Perl6 必应抓取(1):测试版代码
一个相当丑漏的代码, 以后有时间再优化了。
默认所有查找都是15页, 如果结果没有15页这么多估计会有重复。速度还是很快的。
sub MAIN() {
my $fp = open 'bin_result.txt', :w;
my $number = ;
print 'String:';
my $string = get;
$string = do given $string {S:g/\s/+/};
use HTTP::UserAgent;
my $url = 'http://cn.bing.com/search?q=';
my $ua = HTTP::UserAgent.new;
my $check = rx/'<'cite'>'(.*?)'</cite>'/;#要查的内容
my @number = '';
@number.append(..$number);
my $page='';
my $html;
my $target = $url~$string~'&first=20&FROM=FERE'~$page;
$html = $ua.get($target).content;
loop {
say '===============> '~$target;
$html ~~ $check;
$html = $/.postmatch;
#$0 = do given ~$0 {S:g/'<strong>'//;}
if not $ {
#当是null时, 说明这一页已全部提取, 构造下一页
$page = Int($page);
my $page_next = $string~'&first='~$page~'0&FROM=FERE'~$page;
$target = $url~$page_next;
$html = $ua.get($target).content;
$page++;
#/search?q=123&first=10&FORM=PERE
#/search?q=123&first=20&FORM=PERE1
#/search?q=123&first=30&FORM=PERE2
#/search?q=123&first=30&FORM=PERE2
#last;
$html ~~ $check;
$html = $/.postmatch;
if ($page > $number) {last;}
}
my $ok_check = $.Str;
my $result = $ok_check;
$result = do given $result {S:g/'<strong>'//;}
$result = do given $result {S:g/'</strong>'//;}
say $result;
$fp.say($result);
}
#$fp.print($html);
}


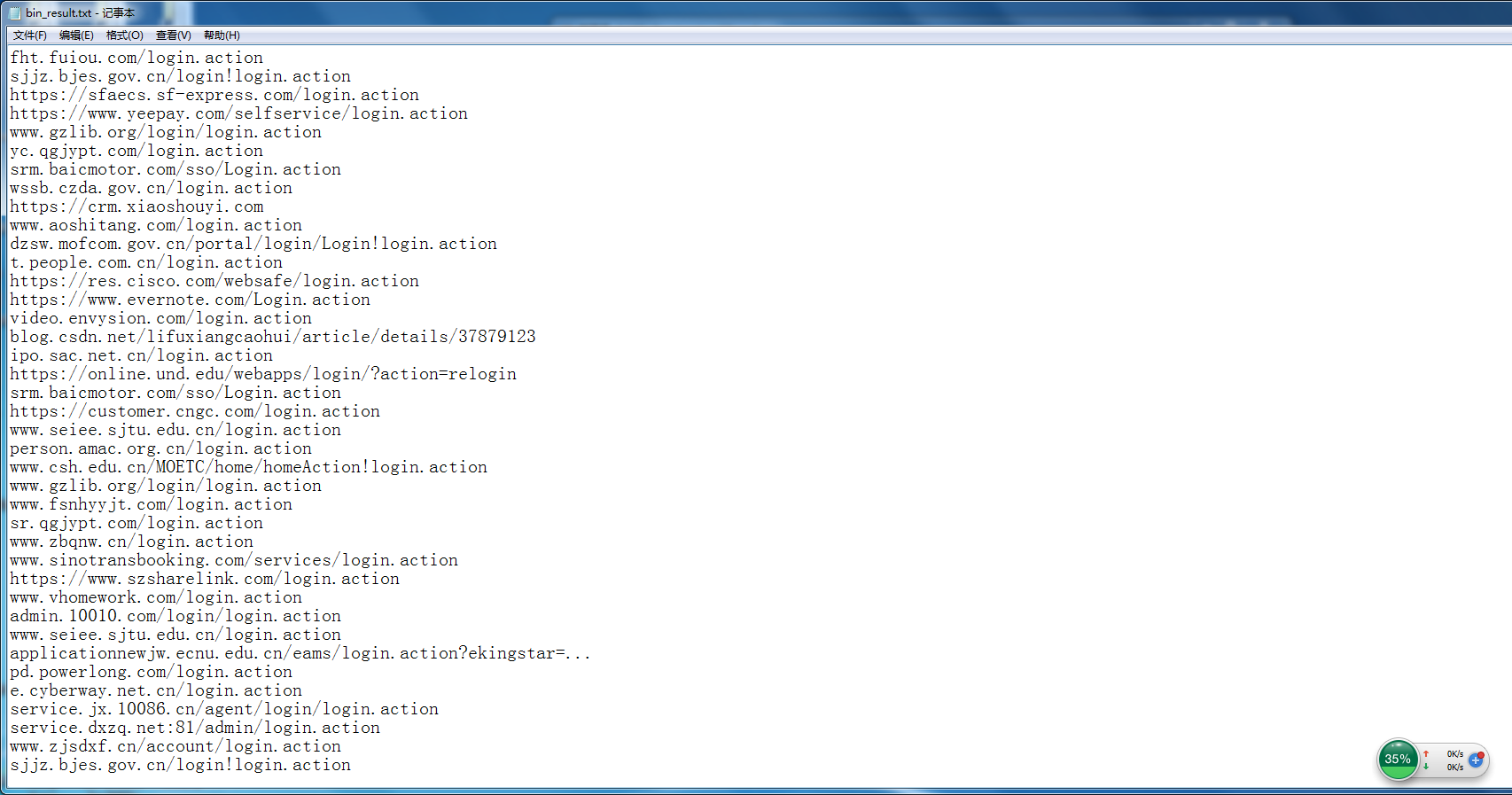
下次代码优化:
总结一下必应的规律, 如下:
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE
http://cn.bing.com/search?q=&first=&FORM=PERE1
http://cn.bing.com/search?q=&first=&FORM=PERE2
http://cn.bing.com/search?q=&first=&FORM=PERE3
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
http://cn.bing.com/search?q=&first=&FORM=PERE4
在页面上测试, 参数只虽两个即可:
q=查询字符串&first=起始帐号


Perl6 必应抓取(1):测试版代码的更多相关文章
- Perl6 必应抓取(2):最终版
use HTTP::UserAgent; use URI::Encode; Firefox/52.0>); my $bing_url = 'http://cn.bing.com/search?q ...
