【Hadoop】ZooKeeper组件
需要在Hadoop-全分布式配置的基础上进行配置
一、配置时间同步
(在所有节点上)
# 以master为例
# 安装chrony
[root@master ~]# yum -y install chrony
# 编辑配置文件
[root@master ~]# vi /etc/chrony.conf
server 0.time1.aliyun.com iburst
# 开启chronyd
[root@master ~]# systemctl restart chronyd
[root@master ~]# systemctl enable chronyd
Created symlink from /etc/systemd/system/multi-user.target.wants/chronyd.service to /usr/lib/systemd/system/chronyd.service.
# 查看状态
[root@master ~]# systemctl status chronyd
● chronyd.service - NTP client/server
Loaded: loaded (/usr/lib/systemd/system/chronyd.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2022-04-22 15:00:38 CST; 3min 31s ago
Process: 795 ExecStartPost=/usr/libexec/chrony-helper update-daemon (code=exited, status=0/SUCCESS)
Process: 762 ExecStart=/usr/sbin/chronyd $OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 781 (chronyd)
CGroup: /system.slice/chronyd.service
└─781 /usr/sbin/chronyd
Apr 22 15:00:37 master.example.com systemd[1]: Starting NTP client/server...
Apr 22 15:00:37 master.example.com chronyd[781]: chronyd version 2.1.1 starting (+CMDMON +NT...H)
Apr 22 15:00:38 master.example.com chronyd[781]: Frequency 0.000 +/- 1000000.000 ppm read fr...ft
Apr 22 15:00:38 master.example.com systemd[1]: Started NTP client/server.
Hint: Some lines were ellipsized, use -l to show in full.
# 看到running则表示成功
二、部署zookeeper(master节点)
1、使用xftp上传软件包至~
2、解压安装包
[root@master ~]# tar xf zookeeper-3.4.8.tar.gz -C /usr/local/src/
[root@master ~]# cd /usr/local/src/
[root@master src]# mv zookeeper-3.4.8 zookeeper
3、创建 data 和 logs 文件夹
[root@master src]# cd /usr/local/src/zookeeper/
[root@master zookeeper]# mkdir data logs
4、写入该节点的标识编号
[root@master zookeeper]# echo '1' > /usr/local/src/zookeeper/data/myid
5、修改配置文件 zoo.cfg
[root@master zookeeper]# cd /usr/local/src/zookeeper/conf/
[root@master conf]# cp zoo_sample.cfg zoo.cfg
[root@master conf]# vi zoo.cfg
dataDir=/usr/local/src/zookeeper/data
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
# 表示三个 ZooKeeper 节点的访问端口号
6、配置环境变量zookeeper.sh
[root@master conf]# vi /etc/profile.d/zookeeper.sh
export ZOOKEEPER_HOME=/usr/local/src/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
7、修改目录的归属用户
[root@master conf]# chown -R hadoop.hadoop /usr/local/src/
8、拷贝文件到slave
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave1:/etc/profile.d/
zookeeper.sh 100% 87 0.1KB/s 00:00
[root@master conf]# scp /etc/profile.d/zookeeper.sh slave2:/etc/profile.d/
zookeeper.sh 100% 87 0.1KB/s 00:00
9、修改目录的归属用户
# 在slave1节点
[root@slave1 ~]# chown -R hadoop.hadoop /usr/local/src/
# 在slave2节点
[root@slave2 ~]# chown -R hadoop.hadoop /usr/local/src/
10、写入每个节点的标识编号
# 在slave1节点
[root@slave1 ~]# echo '2' > /usr/local/src/zookeeper/data/myid
# 在slave2节点
[root@slave2 ~]# echo '3' > /usr/local/src/zookeeper/data/myid
三、启动 ZooKeeper
master节点
[root@master conf]# su - hadoop
Last login: Fri Apr 22 16:26:07 CST 2022 on pts/0
[hadoop@master ~]$ jps
43248 QuorumPeerMain
44316 Jps
# 看到QuorumPeerMain进程才表示成功
[hadoop@master ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@master ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
# 确保能够看到1个leader, 2个follower才表示启动成功
slave1节点
[root@slave1 ~]# su - hadoop
[hadoop@slave1 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... already running as process 42747.
