隐私计算FATE-离线预测

一、说明
Fate 的模型预测有 离线预测 和 在线预测 两种方式,两者的效果是一样的,主要是使用方式、适用场景、高可用、性能等方面有很大差别;本文分享使用 Fate 基于 纵向逻辑回归 算法训练出来的模型进行离线预测实践。
- 基于上文 《隐私计算FATE-模型训练》 中训练出来的模型进行预测任务
- 关于 Fate 的安装部署可参考文章 《隐私计算FATE-概念与单机部署指南》
二、查询模型信息
执行以下命令,进入 Fate 的容器中:
docker exec -it $(docker ps -aqf "name=standalone_fate") bash
首先我们需要获取模型对应的 model_id 和 model_version 信息,可以通过 job_id 执行以下命令获取:
flow job config -j 202205070226373055640 -r guest -p 9999 --output-path /data/projects/fate/examples/my_test/
job_id 可以在 FATE Board 中查看。
执行成功后会返回对应的模型信息,以及在指定目录下生成一个文件夹 job_202205070226373055640_config
{
"data": {
"job_id": "202205070226373055640",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070226373055640"
},
"train_runtime_conf": {}
},
"retcode": 0,
"retmsg": "download successfully, please check /data/projects/fate/examples/my_test/job_202205070226373055640_config directory",
"directory": "/data/projects/fate/examples/my_test/job_202205070226373055640_config"
}
job_202205070226373055640_config 里面包含4个文件:
- dsl.json:任务的 dsl 配置。
- model_info.json:模型信息。
- runtime_conf.json:任务的运行配置。
- train_runtime_conf.json:空。
三、模型部署
执行以下命令:
flow model deploy --model-id arbiter-10000#guest-9999#host-10000#model --model-version 202205070226373055640
分别通过 --model-id 与 --model-version 指定上面步骤查询到的 model_id 和 model_version
部署成功后返回:
{
"data": {
"arbiter": {
"10000": 0
},
"detail": {
"arbiter": {
"10000": {
"retcode": 0,
"retmsg": "deploy model of role arbiter 10000 success"
}
},
"guest": {
"9999": {
"retcode": 0,
"retmsg": "deploy model of role guest 9999 success"
}
},
"host": {
"10000": {
"retcode": 0,
"retmsg": "deploy model of role host 10000 success"
}
}
},
"guest": {
"9999": 0
},
"host": {
"10000": 0
},
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070730131040240"
},
"retcode": 0,
"retmsg": "success"
}
部署成功后返回一个新的 model_version
四、准备预测配置
执行以下命令:
cp /data/projects/fate/examples/dsl/v2/hetero_logistic_regression/hetero_lr_normal_predict_conf.json /data/projects/fate/examples/my_test/
