[sklearn] 决策树、随机森林、隐马尔可夫模型
决策树
决策树(Decision Tree)是一种用于处理分类和回归问题的无监督学习算法。如下图所示为某女青年在某相亲网站的相亲决策图。这幅图描述的都是一个非常典型的决策树模型。
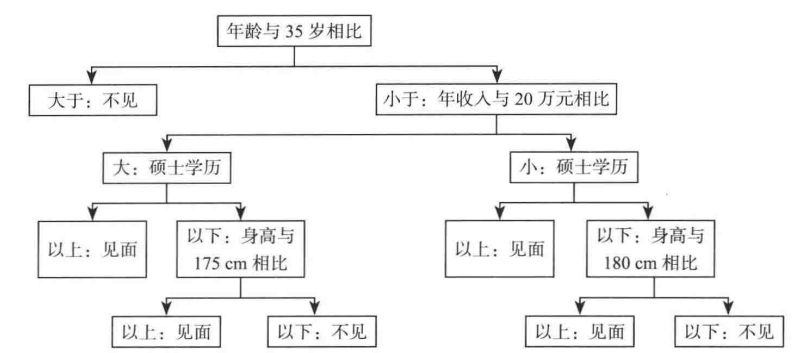
通过对其相亲决策的分析,假设其相亲信息如下所示:
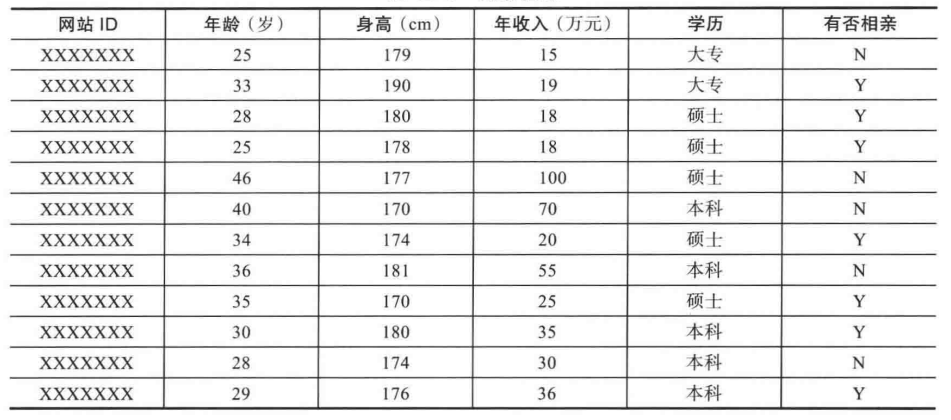
该女青年相亲决策主要考虑到因素有年龄,身高,年收入,学历。同事由该女青年的相亲决策图可以看到,相亲决策树以年龄与35岁相比作为树根。但是其他的数据项也能做树根。因此选择合适的数据项作为树根十分重要。在决策树中由信息增益确定树根。
信息增益
在提出信息增益前,需要对理解信息熵(香农熵,information entropy)这个概念。信息熵(entropy)描述整个体系的混乱程度,熵越大,体系混乱程度越大。例如火柴有序的放在火柴盒子里,则熵值很低,反之,熵值很高。
整个体系的信息熵的计算公式如下:
$$Info=-\sum_{i=1}^{m}p_{i}log_{2}p_{i}$$
其中m表示最后决策的种类。前面女青年相亲的例子,最后决策分为相亲和不相亲,则m=2。其中Y(相亲)概率为7/12,
N(不相亲)概率为5/12。信息熵为:
$$Info=-\left(\frac{7}{12}log_{2}\frac{7}{12}+\frac{5}{12}log_{2}\frac{5}{12}\right )=0.98 bit$$
树根的选择十分重要。选择树根的原则首先确定最佳因素如确定为年龄,然后再确定分割节点如确定年龄为35岁为分割节点,分割后获得两棵子树。然后根据其他因素选择树根,再次对所获得的两棵子树分割。通过熵来评价分割结果,当熵越大,则接下分割难度越大,分割次数越多;熵越小则分割难度越小,分割次数越小。这个划分规则下以某因素A来划分,所得划分熵如下:
$$Info_{A}=-\sum_{j=1}^{v}p_{j}\cdot Info(A_{j})$$
上式中v表示所选因素A一共有多少组,如A为学历时v=3。\(P_(j)\)表示这种分组所占比重。如学历有可以被划分为3组,大专、本科、硕士。则当所选因素为A时,信息熵为:

最后求的近似值\(Info_{A}=0.872\)
对于信息增益,前后的信息熵变化值为信息增益。信息增益越大表明分割效果越好。对于以学历为分割因素时的信息增益如下:

sklearn实现
sklearn中对应的函数DecisionTreeClassifier函数(分类),DecisionTreeRegressor(回归),分类代码如下
from sklearn import tree
import numpy as np
#年龄,身高,年收入,学历(大专:0,本科:1,硕士:2)
X = np.array(
[[25, 179, 15, 0],
[33, 190, 19 ,0],
[28, 180, 18, 2],
[25, 178, 18, 2],
[46, 100, 100, 2],
[40, 170, 170, 1],
[34, 174, 20, 2],
[36, 181, 55, 1],
[35, 170, 25, 2],
[30, 180, 35, 1],
[28, 174, 30, 1],
[29, 176, 36, 1]])
#0表示没有相亲,1表示相亲
