Selenium+Python常见定位方法
参见官网:http://selenium-python.readthedocs.io/locating-elements.html
有多种策略来定位页面中的元素。你可以使用最适合你的情况。Selenium提供以下方法来定位页面中的元素:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
下面是查找多个元素(这些方法将返回一个列表):
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
除了上面给出的公共方法,这里也有两个在页面对象定位器有用的私有方法。这两个私有方法是find_element和find_elements。
常用方法是通过xpath相对路径进行定位,同时CSS也是比较好的方法。
举例:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
</form>
</body>
<html>
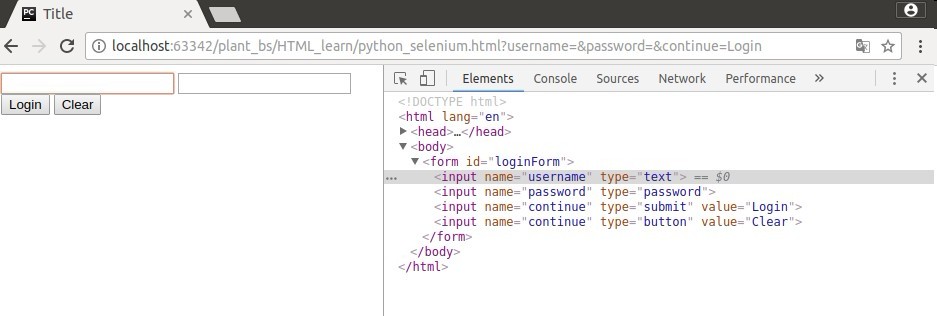
按照ID元素定位(find_element_by_id):
当你知道一个元素的id属性时使用它。使用此策略,将返回具有与该位置匹配的id属性值的第一个元素。如果没有元素具有匹配的id 属性,NoSuchElementException则会引发a。
login_form = driver.find_element_by_id('loginForm')
按照NAME元素定位(find_element_by_name):
当你知道一个元素的name属性时使用它。使用此策略,将返回具有与该位置匹配的id属性值的第一个元素。如果没有元素具有匹配的id 属性,NoSuchElementException则会引发a。
用户名和密码元素可以像这样定位
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
这会给出“登录”按钮,因为它出现在“清除”按钮之前
continue = driver.find_element_by_name('continue')
通过XPATH元素定位(find_element_by_xpath):
XPath是用于在XML文档中查找节点的语言。由于HTML可以是XML(XHTML)的实现,所以Selenium用户可以利用这种强大的语言来定位Web应用程序中的元素。XPath扩展了(也支持)通过id或name属性定位的简单方法,并打开了各种新的可能性,例如在页面上定位第三个复选框。
使用XPath的一个主要原因是当你没有合适的id或name属性的时候,你希望找到的元素。您可以使用XPath以绝对项(不建议)定位元素,或者相对于具有id或name属性的元素。XPath定位器也可以用来通过id和name以外的属性指定元素。
绝对XPath包含根(html)中所有元素的位置,因此可能会失败,只需对应用程序进行一点点调整即可。通过查找具有id或name属性的附近元素(最好是父元素),可以根据关系找到目标元素。这是不太可能改变,可以使你的测试更健壮。
考虑这个页面元素的来源:
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
</body>
<html>
用户名元素可以像这样定位:
username = driver.find_element_by_xpath("//form[input/@name='username']") # form元素通过一个input子元素,name属性和值为username实现
username = driver.find_element_by_xpath("//form[@id='loginForm']/input[1]") # 通过id=loginForm值的form元素找到第一个input子元素
username = driver.find_element_by_xpath("//input[@name='username']") # 属性名为name且值为username的第一个input元素
表单元素这样定位:
login_form = driver.find_element_by_xpath("/html/body/form[1]") # 绝对路径(如果HTML只是稍微改变就会中断)
login_form = driver.find_element_by_xpath("//form[1]") # HTML中的第一个表单元素
login_form = driver.find_element_by_xpath("//form[@id='loginForm']") # 属性名为id和值为loginForm的表单元素
“清除”按钮元素可以像这样定位:
clear_button = driver.find_element_by_xpath("//input[@name='continue'][@type='button']") # 输入属性名为name,值为continue,属性名为type,值为button
clear_button = driver.find_element_by_xpath("//form[@id='loginForm']/input[4]") # 表单元素的第四个输入子元素,具有名为id和值为loginForm的属性
更多Xpath知识参见:http://www.w3school.com.cn/xpath/index.asp
通过Link Text元素定位(通过链接文本找超链接)find_element_by_link_text
当你知道在一个锚标签中使用的链接文本时,使用它。采用这种策略,将返回链接文本值与该位置匹配的第一个元素。如果没有元素具有匹配的链接文本属性,NoSuchElementException则会引发a。
如:考虑这个页面的来源。
<html>
<body>
<p>Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
continue.html可以像这样定位:
continue_link = driver.find_element_by_link_text('Continue')
continue_link = driver.find_element_by_partial_link_text('Conti')
通过标记名称查找元素(find_element_by_tag_name)
当你想通过标签名找到一个元素时使用它。采用这种策略,将返回具有给定标签名称的第一个元素。如果没有元素具有匹配的标签名称,NoSuchElementException 则会引发一个。
如:考虑这个页面的来源。
<html>
<body>
<h1>Welcome</h1>
<p>Site content goes here.</p>
</body>
<html>
标题(h1)元素可以像这样定位:
heading1 = driver.find_element_by_tag_name('h1')
通过类名称查找元素(find_element_by_class_name)
当你想通过class属性名来定位一个元素的时候使用它。使用这个策略,将返回具有匹配的类属性名称的第一个元素。如果没有元素具有匹配的类属性名称,NoSuchElementException则会引发a。
如:考虑这个页面的来源
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
“p”元素可以像这样定位:
content = driver.find_element_by_class_name('content')
通过CSS选择器查找元素(find_element_by_css_selector)
例如,考虑这个页面的来源:
<html>
<body>
<p class="content">Site content goes here.</p>
</body>
<html>
“p”元素可以像这样定位:
content = driver.find_element_by_css_selector('p.content')
练习元素定位网址:http://sahitest.com/demo/formTest.htm
Selenium+Python常见定位方法的更多相关文章
- Selenium Web元素定位方法
Selenium是用于Web应用测试的自动化测试框架,可以实现跨浏览器和跨平台的Web自动化测试.Selenium通过使用WebDriver API来控制web浏览器,每个浏览器都都有一个特定的Web ...
