filebeat + logstash 日志采集链路配置
1. 概述
一个完整的采集链路的流程如下:
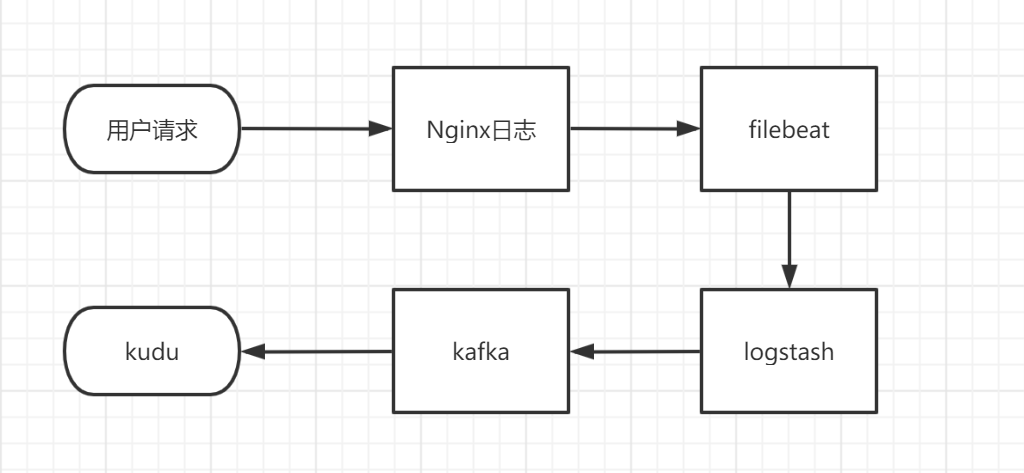
所以要进行采集链路的部署需要以下几个步聚:
- nginx的配置
- filebeat部署
- logstash部署
- kafka部署
- kudu部署
下面将详细说明各个部分的部署方法,以及一些基本的配置参数。
2. 部署流程
nginx
1. 安装
nginx安装直接去官网下载一个压缩文件解压然后用sbin/nginx运行就可以了。
2. 配置
2.1 日志输出格式
nginx是采集链路的第一个环节,后面的日志采集系统是通过采集nginx日志进行分析的。本节主要对nginx的日志处理的配置进行描述。
对nginx.conf文件进行配置:
log_format log_json escape=json '{ "@timestamp": "$time_local", '
'"remote_addr": "$remote_addr", '
'"referer": "$http_referer", '
'"project": "$arg_project", '
'"request": "$request", '
'"status": $status, '
'"bytes": $body_bytes_sent, '
'"request_body": "$request_body",'
'"data": "$arg_data",'
'"cookies": "$http_cookie"'
' }';
上面的代码定义了一个nginx的日志输出格式并命名为log_json,并且使用escape=json参数来把变量中可能包含的json字符串自动转义。
这个日志输出哪些变量都可以灵活配置,取决于采集框架怎么进行数据解析。在本文中,前端发送的请求中,埋点数据可能出现在request body中,也可能出现在url参数中以data=xxx的形式转递,所以将这两个变量打印到日志中。
输出格式也可以灵活配置,在logstash的输入解析中进行对应的调整就可以了。使用json格式可以直接用json插件进行解析,否则可能就要用grok插件自己写正则进行解析了。这里推荐输出为json格式。
2.2 监听配置
...
http {
...
server {
listen 2346;
access_log logs/data_tracking/access.log log_json;
location / {
error_page 405 =200 $request_uri;
}
}
}
配置监听埋点端口,将请求日志打印到单独的一个文件夹中避免和其他日志混淆,并指定输出格式为上一节配置好的log_json。
同时把根请求的405代码转发为200,因为请求监听的端口并没有任何资源,请求会返回status_code = 405。
filebeat
filebeat是一款开源的轻量级日志采集工具,主要用于整合各个路径下的各种不同的日志文件,并且统一输出到指定的输出点。
对于filebeat的配置较为简单,而filebeat提供的功能也十分有限,只能进行简单的日志采集工作,所以需要和logstash配和使用
1. 安装
可以直接在官网下载rpm或deb包:
https://www.elastic.co/cn/downloads/beats/filebeat
下载后直接使用yum localinstall {pacakgeName}进行安装。
或者使用包管理软件如 apt 和 yum 进行安装:
首先引入公有签名key
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
然后再添加一个repo文件到/etc/yum.repos.d/目录中
[elastic-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
最后使用yum命令直接安装即可。
2. 配置和启动
filebeat默认安装在/usr/share/filebeat下
filebeat目录结构说明:
home安装的根目录bin一些二进制执行文件config配置文件data持久化的数据文件logsfilebeat运行日志
在运行filebeat前,需要对filebeat的一些运行参数进行配置。
首先需要在filebeat根目录下新建一个filebeat.yml配置文件,并在其中写入如下的内容:
filebeat.inputs:
- type: log
enabled: true
paths: - /var/log/*.log
output.logstash:
hosts:["localhost:5044"]
注意:所有的横线后都要空一格,不能直接跟字符串。这是YAML的语法格式,可以去了解一下。
filebeat.inputs指定了输入的配置。其中type指定了输入的类型是日志类型。paths指定了输入文件的路径,表示读取/var/log/路径下的所有.log结尾的文件。
output.logstash指定了输出到logstash的配置。其中hosts可以指定一个数组,写入多个输出地址。
设置开机启动filebeat
systemctl enable filebeat
通过bin/filebeat文件启动filebeat用:
bin/filebeat -e -c filebeat.yml
3. 和nginx的配合
首先修改
filebeat.yml中的paths,指定输入为nginx埋点日志的输出位置。使用
include_lines,指定正则表达式来过滤不符合要求的行。nginx日志输出格式是一个请求一行。否则进行单行过滤的时候会有大问题。
输出配置最好指定为内网ip。
filebeat:
inputs:
- type: log
enabled: true
paths:
- /usr/local/openresty/nginx/logs/data_tracking/access.log*
include_lines: ['"project": "test_bank_event"']
