详解数仓中sequence的应用场景及优化
摘要:本文简单介绍sequence的使用场景及如何修改sequence的cache值提高性能。
本文分享自华为云社区《GaussDB(DWS)关于sequence的那些事》,作者:Arrow0lf 。
什么是sequence
sequence,也称作序列,是用来产生唯一整数的数据库对象。序列的值按照一定的规则自增/自减,一般常被用作主键。GaussDB(DWS)中,创建sequence时会同时创建一张同名的元数据表,用来记录sequence相关的信息,例如:
postgres=# create sequence seq;
CREATE SEQUENCE
postgres=# select * from seq;
sequence_name | last_value | start_value | increment_by | max_value | min_value | cache_value | log_cnt | is_cycled | is_called | uuid
---------------+------------+-------------+--------------+---------------------+-----------+-------------+---------+-----------+-----------+---------
seq | -1 | 1 | 1 | 9223372036854775807 | 1 | 1 | 0 | f | f | 1600007
(1 row)
其中,sequence_name表示sequence的名字,last_value当前无意义,start_value表示sequence的初始值,increment_by表示sequence的步长,max_value表示sequence的最大值,min_value表示最小值,cache_value表示为了快速获取下一个序列值而预先存储的sequence值个数(定义cache后不能保证sequence值的连续性,会产生空洞,详见下文)。log_cnt表示WAL日志记录的sequence值个数,由于在DWS中sequence是从GTM获取和管理,因此log_cnt无实际意义;is_cycled表示sequence在达到最小或最大值后是否循环继续,is_called表示该sequence是否已被调用(仅表示在当前实例是否被调用,例如在cn_5001上调用之后,cn_5001上该原数据表的值变为t,cn_5002上该字段仍为f),uuid代表该sequence的唯一标识。
GaussDB(DWS)中,通过GTM(Global Transaction Manager,名为全局事务管理器)负责生成和维护全局事务ID、事务快照、Sequence等需要全局唯一的信息。sequence在DWS中的创建流程如下图所示:
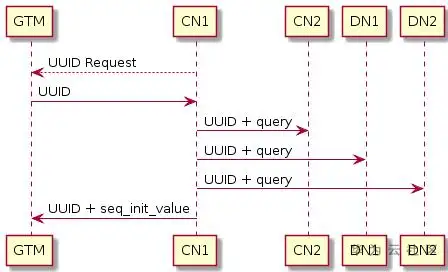
具体过程为:
- 接受SQL命令的CN从GTM申请UUID;
- GTM返回一个UUID;
- CN将拿到的UUID与用户创建的sequenceName绑定;
- CN将绑定关系下发给其他节点上,其他节点同步创建sequence元数据表;
- CN将UUID 和sequence的startID发送到GTM端,在GTM行进行永久保存。
因此,sequence的维护和申请实际是在GTM上完成的。当申请nextval,每个执行nextval调用的实例会根据该sequence的uuid到GTM上申请序列值,每次申请的序列值范围与cache有关,只有当cache消耗完之后才会继续到GTM上申请。因此,增大sequence的cache有利于减少CN/DN与GTM通信的次数。接下来,将详细介绍sequence在DWS中的使用场景和注意事项。
如何创建sequence
GaussDB(DWS)中,有两种创建sequence的方法:
方法一:直接创建sequence,并通过nextval调用,举例:
postgres=# create sequence seq;
CREATE SEQUENCE
postgres=# insert into t_dest select nextval('seq'),* from t_src;
INSERT 0 0
方法二:建表时使用serial类型,会自动创建一个sequence,并且会将该列的默认值设置为nextval,举例:
postgres=# create table test(a int, b serial) distribute by hash(a);
NOTICE: CREATE TABLE will create implicit sequence "test_b_seq" for serial column "test.b"
CREATE TABLE
postgres=#\d+ test
Table "public.test"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------+--------------------------------------------------+---------+--------------+-------------
a | integer | | plain | |
b | integer | not null default nextval('test_b_seq'::regclass) | plain | |