- HttpClient 4.x 执行网站登录并抓取网页的代码
HttpClient 4.x 的 API 变化还是很大,这段代码可用来执行登录过程,并抓取网页. HttpClient API 文档(4.0.x), HttpCore API 文档(4.1) pack ...
- php中抓取网页内容的代码
方法一: 使用file_get_contents方法实现 $url = "http://news.sina.com.cn/c/nd/2016-10-23/doc-ifxwztru695114 ...
- xheditor编辑器上传截图图片抓取远程图片代码
xheditor是一款很不错的开源编辑器,用起来很方便也很强大. 分享一个xheditor直接上传截图的问题解决方法. 第一步.设置参数 localUrlTest:/^https?:\/\/[^\/] ...
- python网页抓取练手代码
from urllib import request import html.parser class zhuaqu(html.parser.HTMLParser): blogHtml = " ...
- Python网络编程_抓取百度首页代码(注释详细)
1 #coding=utf-8 2 #网络编程 3 4 #客户端建立socket套接字 5 #引入socket模块 6 import socket 7 #实例化一个套接字,2个参数分别是: IPV4. ...
- 抓取网站数据不再是难事了,Fizzler(So Easy)全能搞定
首先从标题说起,为啥说抓取网站数据不再难(其实抓取网站数据有一定难度),SO EASY!!!使用Fizzler全搞定,我相信大多数人或公司应该都有抓取别人网站数据的经历,比如说我们博客园每次发表完文章 ...
- PHP的cURL库:抓取网页,POST数据及其他,HTTP认证 抓取数据
From : http://developer.51cto.com/art/200904/121739.htm 下面是一个小例程: ﹤?php// 初始化一个 cURL 对象$curl = curl_ ...
- php中封装的curl函数(抓取数据)
介绍一个封闭好的函数,封闭了curl函数的常用步骤,方便抓取数据. 代码如下: <?php /** * 封闭好的 curl函数 * 用途:抓取数据 * edit by www.jbxue.com ...
随机推荐
- TTPPRC —— 商业分析模型
欢迎讨论 : ) 前言1 TTPPRC,是一个为了更容易.透切地进行商业分析而整理出的分析模型.通过这个模型,可以让不具备专业商业知识的大众都能容易得出商业分析结果. 此文是读者阅读原文后,而整理的一 ...
- jmeter 兼容bug 记录一笔
这个问题我也遇到过,然后网上搜到了这篇文章! 先说下问题: 我在做性能测试时,使用JMeter搞了100个并发,以100TPS的压力压测十分钟,但压力一直出现波动,而且出现波动时JMeter十分卡,如 ...
- css 在背景图上加渐变
<html> <head> <title>我的第一个 HTML 页面</title> <style> .banner { width: %; ...
- iOS pch文件的创建
3.iso pch头文件的创建 输入文件名的时候记得打钩 3.1.在Build Settings 里搜索pref就能找到preflx, 点击设置相对路径 $(SRCROOT) +路径:成功了就会显示 ...
- BZOJ 1222 产品加工(DP)
某加工厂有A.B两台机器,来加工的产品可以由其中任何一台机器完成,或者两台机器共同完成.由于受到机器性能和产品特性的限制,不同的机器加工同一产品所需的时间会不同,若同时由两台机器共同进行加工,所完成任 ...
- 【bzoj1297】[SCOI2009]迷路 矩阵乘法
题目描述 给出一个 $n$ 个点的有向图,每条边的权值都在 $[1,9]$ 之间.给出 $t$ ,求从 $1$ 到 $n$ ,经过路径边权和恰好为 $t$ 的方案数模2009. 输入 第一行包含两个整 ...
- vue中axios复用封装
ajax2: function() { let that = this; return that .$http({ method: "get", url: "/Home/ ...
- [CF1111E]Tree
题目大意:给一棵$n(n\leqslant10^5)$个点的树,有$q(q\leqslant10^5)$次询问,每次询问给出$k,m,r$表示把以下$k$个点分成不超过$m$组,使得在以$r$为根的情 ...
- Codeforces Round #338 (Div. 2) B dp
B. Longtail Hedgehog time limit per test 3 seconds memory limit per test 256 megabytes input standar ...
- jre,jdk,jvm的关系
今天在用maven搭建项目工程的时候出错的原因竟然是因为使用了jre,而非jdk导致报错,这里就搜集了有关这方面的信息: JDK(Java Development Kit)是针对Java开发员的产 ...