隐私计算FATE-多分类神经网络算法测试

一、说明
本文分享基于 Fate 使用 横向联邦 神经网络算法 对 多分类 的数据进行 模型训练,并使用该模型对数据进行 多分类预测。
- 二分类算法:是指待预测的 label 标签的取值只有两种;直白来讲就是每个实例的可能类别只有两种(0 或者 1),例如性别只有 男 或者 女;此时的分类算法其实是在构建一个分类线将数据划分为两个类别。
- 多分类算法:是指待预测的 label 标签的取值可能有多种情况,例如个人爱好可能有 篮球、足球、电影 等等多种类型。常见算法:Softmax、SVM、KNN、决策树。
关于 Fate 的核心概念、单机部署、训练以及预测请参考以下相关文章:
二、准备训练数据
上传到 Fate 里的数据有两个字段名必需是规定的,分别是主键为 id 字段和分类字段为 y 字段,y 字段就是所谓的待预测的 label 标签;其他的特征字段(属性)可任意填写,例如下面例子中的 x0 - x9
例如有一条用户数据为:
收入: 10000,负债: 5000,是否有还款能力: 1 ;数据中的收入和负债就是特征字段,而是否有还款能力就是分类字段。
本文只描述关键部分,关于详细的模型训练步骤,请查看文章《隐私计算FATE-模型训练》
2.1. guest端
10条数据,包含1个分类字段 y 和 10 个标签字段 x0 - x9
y 值有 0、1、2、3 四个分类
上传到 Fate 中,表名为 muti_breast_homo_guest 命名空间为 experiment
2.2. host端
10条数据,字段与 guest 端一样,但是内容不一样
上传到 Fate 中,表名为 muti_breast_homo_host 命名空间为 experiment
三、执行训练任务
3.1. 准备dsl文件
创建文件 homo_nn_dsl.json 内容如下 :
{
"components": {
"reader_0": {
"module": "Reader",
"output": {
"data": [
"data"
]
}
},
"data_transform_0": {
"module": "DataTransform",
"input": {
"data": {
"data": [
"reader_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
},
"homo_nn_0": {
"module": "HomoNN",
"input": {
"data": {
"train_data": [
"data_transform_0.data"
]
}
},
"output": {
"data": [
"data"
],
"model": [
"model"
]
}
}
}
}
3.2. 准备conf文件
创建文件 homo_nn_multi_label_conf.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true
},
"homo_nn_0": {
"encode_label": true,
"max_iter": 15,
"batch_size": -1,
"early_stop": {
"early_stop": "diff",
"eps": 0.0001
},
"optimizer": {
"learning_rate": 0.05,
"decay": 0.0,
"beta_1": 0.9,
"beta_2": 0.999,
"epsilon": 1e-07,
"amsgrad": false,
"optimizer": "Adam"
},
"loss": "categorical_crossentropy",
"metrics": [
"accuracy"
],
"nn_define": {
"class_name": "Sequential",
"config": {
"name": "sequential",
"layers": [
{
"class_name": "Dense",
"config": {
"name": "dense",
"trainable": true,
"batch_input_shape": [
null,
18
],
"dtype": "float32",
"units": 5,
"activation": "relu",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
},
{
"class_name": "Dense",
"config": {
"name": "dense_1",
"trainable": true,
"dtype": "float32",
"units": 4,
"activation": "sigmoid",
