jieba和文本词频统计
---恢复内容开始---
一、结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
二、首先要先在cmd下载结巴
可以通过pip指令安装:pip install jieba #或者 pip3 install jieba
然后通过pip show pip检查是否是下载成功

这个就是jieba安装成功了
三、
#encoding=utf-8
importjieba
#全模式
text ="我来到北京清华大学"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#默认是精确模式
seg_list = jieba.cut(text)
printu"[默认模式]: ","/ ".join(seg_list)
#新词识别 “杭研”并没有在词典中,但是也被Viterbi算法识别出来了
seg_list = jieba.cut("他来到了网易杭研大厦")
printu"[新词识别]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出如图所示:
代码中函数简单介绍如下:
jieba.cut():第一个参数为需要分词的字符串,第二个cut_all控制是否为全模式。
jieba.cut_for_search():仅一个参数,为分词的字符串,该方法适合用于搜索引擎构造倒排索引的分词,粒度比较细。
其中待分词的字符串支持gbk\utf-8\unicode格式。返回的结果是一个可迭代的generator,可使用for循环来获取分词后的每个词语,更推荐使用转换为list列表。
2.添加自定义词典
由于"国家5A级景区"存在很多旅游相关的专有名词,举个例子:
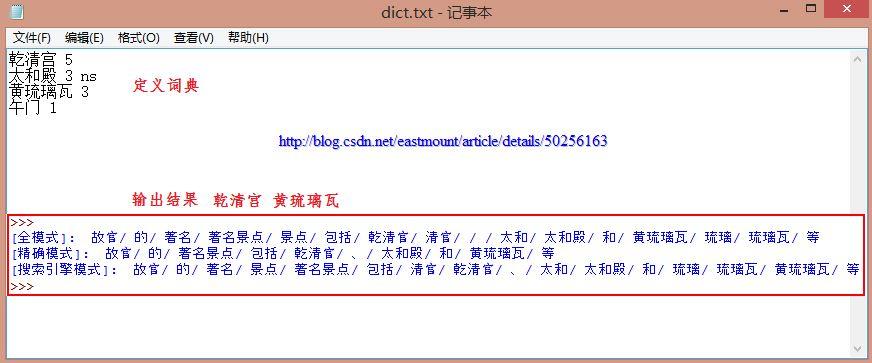
[输入文本] 故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等
[精确模式] 故宫/的/著名景点/包括/乾/清宫/、/太和殿/和/黄/琉璃瓦/等
[全 模 式] 故宫/的/著名/著名景点/景点/包括/乾/清宫/太和/太和殿/和/黄/琉璃/琉璃瓦/等
显然,专有名词"乾清宫"、"太和殿"、"黄琉璃瓦"(假设为一个文物)可能因分词而分开,这也是很多分词工具的又一个缺陷。但是Jieba分词支持开发者使用自定定义的词典,以便包含jieba词库里没有的词语。虽然结巴有新词识别能力,但自行添加新词可以保证更高的正确率,尤其是专有名词。
词典格式和dict.txt一样,一个词占一行;每一行分三部分,一部分为词语,另一部分为词频,最后为词性(可省略,ns为地点名词),用空格隔开。
#encoding=utf-8
importjieba
#导入自定义词典
jieba.load_userdict("dict.txt")
#全模式
text ="故宫的著名景点包括乾清宫、太和殿和黄琉璃瓦等"
seg_list = jieba.cut(text, cut_all=True)
printu"[全模式]: ","/ ".join(seg_list)
#精确模式
seg_list = jieba.cut(text, cut_all=False)
printu"[精确模式]: ","/ ".join(seg_list)
#搜索引擎模式
seg_list = jieba.cut_for_search(text)
printu"[搜索引擎模式]: ","/ ".join(seg_list)
输出结果如下所示:其中专有名词连在一起,即"乾清宫"和"黄琉璃瓦"。
---恢复内容结束---
jieba和文本词频统计的更多相关文章
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项 1.windows10家庭版 python 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordclo ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- Python3.7 练习题(二) 使用Python进行文本词频统计
# 使用Python进行词频统计 mytext = """Background Industrial Light & Magic (ILM) was starte ...
- jieba库及词频统计
import jieba txt = open("C:\\Users\\Administrator\\Desktop\\流浪地球.txt", "r", enco ...
- jieba分词及词频统计小项目
import pandas as pd import jieba import jieba.analyse from collections import Counter,OrderedDict ji ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库的使用与词频统计
1.词频统计 (1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本 挖掘的重要手段.它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其 ...
随机推荐
- 开发工具Visual Studio使用相关知识和经验的碎片化记录
开发工具Visual Studio使用相关知识和经验的碎片化记录 1.Visual Studio提示"无法启动IIS Express Web服务器"的解决方法 有时,在使用Visu ...
- Ubuntu16 apt-get更换为阿里源
1.备份系统自带源 mv /etc/apt/sources.list /etc/apt/sources.list.bak 2.修改/etc/apt/sources.list文件 vim /etc/ap ...
- 37 有n个人围成一圈,顺序排号,从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号那位.
题目:有n个人围成一圈,顺序排号,从第一个人开始报数(从1到3报数),凡报到3的人退出圈子,问最后留下的是原来第几号那位. public class _037NumberOff { public st ...
- HDU 1104 Remainder (BFS求最小步数 打印路径)
题目链接 题意 : 给你N,K,M,N可以+,- ,*,% M,然后变为新的N,问你最少几次操作能使(原来的N+1)%K与(新的N)%k相等.并输出相应的操作. 思路 : 首先要注意题中给的%,是要将 ...
- a 标签 name 属性 页面定位 (二)
<a href="to_url#somewhere">名字</a> <a name="somewhere">名字</a ...
- SecondaryNameNode中的“Inconsistent checkpoint fields”错误原因
该错误原因,可能是因为没有设置好SecondaryNameNode上core-site.xml文件中的"hadoop.tmp.dir". 2014-04-17 11:42:18,1 ...
- 用layer-list做一个卡片背景
<?xml version="1.0" encoding="utf-8"?> <layer-list xmlns:android=" ...
- owin Oauth
原文:http://www.cnblogs.com/richieyang/p/4918819.html 一.什么是OAuth OAuth是一个关于授权(Authorization)的开放网络标准,目前 ...
- EF:无法检查模型兼容性,因为数据库不包含模型元数据。
Model compatibility cannot be checked because the database does not contain model metadata. Model ...
- GridControl中文属性
1 Appearance EmbeddedNavigator 嵌入导航器 (DataBindings) 数据绑定 (Advanced) 高级设置 Tag Text AccessibleDes ...