Has OIDs: no
Distribute By: HASH(a)
Location Nodes: ALL DATANODES
Options: orientation=row, compression=no
本例中,会自动创建一个名为test_b_seq的sequence。其实严格来讲,serial类型是一个“伪类型”,本质上,serial其实是int类型,只不过在创建时会同时创建一个sequence,并与该列相关联,本质上,方法二中的例子与下面的写法等价:
postgres=# create table test(a int, b int) distribute by hash(a);
CREATE TABLE
postgres=# create sequence test_b_seq owned by test.b;
CREATE SEQUENCE
postgres=# alter sequence test_b_seq owner to jerry; --jerry为test表的属主,如果当前用户即为属主,可不执行此语句
ALTER SEQUENCE
postgres=# alter table test alter b set default nextval('test_b_seq'), alter b set not null;
ALTER TABLE
postgres=# \d+ test
Table "public.test"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------+--------------------------------------------------+---------+--------------+-------------
a | integer | | plain | |
b | integer | not null default nextval('test_b_seq'::regclass) | plain | |
Has OIDs: no
Distribute By: HASH(a)
Location Nodes: ALL DATANODES
Options: orientation=row, compression=no
sequence在业务中的常见用法
sequence在业务中常被用作在导入时生成主键或唯一列,常见于数据迁移场景。不同的迁移工具或业务导入场景使用的入库方法不同,常见的方法主要可以分为copy和insert。对于seqeunce来讲,这两种场景在处理时略有差别。
场景一:insert下推场景
postgres=# create table test1(a int, b serial) distribute by hash(a);
NOTICE: CREATE TABLE will create implicit sequence "test1_b_seq" for serial column "test1.b"
CREATE TABLE
postgres=#
postgres=# create table test2(a int) distribute by hash(a);
CREATE TABLE
postgres=#
postgres=#
postgres=# explain verbose insert into test1(a) select a from test2;
QUERY PLAN
------------------------------------------------------------------------------------------------
id | operation | E-rows | E-distinct | E-memory | E-width | E-costs
----+------------------------------------+--------+------------+----------+---------+---------
1 | -> Streaming (type: GATHER) | 1 | | | 4 | 18.41
2 | -> Insert on public.test1 | 40 | | | 4 | 18.25
3 | -> Seq Scan on public.test2 | 40 | | 1MB | 4 | 16.24
Targetlist Information (identified by plan id)
---------------------------------------------------------
1 --Streaming (type: GATHER)
Node/s: All datanodes
3 --Seq Scan on public.test2
Output: test2.a, nextval('test1_b_seq'::regclass)
Distribute Key: test2.a
====== Query Summary =====
-------------------------------
System available mem: 4669440KB
Query Max mem: 4669440KB
Query estimated mem: 1024KB