"use_bias": true,
"kernel_initializer": {
"class_name": "GlorotUniform",
"config": {
"seed": null,
"dtype": "float32"
}
},
"bias_initializer": {
"class_name": "Zeros",
"config": {
"dtype": "float32"
}
},
"kernel_regularizer": null,
"bias_regularizer": null,
"activity_regularizer": null,
"kernel_constraint": null,
"bias_constraint": null
}
}
]
},
"keras_version": "2.2.4-tf",
"backend": "tensorflow"
},
"config_type": "keras"
}
},
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_host",
"namespace": "experiment"
}
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
}
}
}
}
注意
reader_0组件的表名和命名空间需与上传数据时配置的一致。
3.3. 提交任务
执行以下命令:
flow job submit -d homo_nn_dsl.json -c homo_nn_multi_label_conf.json
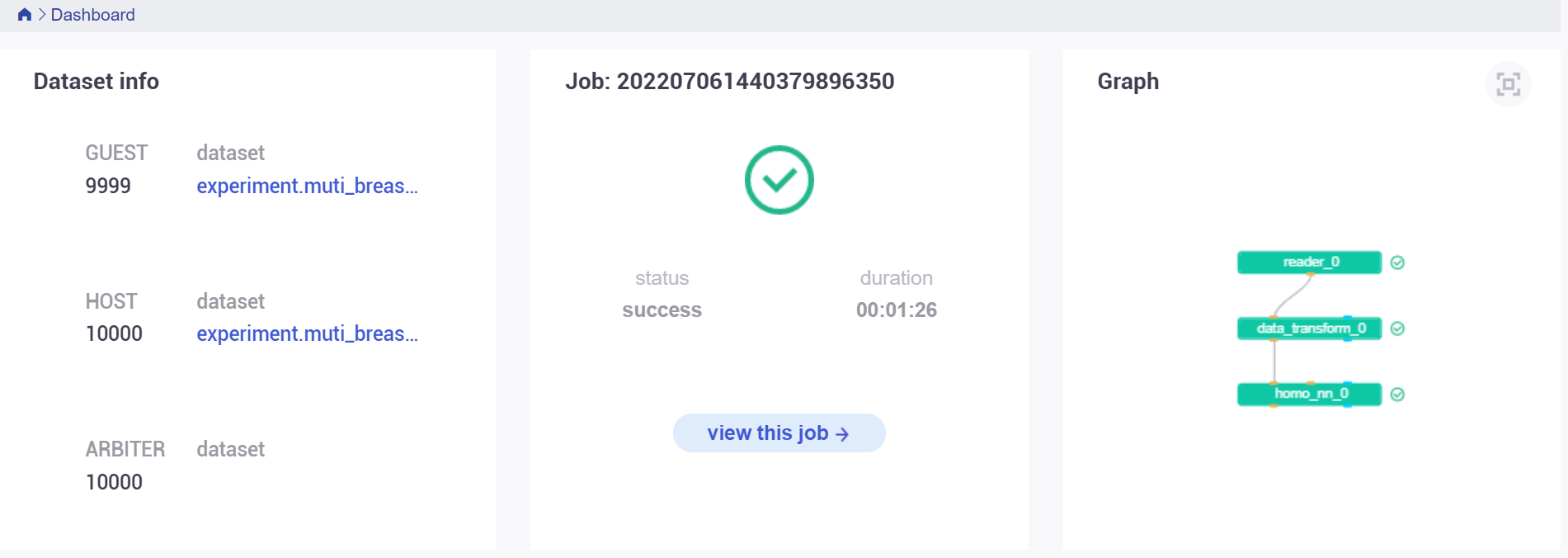
执行成功后,查看 dashboard 显示:
四、准备预测数据
与前面训练的数据字段一样,但是内容不一样,y 值全为 0
4.1. guest端
上传到 Fate 中,表名为 predict_muti_breast_homo_guest 命名空间为 experiment
4.2. host端
上传到 Fate 中,表名为 predict_muti_breast_homo_host 命名空间为 experiment
五、准备预测配置
本文只描述关键部分,关于详细的预测步骤,请查看文章《隐私计算FATE-离线预测》
创建文件 homo_nn_multi_label_predict.json 内容如下 :
{
"dsl_version": 2,
"initiator": {
"role": "guest",
"party_id": 9999
},
"role": {
"arbiter": [
10000
],
"host": [
10000
],
"guest": [
9999
]
},
"job_parameters": {
"common": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202207061504081543620",
"job_type": "predict"
}
},
"component_parameters": {
"role": {
"guest": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_guest",
"namespace": "experiment"
}
}
}
},
"host": {
"0": {
"reader_0": {
"table": {
"name": "predict_muti_breast_homo_host",
"namespace": "experiment"
}
}
}
}
}
}
}
注意以下两点:
model_id和model_version需修改为模型部署后的版本号。
reader_0组件的表名和命名空间需与上传数据时配置的一致。
五、执行预测任务
执行以下命令:
flow job submit -c homo_nn_multi_label_predict.json
执行成功后,查看 homo_nn_0 组件的数据输出:

可以看到算法输出的预测结果。
扫码关注有惊喜!

隐私计算FATE-多分类神经网络算法测试的更多相关文章
- 《BI那点儿事》Microsoft 神经网络算法
Microsoft神经网络是迄今为止最强大.最复杂的算法.要想知道它有多复杂,请看SQL Server联机丛书对该算法的说明:“这个算法通过建立多层感知神经元网络,建立分类和回归挖掘模型.与Micro ...
- 数据挖掘系列(9)——BP神经网络算法与实践
神经网络曾经很火,有过一段低迷期,现在因为深度学习的原因继续火起来了.神经网络有很多种:前向传输网络.反向传输网络.递归神经网络.卷积神经网络等.本文介绍基本的反向传输神经网络(Backpropaga ...