- 5 Python+Selenium的元素定位方法(xpath)
[环境] Python3.6+selenium3.0.2+FireFox50+win7 [定位方法] 1.方法:find_element_by_xpath('') 说明:xpath定位方法有相对路径和 ...
- 4 Python+Selenium的元素定位方法(link/partial link)
[环境] Python3.6+selenium3.0.2+IE11+win7 [定位方法] 1.link/partial link定位方法:定位的元素为文字链接且链接很长时 方法:find_eleme ...
- 3 Python+Selenium的元素定位方法(id、class name、name、tag name)
[环境] Python3.6+selenium3.0.2+IE11+Win7 [定位方法] 1.通过ID定位 方法:find_element_by_id('xx') 2.通过name定位 方法:fin ...
- 6 Python+Selenium的元素定位方法(CSS)
[环境] python3.6+selenium3.0.2+Firefox50.0+win7 [定位方法] 1.方法:find_element_by_css_selector('xx') CSS的语法比 ...
- selenium+Python(定位 单选、复选框,多层定位)
1.定位一组元素webdriver 可以很方便的使用 findElement 方法来定位某个特定的对象,不过有时候我们却需要定位一组对象,这时候就需要使用 findElements 方法.定位一组对象 ...
- selenium的元素定位方法-By
如果在定位元素属性中包含了如ID等元素属性,那么在一个测试中,定位方法具体有哪几种,可以参考by模块中的By类,By的代码如下: class By(object): """ ...
- selenium+Python(select定位)
1.Select元素 1.打开百度-设置-搜索设置界面,如下图所示 2.箭头所指位置,就是 select 选项框,打开页面元素定位,下方红色框框区域,可以看到 select 标签属性: <sel ...
- Selenium之XPATH定位方法
转自 https://www.cnblogs.com/hanmk/p/8997786.html https://www.cnblogs.com/hanmk/p/9015502.html 感谢原作者 1 ...
随机推荐
- jquery书写一个简易的二级联动
先用php生成一个json数组示例如下 JSON_UNESCAPED_UNICODE 是对汉字进行处理的参数 然后HTML代码如下 把那个json_city赋值成我们用php生成的json即可 < ...
- Axure 8 注册码,市面上很多注册码都不行用,但是这个可以。
找了很久了,感谢@Quan-Sunny的转载 Licensee: University of Science and Technology of China (CLASSROOM) Key: DTXR ...
- ndarray 布尔类型矩阵中统计Ture 的次数
对象:NumPy数组或矩阵,eg. data的元素为True和False numpy.sum(data) #统计data中True的个数numpy.count_nonzero(data) #统计dat ...
- Django学习笔记第八篇--实战练习四--为你的视图函数自定义装饰器
零.背景: 对于登录后面所有视图函数,都需要验证登录信息,一般而言就是验证cookie里面的一些信息.所以你可以这么写函数: def personinfo(request): ": retu ...
- Codeforces Round #513-ABCD
ABC现场做出,涨了八十几分吧.D有点思路不知道怎么实现,赛后看题解发现巨简单,想得太复杂了.蓝瘦. A----http://codeforces.com/contest/1060/problem/A ...
- DK NIO的BUG,例如臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU 100%。
NIO的epoll空轮询bug - Lost blog - 博客园 https://www.cnblogs.com/JAYIT/p/8241634.html NIO的epoll空轮询bug JDK ...
- Whether to hide the cookie from JavaScript
w禁用js访问特定cookie. https://codeigniter.com/userguide3/helpers/cookie_helper.html $this->load->he ...
- post 传递参数中包含 html 代码解决办法,js加密,.net解密
今天遇到一个问题,就是用post方式传递参数,程序在vs中完美调试,但是在iis中,就无法运行了,显示传递的参数获取不到,报错了,查看浏览器请求情况,错误500,服务器内部错误,当时第一想法是接收方式 ...
- shipyard 中文版安装 -- Docker web管理
#本文使用markdown文档格式 #Docker web管理平台 #shipyard 中文版安装 #hipyard可对容器.镜像.仓库.docker节点进行管理的web系统 #+++++++++++ ...
- Linux时间管理涉及数据结构和传统低分辨率时钟的实现
上篇文章大致描述了Linux时间管理的基本情况,看了一些大牛们的博客感觉自己写的内容很匮乏,但是没办法,只能通过这种方式提升自己……闲话不说,本节介绍下时间管理下重要的数据结构 设备相关数据结构 // ...