直接把 Fate 自带的纵向逻辑回归算法预测配置样例,复制到我们的
my_test目录下。
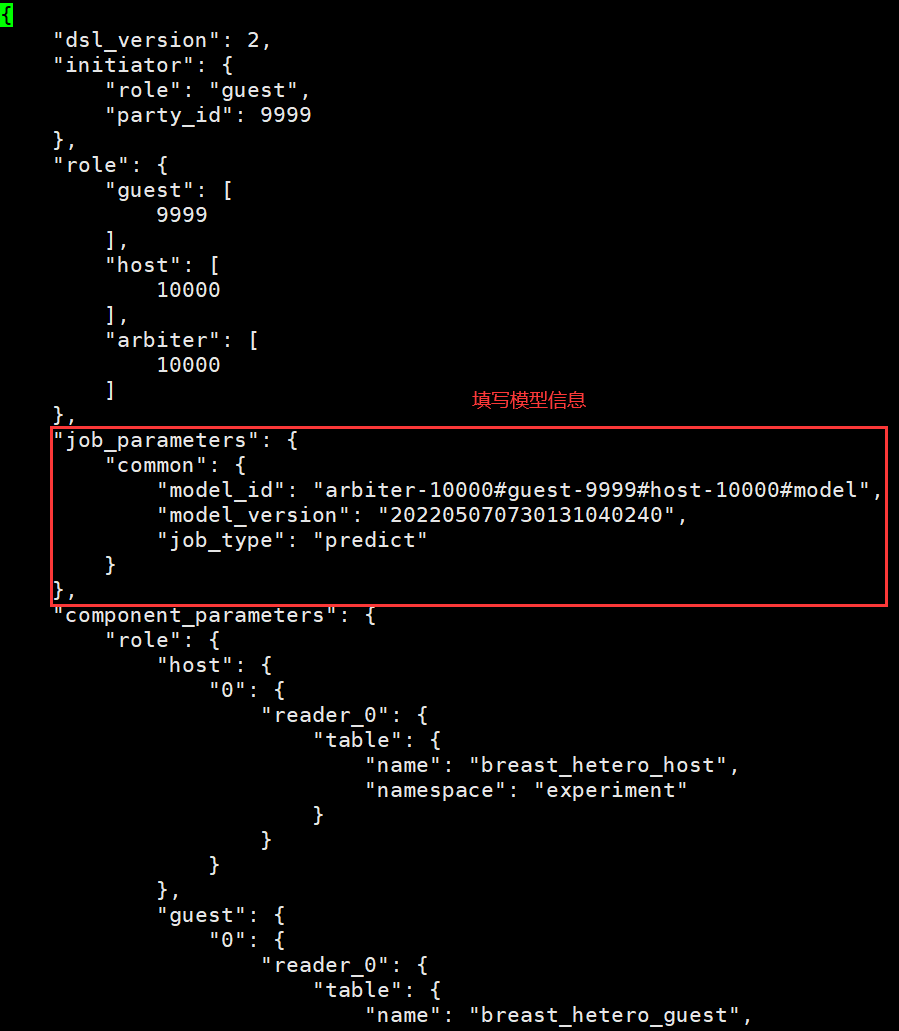
预测的配置文件主要配置三部分:
- 上面部分为配置发起者以及参与方角色
- 中间部分需要填入正确的 模型信息
- 下面的则为预测使用的数据表
唯一需要修改的就是中间的 模型信息 部分;需要注意的是这里输入的版本号是 模型部署 后返回的版本号,并且需要增加 job_type 为 predict 指定任务类型为预测任务。
五、执行预测任务
执行以下命令:
flow job submit -c hetero_lr_normal_predict_conf.json
与模型训练一样也是使用 submit 命令,通过 -c 指定配置文件。
执行成功后返回:
{
"data": {
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202205070731385067720&role=guest&party_id=9999",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/job_dsl.json",
"job_id": "202205070731385067720",
"logs_directory": "/data/projects/fate/fateflow/logs/202205070731385067720",
"message": "success",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070730131040240"
},
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/guest/9999/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/job_runtime_conf.json",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/train_runtime_conf.json"
},
"jobId": "202205070731385067720",
"retcode": 0,
"retmsg": "success"
}
六、查看预测结果
可以通过返回的 board_url 或者 job_id 去 FATE Board 里查看结果,但是图形化界面里最多只能查看 100 条记录;
我们可以通过 output-data 命令,导出指定组件的所有数据输出:
flow tracking output-data -j 202205070731385067720 -r guest -p 9999 -cpn hetero_lr_0 -o /data/projects/fate/examples/my_test/predict
- -j:指定预测任务的 job_id
- -cpn:指定组件名。
- -o:指定输出的目录。
执行成功后返回:
{
"retcode": 0,
"directory": "/data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data",
"retmsg": "Download successfully, please check /data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data directory"
}
在目录 /data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data 中可以看到两个文件:
- data.csv:为输出的所有数据。
- data.meta:为数据的列头。
扫码关注有惊喜!

隐私计算FATE-离线预测的更多相关文章
- 隐私计算FATE-多分类神经网络算法测试
一.说明 本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测. 二分类算法:是指待预测的 label 标签的取值只有两种:直白来 ...
