jieba和文本词频统计
---恢复内容开始---
一、结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
二、首先要先在cmd下载结巴
可以通过pip指令安装:pip install jieba #或者 pip3 install jieba
然后通过pip show pip检查是否是下载成功

这个就是jieba安装成功了
三、
#encoding=utf-8
importjieba
#全模式
text ="我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#默认是精确模式
seg_list = jieba.cut(text)
printu"[默认模式]: ","/ ".join(seg_list)
#新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
seg_list = jieba.cut("他来到了网易杭研大厦")
printu"[新词识别]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出如图所示:
代码中函数简单介绍如下:
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
其中待分词的字符串支持gbk\utf-8\unicode格式。返回的结果是一个可迭代的generator,可使用for循环来获取分词后的每个词语,更推荐使用转换为list列表。
2.添加自定义词典
由于"国家5A级景区"存在很多旅游相关的专有名词,举个例子:
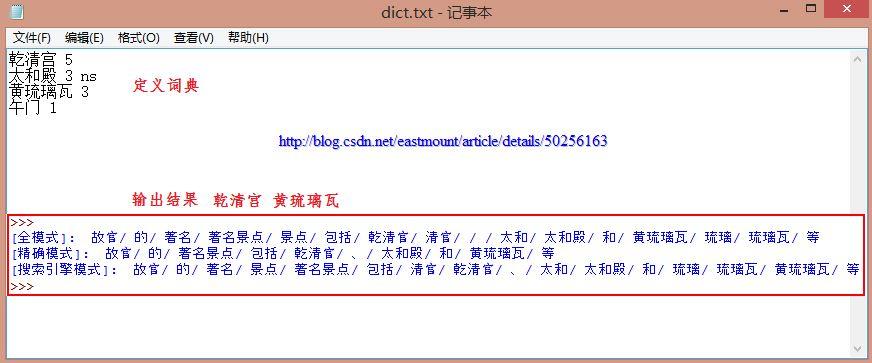
[输入文本] 故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等
[精确模式] 故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/黄/琉璃瓦/等
[全 模 式] 故宫/的/著名/著名景点/景点/包括/乾/清宫/太和/太和殿/和/黄/琉璃/琉璃瓦/等
显然,专有名词"乾清宫"、"太和殿"、"黄琉璃瓦"(假设为一个文物)可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略,ns为地点名词),用空格隔开。
#encoding=utf-8
importjieba
#导入自定义词典
jieba.load_userdict("dict.txt")
#全模式
text ="故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出结果如下所示:其中专有名词连在一起,即"乾清宫"和"黄琉璃瓦"。
---恢复内容结束---
jieba和文本词频统计的更多相关文章
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项 1.windows10家庭版 python 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordclo ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- Python3.7 练习题(二) 使用Python进行文本词频统计
# 使用Python进行词频统计 mytext = """Background Industrial Light & Magic (ILM) was starte ...
- jieba库及词频统计
import jieba txt = open("C:\\Users\\Administrator\\Desktop\\流浪地球.txt", "r", enco ...
- jieba分词及词频统计小项目
import pandas as pd import jieba import jieba.analyse from collections import Counter,OrderedDict ji ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库的使用与词频统计
1.词频统计 (1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本 挖掘的重要手段.它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其 ...
随机推荐
- Android动态加载--JVM 类加载机制
动态加载,本质上是通过JVM类加载机制将插件模块加载到宿主apk中,并通过android的相关运行机制,实现插件apk的运行.因此熟悉JVM类加载的机制非常重要. 类加载机制:虚拟机把描述类的数据从C ...
- PreparedStatement的setDate方法如何设置日期
pstmt.setString(12, "to_char(sysdate,'YYYY-MM-DD HH24:MI:SS')");这样写不对,应该如何写 该方法用于将指定的参数设置为 ...
- python report中文显示乱码
环境:python2.7 测试框架: nose (1.3.7) nose-html-reporting (0.2.3) 问题:生成测试报告失败的时候,报告会抓取代码中的print,打开后看到的中文是乱 ...
- Word2013文章如何直接发布到CSDN博客
目前大部分的博客作者在用Word写博客这件事情上都会遇到以下3个痛点: 1.所有博客平台关闭了文档发布接口,用户无法使用Word,Windows Live Writer等工具来发布博客.使用Word写 ...
- Apache网站服务
Apache 下载地址: http://mirror.bit.edu.cn/apache/httpd/相关软件下载地址:http://mirror.bjtu.edu.cn/apache/apr/apr ...
- Maven打包jar项目
默认情况下,使用maven打包的jar项目(执行maven install)不会包含其他包引用,要想打包为带其他项目引用的jar,需要加入插件 要得到一个可以直接在命令行通过java命令运行的JAR文 ...
- android屏幕适配,生成不同分辨率的dimen.xml文件
一.在项目下新建moudle,选择Java Library 二.DimenUtils类 public class DimenUtils { //文件保存的路径 是在该项目下根路径下创建 比如该项目创建 ...
- json的两种格式
JSON: JavaScript Object Notation (JavaScript 对象表示法) JSON 是存储和交换文本信息的语法.类似 XML. 一.JSON对象:JSONObj ...
- 单例模式(Singleton)小记
概念 引用维基百科对单例的说明: 单例模式,也叫单子模式,是一种常用的软件设计模式.在应用这个模式时,单例对象的类必须保证只有一个实例存在. 继续引用维基百科的实现思路: 实现单例模式的思路是:一个类 ...
- C# TinyIOC简单用法
先添加一个接口 namespace IContract { public interface IBase { void ShowMessage(); } } 再添加两个实现类 namespace Co ...