[hadoop@slave1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: leader
slave2节点
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@slave2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/src/zookeeper/bin/../conf/zoo.cfg
Mode: follower
四、部署HBase
步骤和【Hadoop】HBase组件配置步骤一样
只有hbase-env.sh配置文件下true改为false
vi hbase-env.sh
export JAVA_HOME=/usr/local/src/jdk
export HBASE_MANAGES_ZK=false
export HBASE_CLASSPATH=/usr/local/src/hadoop/etc/hadoop/
五、启动hadoop
# 在master上启动分布式hadoop集群
[hadoop@master ~]$ start-all.sh
[hadoop@master ~]$ jps
3210 Jps
2571 NameNode
2780 SecondaryNameNode
2943 ResourceManager
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2756 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3379 Jps
3239 NodeManager
3135 DataNode
#确保master上有NameNode、SecondaryNameNode、 ResourceManager进程, slave节点上要有DataNode、NodeManager进程
六、启动hbase
[hadoop@master ~]$ start-hbase.sh
[hadoop@master ~]$ jps
3569 HMaster
2571 NameNode
2780 SecondaryNameNode
3692 Jps
2943 ResourceManager
3471 HQuorumPeer
# 查看slave1节点
[hadoop@slave1 ~]$ jps
2512 DataNode
2818 HQuorumPeer
2933 HRegionServer
3094 Jps
2623 NodeManager
# 查看slave2节点
[hadoop@slave2 ~]$ jps
3239 NodeManager
3705 Jps
3546 HRegionServer
3437 HQuorumPeer
3135 DataNode
# 确保master上有HQuorumPeer、HMaster进程,slave节点上要有HQuorumPeer、HRegionServer进程
七、查看浏览器页面
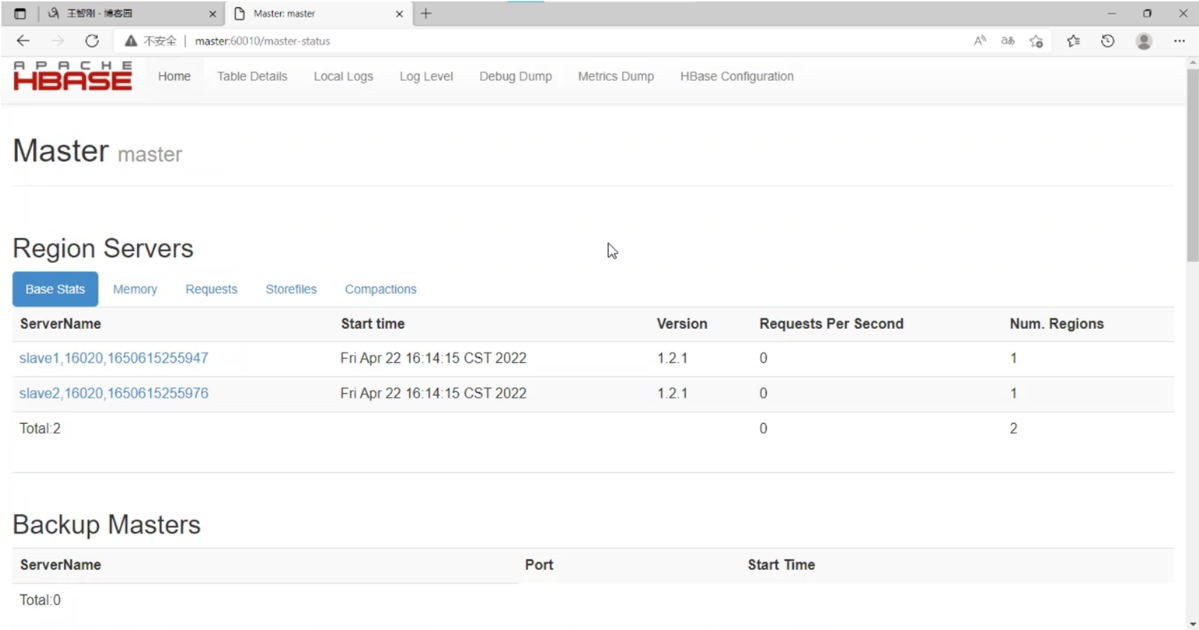
声明:未经许可,不得转载
【Hadoop】ZooKeeper组件的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop以及组件介绍
一.背景介绍 在接触过大数据相关项目的时候常常都会听到Hadoop这个东西,简单来说,他是一个用分布式计算来处理大数据的开源软件,下面包含了许多的组件和子项目,这篇文章将会介绍Hadoop的原理以及一 ...