Parser runtime: 0.045 ms
Planner runtime: 12.622 ms
Unique SQL Id: 972921662
(22 rows)
由于在nextval在insert场景下可以下推到DN执行,因此,不管是使用default值的nextval,还是显示调用nextval,nextval都会被下推到DN执行,在上例的执行计划中也能看出,nextval的调用在sequence层,说明是在DN执行的。此时,DN直接向GTM申请序列值,且各DN并行执行,因此效率相对较高。
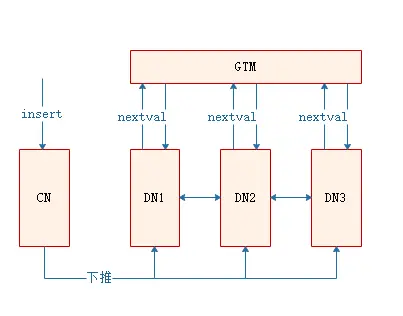
场景二:copy场景
在业务开发过程中,入库方式除了insert外,还有copy入库的场景。此类场景多见于将文件内容copy入库、使用CopyManager接口入库等,此外,CDM数据同步工具,其实现方式也是通过copy的方式批量入库。在copy入库过程中,如果copy的目标表使用了默认值,且默认值为nextval,处理过程如下:
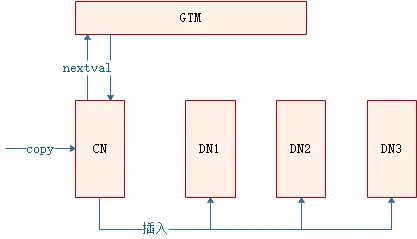
此场景下,由CN负责向GTM申请序列值,因此,当sequence的cache值较小,CN会频繁和GTM建联并申请nextval,出现性能瓶颈。下面,将针对此种场景说明业务上的性能表现和优化方法。
sequence相关的典型优化场景
业务场景:某业务场景使用CDM数据同步工具做数据迁移,从源端入库目标端GaussDB(DWS)。导入速率与经验值相差较大,业务将CDM并发从1调整为5,同步速率仍无法提升。查看语句执行情况,除copy入库外,其余业务均正常执行,无性能瓶颈,且观察无资源瓶颈,因此初步判断为该业务自身存在瓶颈,查看该表copy相关的作业等待视图情况:
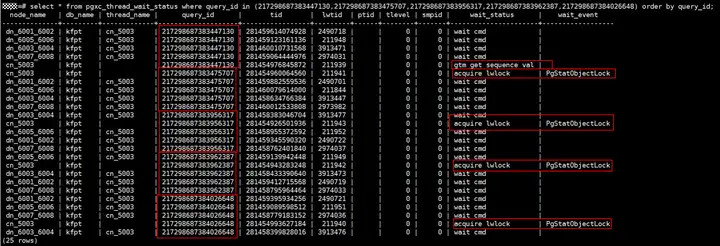
如图所示,由于CDM作业起了5个并发,因此在活跃视图中可以看到5个copy语句,根据这5个copy语句对应的query_id查看等待视图情况如上图所示。可以看到,这5个copy中,同一时刻,仅有1个copy在向GTM申请序列值,其余的copy在等待轻量级锁。因此,即使作业中开启了5并发在运行,实际效果比1并发并不能带来明显提升。
问题原因:目标表在建表时使用了serial类型,默认创建的sequence的cache为1,导致在并发copy入库时,CN频繁与GTM建联,且多个并发之间存在轻量锁争抢,导致数据同步效率低。
解决方案:此种场景下可以调大sequence的cache值,防止频繁GTM建联带来的瓶颈。本例中,业务每次同步的数据量在10万左右,综合其他使用场景评估,将cache值修改为10000(实际使用时应根据业务设置合理的cache值,既能保证快速访问,又不会造成序列号浪费)。
当前GaussDB(DWS)不支持通过alter sequence的方式修改cache值,那么如何修改已有sequence的cache值呢?以第二节中方法二的test表为例,可以通过如下方式达到修改cache的目的:
-- 解除当前sequence与目标表的关联关系
alter sequence test_b_seq owned by none;
alter table test alter b drop default;
-- 记录当前的seqeunce值并删除sequence
select nextval('test_b_seq'); --记录该值,作为新建sequence的start value
drop sequence test_b_seq;
-- 新建seqeunce并绑定目标表
create sequence test_b_seq START with xxx cache 10000 owned by test.b; -- xxx替换为上一步查到的nextval
alter sequence test_b_seq owner to jerry; --jerry为test表的属主,如果当前用户即为属主,可不执行此语句
alter table test alter b set default nextval('test_b_seq'), alter b set not null;
参考链接:
https://bbs.huaweicloud.com/blogs/180833
https://bbs.huaweicloud.com/blogs/338904
详解数仓中sequence的应用场景及优化的更多相关文章
- 一文详解数仓GaussDB(DWS) 函数出参带出方式
摘要:本文主要讲解DWS函数出参带出方式. 本文分享自华为云社区<GaussDB(DWS)功能 -- 函数出参 #[玩转PB级数仓GaussDB(DWS)]>,作者:譡里个檔 . DWS的 ...
- TCP/IP详解--发送ACK和RST的场景
在有以下几种情景,TCP会把ack包发出去: 1.收到1个包,启动200ms定时器,等到200ms的定时器到点了(第二个包没来),于是对这个包的确认ack被发送.这叫做“延迟发送”: 2.收到1个包, ...
- 深入解析ThreadLocal 详解、实现原理、使用场景方法以及内存泄漏防范 多线程中篇(十七)
简介 从名称看,ThreadLocal 也就是thread和local的组合,也就是一个thread有一个local的变量副本 ThreadLocal提供了线程的本地副本,也就是说每个线程将会拥有一个 ...