- 利用神经网络算法的C#手写数字识别
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载Demo - 2.77 MB (原始地址):handwritten_character_recognition.zip 下载源码 - 70. ...
- 使用Python scikit-learn 库实现神经网络算法
1:神经网络算法简介 2:Backpropagation算法详细介绍 3:非线性转化方程举例 4:自己实现神经网络算法NeuralNetwork 5:基于NeuralNetwork的XOR实例 6:基 ...
- 吴裕雄 python 人工智能——基于神经网络算法在智能医疗诊断中的应用探索代码简要展示
#K-NN分类 import os import sys import time import operator import cx_Oracle import numpy as np import ...
- 经典卷积神经网络算法(5):ResNet
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 利用神经网络算法的C#手写数字识别(一)
利用神经网络算法的C#手写数字识别 转发来自云加社区,用于学习机器学习与神经网络 欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 下载Demo - 2.77 MB (原始地址):handwri ...
- 隐私计算FATE-模型训练
一.说明 本文分享基于 Fate 自带的测试样例,进行 纵向逻辑回归 算法的模型训练,并且通过 FATE Board 可视化查看结果. 本文的内容为基于 <隐私计算FATE-概念与单机部署指南& ...
- 如何用70行Java代码实现深度神经网络算法(转)
对于现在流行的深度学习,保持学习精神是必要的——程序员尤其是架构师永远都要对核心技术和关键算法保持关注和敏感,必要时要动手写一写掌握下来,先不用关心什么时候用到——用不用是政治问题,会不会写是技术问题 ...
随机推荐
- 20202127 实验一《Python程序设计》实验报告
20202127 2022-2022-2 <Python程序设计>实验一报告课程:<Python程序设计>班级: 2021姓名: 马艺洲学号:20202127实验教师:王志强实 ...
- SerialPort-4.0.+ 使用说明(Java版本)
SerialPort-4.0.+ 项目官网 Kotlin版本使用说明 介绍 SerialPort 是一个开源的对 Android 蓝牙串口通信的轻量封装库,轻松解决了构建自己的串口调试APP的复杂程度 ...
- 实践 - 搭建Redis一主两从三哨兵
实践 - 搭建Redis一主两从三哨兵 原因: 最近在复习Redis的时候,学习到了为了提高Redis集群的高可用性,有一个模式为哨兵模式.哨兵模式的作用是为了在主节点出现阻塞或者错误,无法接收数据的 ...
- SpringBoot 如何统一后端返回格式
在前后端分离的项目中后端返回的格式一定要友好,不然会对前端的开发人员带来很多的工作量.那么SpringBoot如何做到统一的后端返回格式呢?今天我们一起来看看. 为什么要对SpringBoot返回统一 ...
- 记一次burp suite文件上传漏洞实验
一·文件上传漏洞概念 文件上传漏洞是指 Web 服务器允许用户在没有充分验证文件名称.类型.内容或大小等内容的情况下将文件上传到其文件系统.未能正确执行这些限制可能意味着 即使是基本的图像上传功能也可 ...
- [还不会搭建博客吗?]centos7系统部署hexo博客新手入门-进阶,看这一篇就够了
@ 目录 *本文说明 请大家务必查看 前言 首先介绍一下主角:Hexo 什么是 Hexo? 环境准备 详细版 入门:搭建步骤 安装git: 安装node: 安装Hexo: 进阶:hexo基本操作 发布 ...
- wait 和async,await一起使用引发的死锁问题
在某个项目开发过程中,偶然间发现在UI线程中async,await,wait三者一起使用会引发一个必然性的死锁问题. 一个简单的实例,代码很简单,在界面上放置一个Button,并在Button的cli ...
- 如何实现将拖动物体限制在某个圆形内--实现方式vue3.0
如何实现蓝色小圆可拖动,并且边界限制在灰色大圆内?如下所示 需求源自 业务上遇到一个组件需求,设计师设计了一个"脸型整合器"根据可拖动小圆的位置与其它脸型的位置关系计算融合比例 如 ...
- SQL Server之自动创建视图
本方法只适合特定模式的视图创建. 比如,创建需要整张表列名的视图,或者当表和需要的列名统计在一张数据表当中,如图所示: 首先要先获取要创建视图所需要的表,这里我获取的是整个数据库中的表, IF OBJ ...
- 技术分享 | 想做App测试就一定要了解的App结构
本文节选自霍格沃兹测试开发学社内部教材 app 的结构包含了 APK 结构和 app 页面结构两个部分 APK结构 APK 是 Android Package 的缩写,其实就是 Android 的安装 ...