spring2.5以上版本 项目中dubbo集成spring4.x,配置pom时需要注意排除spring的依赖,我这里用的是tomcat,所以把jboss也排除了: &l ...
- python学习笔记(十一)之序列
之前学习的列表,元组,字符串都是序列类型,有很多共同特点: 通过索引得到每一个元素,索引从0开始 通过分片的方法得到一个范围的元素的集合 很多通用的操作符(重复操作符,拼接操作符,成员关系操作符) 序 ...
- 信息收集之zoomeye
一.浏览器上使用api接口 1.https://api.zoomeye.org/user/login post传参:{"username" : "username&quo ...
- 基于bootstrap物资管理系统后台模板——后台
链接:http://pan.baidu.com/s/1geKwVMN 密码:0utl
- 一个Servlet处理增删改查的方法
处理的思路是在servlet中定义不同的增删改查方法,页面请求 的时候携带请求的参数,根据参数判断调用不同的方法. package cn.xm.small.Servlet; import java.i ...
- 搭建linux+nginx+mysql+php环境
yum install -y gcc gcc-c++ make zlib zlib-devel pcre pcre-devel libjpeg libjpeg-devel libpng libpn ...
- HDU 6195 2017沈阳网络赛 公式
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6195 题意:有M个格子,有K个物品.我们希望在格子与物品之间连数量尽可能少的边,使得——不论是选出M个 ...
- 函数参数 f_arg, *args, **kwargs
当需要给函数传参时,可以通过运用不同的形参来传递,达到参数不同的使用目的. 简单来说:f_arg就是传递的第一个参数,类似于C++中的普通参数: *args 传递的是一个参数的list: **kwar ...