output.logstash:
hosts: ["192.168.0.34:5055"]
logstash
logstash相对于filebeat并没有那么轻量,但相对来说有更多的功能和数据处理功能。所以一般将filebeat和logstash结合使用。用filebeat读取日志文件并输出到logstash中,再进行后续的数据处理。
1. 安装
logstash的安装方法和filebeat的安装基本相同,可以在官网下载安装包进行安装,在此不再赘述。
https://www.elastic.co/cn/downloads/logstash
2. 配置和启动
logstash 的默认安装路径也位于/usr/share/目录下。
其启动文件是安装根目录下的bin/logstash,对于一些简单的配置信息,可以直接以命令行参数的形式指定:
bin/logstash -e 'input { stdin {}} output{ stdout{}}'
这行命令指定了最基本的input和output为标准输入和标准输出。启动后直接在命令行输入内容,回车后就可以看到结构化处理后的数据输出:
hello world
/usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"@timestamp" => 2020-06-08T03:38:04.658Z,
"host" => "hadoop",
"message" => "hello world",
"@version" => "1"
}
要进行更多的配置,最好在安装根目录下新建一个 .conf格式的配置文件。
要将logstash和filebeat联合使用,需要让logstash接受一个beats格式的输入:
input{
beats{
port => "5044"
}
}
# filter{
#
# }
output {
stdout { codec => rubydebug}
}
上述配置指定了一个beats类型的input,并设置端口为5044
在写好配置文件后可以使用下面的命令对配置进行检查,其中-f指定了要加载的配置文件:
bin/logstash -f first-pipeline.conf --config.test_and_exit
--config.test_and_exit命令会加载配置文件并检查是否有错误,并在输出检查结果后自动退出。
如果检查通过,那么就可以启动logstash了:
bin/logstash -f first-pipeline.conf --config.reload.automatic
--config.reload.automatic命令开启了自动重载配置的功能,所以在修改完配置文件后可以不用重启服务,logstash会自动加载更新后的配置。
如果在filebeat中配置的输出地址和logstash中的输入beats地址相同,那么在启动了这两个服务后,logstash就可以收到filebeat读取到的日志内容。其基本格式和上文中从标准输入获取数据并输出的格式类似。
3. 和filebeat的配合
在输入配置了对应的filebeat的端口后,接下来主要是配置filter模块对日志进行解析,这部分也要根据nginx日志的结构进行灵活的配置。filebeat主要用来收集数据传输给logstash,当然filebeat中也可以进行一些简单的数据处理,但还是推荐filebeat只负责收集日志,发送到logstash进行统一处理。
下面是一份logstash的conf文件用于参考:
filter{
# 首先对filebeat中的数据进行解析,其中'message'对应的值才是我们真正要解析的埋点数据
# 其他还有很多filebeat自动生成的数据。
# 这里使用json插件进行解析,解析完后就可以删除原来的变量了,减少不必要的数据传输
json{
source => "message"
remove_field => ["message"]
}
# 对埋点数据进行url解码,因为埋点数据可能是通过url传输的,可能会有进行过url编码
urldecode{
all_fields => true
}
# 使用ruby进行base64解码,目标是'data'变量,结果赋值给新建的'b64_decoded'变量。
ruby {
init => "require 'base64'"
code => "event.set('b64_decoded', Base64.decode64(event.get('data'))) if event.include?('data')"
#这里解码出刚刚截取出来的msg字段
remove_field => ["data","request"]
}
# 在解码后再进行一次json解析,把json字符串转换为json结构体
json {
source => "b64_decoded"
remove_field => ["b64_decoded"]
}
}
4. 和kafka的配合
由于本链路使用的存储为kudu数据库,而logstash是不支持直接写入kudu的;并且要考虑到并发处理和容错,所以要先将数据写入kafka消息队列,再由kafka写入kudu。
主要是配置conf文件中的output模块:
output{
kafka {
# 输出为json格式
codec => json
# 指定topic为'test_event'
topic_id => "test_event"
}
}
必要的配置就只有topic_id,更多的配置参考logstash官方文档对kafka插件的介绍。
kafka
1. 安装
2. 配置
3. 和kudu的对接
filebeat + logstash 日志采集链路配置的更多相关文章
- Filebeat轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器.这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据. 一.架构图 此次试验基于前几 ...