- 隐私计算FATE-模型训练
一.说明 本文分享基于 Fate 自带的测试样例,进行 纵向逻辑回归 算法的模型训练,并且通过 FATE Board 可视化查看结果. 本文的内容为基于 <隐私计算FATE-概念与单机部署指南& ...
- HMM的概率计算问题和预测问题的java实现
HMM(hidden markov model)可以用于模式识别,李开复老师就是采用了HMM完成了语音识别. 一下的例子来自于<统计学习方法> 一个HMM由初始概率分布,状态转移概率分布, ...
- 用MATLAB生成模糊控制离线查询表
实时采样得到的数据经过模糊化处理后输入机器,通过查询模糊规则表便可得到应有的输出模糊量,从而避免了近似推理过程.实际应用中,特别是在控制系统较为简单而采用单片机控制时,常常采用这种查表法. 模糊控制表 ...
- Others-阿里专家强琦:流式计算的系统设计和实现
阿里专家强琦:流式计算的系统设计和实现 更多深度文章,请关注云计算频道:https://yq.aliyun.com/cloud 阿里云数据事业部强琦为大家带来题为“流式计算的系统设计与实现”的演讲,本 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 关于k8s这项大动作,预示着边缘计算迎来“开源”发展的新周期……
在文章<最近在边缘计算领域,发生了一件足以载入物联网史册的大事…>我曾经提到Kubernetes(简称K8s)将从超大规模云计算环境,被带入到物联网边缘计算场景中. 事情有了新进展,从本周 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- Titanic幸存预测分析(Kaggle)
分享一篇kaggle入门级案例,泰坦尼克号幸存遇难分析. 参考文章: 技术世界,原文链接 http://www.jasongj.com/ml/classification/ 案例分析内容: 通过训练集 ...
随机推荐
- Conda安装及第一个py程序
Conda安装及第一个py程序 安装Conda 下载安装 在Anaconda官网下载Anaconda 打开Conda安装程序 设置好安装目录(这个一定要记好,后边要用),比如我的目录就是 D:\Pro ...
- JavaScript学习总结2-对象
JavaScript中对象除了最后一个属性以外都在结尾加逗号,同时所有属性都要在{ }内 1 <!DOCTYPE html> 2 <html lang="en"& ...
- python基础练习题(题目 输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数)
day10 --------------------------------------------------------------- 实例017:字符串构成 题目 输入一行字符,分别统计出其中英 ...
- 甲骨文严查Java授权,换openJDK要避坑
背景 外媒The Register报道,甲骨文稽查企业用户,近期开始将把过去看管较松散的Java授权加入. 甲骨文针对标准版Java(Java SE)有2种商业授权.2019年4月甲骨文宣布Java ...
- IDEA编译项目后,target目录下的jsp文件不更新
tomcat目录说明 先来看一下tomcat的目录: |-bin |-conf |-lib |-logs |-temp |-webapps |-work tomcat 的核心是servlet容器,叫 ...
- uniapp 入门
uniapp官网 uni-app 是一个使用 Vue.js (opens new window)开发所有前端应用的框架,开发者编写一套代码,可发布到iOS.Android.Web(响应式).以及各种小 ...
- .NET桌面程序应用WebView2组件集成网页开发3 WebView2的进程模型
系列目录 [已更新最新开发文章,点击查看详细] WebView2 运行时使用与 Microsoft Edge 浏览器相同的进程模型. WebView2 运行时中的进程 WebView2 进程组 ...
- 论文阅读 Streaming Graph Neural Networks
3 Streaming Graph Neural Networks link:https://dl.acm.org/doi/10.1145/3397271.3401092 Abstract 本文提出了 ...
- CentOS 下 MySQL 8.0 安装部署,超详细!
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! Mysql8.0安装 (YUM方式) 首先删除系统默认或 ...
- 关于扑克牌的一些讨论——《Fluent Python 2》读书笔记
一.说明 参考资料为维基百科的 Playing Card 词条,非严肃性论证,只是对代码为什么这么写做讨论. 二.扑克牌的起源 import collections Card = collection ...