- ZooKeeper 组件安装配置
ZooKeeper 组件安装配置 下载和安装 ZooKeeper ZooKeeper最新的版本可以通过官网 http://hadoop.apache.org/zookeeper/ 来获取,安装 Zoo ...
- 安装hadoop+zookeeper ha
安装hadoop+zookeeper ha 前期工作配置好网络和主机名和关闭防火墙 chkconfig iptables off //关闭防火墙 1.安装好java并配置好相关变量 (/etc/pro ...
- HA分布式集群一hadoop+zookeeper
一:HA分布式配置的优势: 1,防止由于一台namenode挂掉,集群失败的情形 2,适合工业生产的需求 二:HA安装步骤: 1,安装虚拟机 1,型号:VMware_workstation_full_ ...
- hadoop+zookeeper+hbase分布式安装
前期服务器配置 修改/etc/hosts文件,添加以下信息(如果正常IP) 119.23.163.113 master 120.79.116.198 slave1 120.79.116.23 slav ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- (十七)整合 Zookeeper组件,管理架构中服务协调
整合 Zookeeper组件,管理架构中服务协调 1.Zookeeper基础简介 1.1 基本理论 1.2 应用场景 2.安全管理操作 2.1 操作权限 2.2 认证方式: 2.3 Digest授权流 ...
- Hadoop-HA 搭建高可用集群Hadoop Zookeeper
Hadoop Zookeeper 搭建(一) 一.准备工作 VMWARE虚拟机 CentOS 7 系统 虚拟机1:master 虚拟机2:node1 虚拟机3:node2 时间同步 ntpdate n ...
随机推荐
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 使用Spring框架的好处是什么?
轻量:Spring 是轻量的,基本的版本大约2MB. 控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们. 面向切面的编程(AOP):Spring支持 ...
- nginx使用与配置
一.nginx操作命令 nginx常用命令: 验证配置是否正确: nginx -t 查看Nginx的版本号:nginx -V 启动Nginx:start nginx 重新加载nginx:nginx.e ...
- 什么是 spring 的内部 bean?
只有将 bean 用作另一个 bean 的属性时,才能将 bean 声明为内部 bean. 为了定义 bean,Spring 的基于 XML 的配置元数据在 <property> 或 &l ...
- 如何从https://developer.mozilla.org上查询对象的属性、方法、事件使用说明和示例
在https://developer.mozilla.org搜索要在前面加上指令 搜索之后点进去 进入之后就是这样的 在页面左边你可以选择自己要查询的对象 里面就是会有属性.方法.事件使用说明和示例.
- MM32F0140 UART1硬件自动波特率校准功能的使用
目录: 1.MM32F0140简介 2.UART自动波特率校准应用场景 3.MM32F0140 UART自动波特率校准原理简介 4.MM32F0140 UART1 NVIC硬件自动波特率配置以及初始化 ...
- 如何在 Microsoft word中插入代码
一.工具 方法1.打开这个网页PlanetB; 方法2.或者谷歌搜索syntax highlight code in word documents,检索结果的第一个.如下图: PS. 方法1和2打开的 ...
- 面试题目:手写一个LRU算法实现
一.常见的内存淘汰算法 FIFO 先进先出 在这种淘汰算法中,先进⼊缓存的会先被淘汰 命中率很低 LRU Least recently used,最近最少使⽤get 根据数据的历史访问记录来进⾏淘汰 ...
- C++中类所占的内存大小以及成员函数的存储位置
类所占内存的大小是由成员变量(静态变量除外)决定的,虚函数指针和虚基类指针也属于数据部分,成员函数是不计算在内的.因为在编译器处理后,成员变量和成员函数是分离的.成员函数还是以一般的函数一样的存在.a ...
- 前端基础问题整理-HTML相关
DOCTYPE的作用以及常见的DOCTYPE类型 <!DOCTYPE>声明位于文档中的最前面的位置,处于 <html> 标签之前,用来告知浏览器页面目前的文件是用哪种版本的HT ...