- logstash日志分析的配置和使用
logstash是一个数据分析软件,主要目的是分析log日志.整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是v ...
- logstash日志采集工具的安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上 下载logstash-6.2.3.tar.gz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads ...
- logstash日志分析的配置和使用(转)
logstash是一个数据分析软件,主要目的是分析log日志.整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是v ...
- ELK太重?试试KFC日志采集
写在前面 ELK三剑客(ElasticSearch,Logstash,Kibana)基本上可以满足日志采集.信息处理.统计分析.可视化报表等一些日志分析的工作,但是对我们来说--太重了,并且技术栈不是 ...
- 5-17 ELK 日志采集查询保存
ELK简介 什么是ELK ELK: E:Elasticsearch 全文搜索引擎 L:logstash 日志采集工具 K:Kibana ES的可视化工具 ELK是当今业界非常流行的日志采集保存和查询的 ...
- Filebeat+Kafka+Logstash+ElasticSearch+Kibana 日志采集方案
前言 Elastic Stack 提供 Beats 和 Logstash 套件来采集任何来源.任何格式的数据.其实Beats 和 Logstash的功能差不多,都能够与 Elasticsearch 产 ...
- ES系列十八、FileBeat发送日志到logstash、ES、多个output过滤配置
一.FileBeat基本概念 简单概述 最近在了解ELK做日志采集相关的内容,这篇文章主要讲解通过filebeat来实现日志的收集.日志采集的工具有很多种,如fluentd, flume, logst ...
- 一篇文章教你搞懂日志采集利器 Filebeat
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 本文使用的Filebeat是7.7.0的版本,文章将从如下几个方面说明: Filebeat是什 ...
随机推荐
- 『现学现忘』Git基础 — 19、在Git中进行忽略文件操作
目录 1.忽略文件说明 2.忽略文件的原则 3..gitignore忽略规则 4.忽略文件的三种方式 (1)忽略单个仓库中的文件(远程共用) (2)忽略单个仓库中的文件(本地使用) (3)全局忽略 1 ...
- 【Docker入门】Docker的常用命令
了解和安装完docker之后,我们学习一下docker的常用命令就和当初学linux命令一样,放心命令其实大致相同只不过细节不同. 一.Docker启动类命令 1.启动docker:syste ...
- 如何使用Docker构建前端项目
原文链接 Docker单独部署前端项目和Node项目是非常便捷的,在这里分享一下Docker的使用,主要聊聊它的部署实践.(我是window10专业版安装Docker) Docker Docker是一 ...
- 小米 pro 笔记本双硬盘设置引导盘
功能键 F2 进入 BIOS F12 进入 Boot 选项 步骤 小米 Pro 默认是开启了 UEFI,如果 Boot 选项没有显示出期望的系统盘,那么就是这个系统盘没有 UEFI 分区,按照这个文档 ...
- Java类包
学习内容:Java类包 一.Java类包 1.一个完整的类名需要包名和类名的组合,每一个类都隶属于一个包. 例:完整类名--java.sql.Date 2.同一个包中类相互访问时可以不指明包名. 3. ...
- Unity中通过深度优先算法和广度优先算法打印游戏物体名
前言:又是一个月没写博客了,每次下班都懒得写,觉得浪费时间.... 深度优先搜索和广度优先搜索的定义,网络上已经说的很清楚了,我也是看了网上的才懂的,所以就不在这里赘述了.今天讲解的实例,主要是通过自 ...
- 如何在 pyqt 中捕获并处理 Alt+F4 快捷键
前言 如果在 Windows 系统的任意一个窗口中按下 Alt+F4,默认行为是关闭窗口(或者最小化到托盘).对于使用了亚克力效果的窗口,使用 Alt+F4 最小化到托盘,再次弹出窗口的时候可能出现亚 ...
- YAML在线验证
推荐一个网站:YAML在线验证https://www.bejson.com/validators/yaml_editor/
- Linux系统下运行.sh文件
在Linux系统下运行.sh文件有两种方法,比如我在root目录下有个vip666.sh文件 #chmod +x *.sh的文件名 #./*.sh的文件名 第一种(这种办法需要用chmod使得文件具备 ...
- ExtJS 布局-Auto布局(Auto Layout)
更新记录 2022年5月30日 开启本篇 1.说明 auto布局是大部分容器默认的布局类型. auto布局通常是从上到下进行堆叠,auto布局不会设置子组件的宽度,默认与容器一样的宽度. 类似于HTM ...