y= [0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1]
clf = tree.DecisionTreeClassifier().fit(X, y)
p=[[28, 180, 18, 2]]
print(clf.predict(p)) #[1]函数其他参数改动可参考官网文档:
http://scikit-learn.org/stable/modules/tree.html#tree-classification
另外可以将sklearn所生成的决策可视化,具体参考链接:
随机森林
随机森林(Random Forest)是一个构建决策树的过程,目标是构建许多棵决策树。随机森林会为一个训练集根据不同的因素构建若干棵决策,每棵树的层级都比较浅。对新样本进行分类判断时候会同时对这些决策树进行分类概率判断,最后进行投票,哪个类别多,输入的样本就属于哪个类别。其分类方式也就是通过若干个分类器进行组合集成学习。
sklearn实现
sklearn中对应的函数RadomForestClassifier函数(分类),RadomForestRegressor(回归),分类代码如下
from sklearn.ensemble import RandomForestClassifier
import numpy as np
#年龄,身高,年收入,学历(大专:0,本科:1,硕士:2)
X = np.array(
[[25, 179, 15, 0],
[33, 190, 19 ,0],
[28, 180, 18, 2],
[25, 178, 18, 2],
[46, 100, 100, 2],
[40, 170, 170, 1],
[34, 174, 20, 2],
[36, 181, 55, 1],
[35, 170, 25, 2],
[30, 180, 35, 1],
[28, 174, 30, 1],
[29, 176, 36, 1]])
#0表示没有相亲,1表示相亲
y= [0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1]
clf =RandomForestClassifier().fit(X, y)
p=[[28, 180, 18, 2]]
print(clf.predict(p)) #[1]函数 其他参数改动可参考官网文档:
http://scikit-learn.org/stable/modules/ensemble.html#random-forests
隐马尔可夫模型
隐马尔可夫模型和贝叶斯信念网络的模型思维方式比较接近。区别在于隐马尔可夫模型更简单,也可以说隐马尔可夫模型是贝叶斯信念网络的一种特例。但是sklearn中没有实现隐马尔可夫模型的函数库。
隐马尔可夫模型理论见文档:如何用简单易懂的例子解释隐马尔可夫模型? - Yang Eninala的回答 - 知乎
在IPython Notebook有隐马尔可夫模型的实现,具体见:
https://github.com/hmmlearn/hmmlearn
[sklearn] 决策树、随机森林、隐马尔可夫模型的更多相关文章
- HMM隐马尔可夫模型来龙去脉(一)
目录 隐马尔可夫模型HMM学习导航 一.认识贝叶斯网络 1.概念原理介绍 2.举例解析 二.马尔可夫模型 1.概念原理介绍 2.举例解析 三.隐马尔可夫模型 1.概念原理介绍 2.举例解析 四.隐马尔 ...