- jQuery:详解jQuery中的事件(二)
上一篇讲到jQuery中的事件,深入学习了加载DOM和事件绑定的相关知识,这篇主要深入讨论jQuery事件中的合成事件.事件冒泡和事件移除等内容. 接上篇jQuery:详解jQuery中的事件(一) ...
- 图文详解Unity3D中Material的Tiling和Offset是怎么回事
图文详解Unity3D中Material的Tiling和Offset是怎么回事 Tiling和Offset概述 Tiling表示UV坐标的缩放倍数,Offset表示UV坐标的起始位置. 这样说当然是隔 ...
- 【转】详解C#中的反射
原帖链接点这里:详解C#中的反射 反射(Reflection) 2008年01月02日 星期三 11:21 两个现实中的例子: 1.B超:大家体检的时候大概都做过B超吧,B超可以透过肚皮探测到你内 ...
- 详解Webwork中Action 调用的方法
详解Webwork中Action 调用的方法 从三方面介绍webwork action调用相关知识: 1.Webwork 获取和包装 web 参数 2.这部分框架类关系 3.DefaultAction ...
- 【转】详解JavaScript中的this
ref:http://blog.jobbole.com/39305/ 来源:foocoder 详解JavaScript中的this JavaScript中的this总是让人迷惑,应该是js众所周知的坑 ...
- 深入详解SQL中的Null
深入详解SQL中的Null NULL 在计算机和编程世界中表示的是未知,不确定.虽然中文翻译为 “空”, 但此空(null)非彼空(empty). Null表示的是一种未知状态,未来状态,比如小明兜里 ...
- java 乱码详解_jsp中pageEncoding、charset=UTF -8"、request.setCharacterEncoding("UTF-8")
http://blog.csdn.net/qinysong/article/details/1179480 java 乱码详解__jsp中pageEncoding.charset=UTF -8&quo ...
随机推荐
- node_exporter安装
1.node_exporter下载 node_exporter-1.3.1.linux-amd64.tar.gz tar -xzvf node_exporter-1.3.1.linux-amd64.t ...
- aspose word导出表格
[HttpGet] [Route("GetPurchaseItemWord")] public IHttpActionResult Get_PurchaseItemWord(str ...
- Redis基础命令和持久化
Redis命令工具 Redis-server :用于启动Redis的工具 Redis-benchmark:用于检查Redis在本机的运行效率 Redis-check-aof:修复aof持久化文件 Re ...
- ASCII,unicode与utf-8的区别
ASCII,unicode与utf-8的区别: ASCII码只有127个字母被编到计算机中,无法处理中文,ASCII 编码是 1 个字节 unicode是为了解决因各国标准不同而产生乱码的问题.uni ...
- Java基础|01.基础语法(1)
目录 00x1 基本语法 1.类的语法 2.对象的语法 3.方法的声明 4.小例子 00x2 类和对象的关系 1.堆.栈和元空间 2.基本数据类型和引用数据类型的区别 3. 空对象(null) 00x ...
- AX2012 循环读取DataSource的记录
static void LoopFormDataSource(Args _args) { FormDataSource formDataSource; SalesLine salesLineSel, ...
- 自己制作Switch大气层SDFile
️SWITCH SDFILE 每次吃灰之后,就想更新下系统,每次都得研究一遍... 决定好好研究下,发现不是很繁琐. SDFile有哪些文件组成! Atmosphere 任天堂Switch定制固件 H ...
- Android studio 使用Internet传递信息
使用Intent在Activity之间传递信息1.首先创建一个新的Activity,在activity_main.xml中设计页面,将android.support.constraint.Constr ...
- c 理解
exit() 的含义:提前结束程序 .c 文件 return的含义 :提前结束函数,其所在行以下,整体大函数底花括号以上,2者之间的所有语句都不会被执行到,用它来提前结束程序. break的含义 :提 ...
- spring cloud alibaiba的POM引入
POM添加spring cloud alibaba相关jar包 1 <dependency> 2 <groupId>org.springframework.boot</g ...