- [综]隐马尔可夫模型Hidden Markov Model (HMM)
http://www.zhihu.com/question/20962240 Yang Eninala杜克大学 生物化学博士 线性代数 收录于 编辑推荐 •2216 人赞同 ×××××11月22日已更 ...
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- HMM隐马尔科夫模型
这是一个非常重要的模型,凡是学统计学.机器学习.数据挖掘的人都应该彻底搞懂. python包: hmmlearn 0.2.0 https://github.com/hmmlearn/hmmlearn ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型(HMM)及事实上现
马尔科夫模型 马尔科夫模型是单重随机过程,是一个2元组:(S,A). 当中S是状态集合,A是状态转移矩阵. 仅仅用状态转移来描写叙述随机过程. 马尔科夫模型的2个如果 有限历史性如果:t+l时刻系统状 ...
- 【整理】图解隐马尔可夫模型(HMM)
写在前面 最近在写论文过程中,研究了一些关于概率统计的算法,也从网上收集了不少资料,在此整理一下与各位朋友分享. 隐马尔可夫模型,简称HMM(Hidden Markov Model), 是一种基于概率 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- NLP —— 图模型(一)隐马尔可夫模型(Hidden Markov model,HMM)
本文简单整理了以下内容: (一)贝叶斯网(Bayesian networks,有向图模型)简单回顾 (二)隐马尔可夫模型(Hidden Markov model,HMM) 写着写着还是写成了很规整的样 ...
随机推荐
- Spring 深入——IoC 容器 01
IoC容器的实现学习--01 目录 IoC容器的实现学习--01 简介 IoC 容器系列的设计与实现:BeanFactory 和 ApplicationContext BeanFactory load ...
- 2. 单主机 Elasticsearch 双节点或多节点集群环境部署
我已经买了一年的腾讯云轻量级服务器,并且安装好了ES,也做了一些系统配置,比如 修改vm.max_map_count.修改文件描述符数量 同时,也用ES安装目录下的 bin/elasticsearch ...
- springboot的注解声明过滤器配置错误导致拦截所有请求。
究其原因, 原来spring 扫包时候 扫了Webfilter 注解,注册了一次过滤匹配路径,扫了Component注解(又注册了一次过滤匹配路径,默认是全路径). Component注解后于WebF ...
- MFC-创建MFC图形界面dll
创建MFC图形界面dll 概述: 利用MFC的DLL框架,制作带有图形界面的dll,可以实现很多功能. 流程: 选择静态链接MFC DLL:以免有的库没有. 采用该框架创建的MFC,会自动生产一个MF ...
- 发送HTTP请求方法- 留着自用
/** * 发送HTTP请求方法,目前只支持CURL发送请求 * @param string $url 请求URL * @param array $data POST的数据,GET请求时该参数无效 * ...
- 【JavaWeb】学习笔记——Ajax、Axios
Ajax Ajax 介绍 AJAX(Asynchronous JavaScript And XML):异步的JavaScript 和 XML AJAX 的作用: 与服务器进行数据交换:通过AJAX可以 ...
- windows和虚拟机上的Ubuntu互传文件
1.简介 本文讲述的是通过ssh登录虚拟机上的Ubuntu系统,实现互传文件 2.Ubuntu端 2.1.安装ssh sudo apt-get update sudo apt-get install ...
- LoadRunner11脚本小技能之同步/异步接口分离+批量替换请求头
最近在公司又进行了一次LoadRunner11性能测试,技能又get了一点,继续Mark起来!!! 一.异步/同步接口分离 之前在另一篇博文中有提到"事务拆分"的小节,即一个htm ...
- OS-HACKNOS-2.1靶机之解析
靶机名称 HACKNOS: OS-HACKNOS 靶机下载地址 https://download.vulnhub.com/hacknos/Os-hackNos-1.ova 实验环境 : kali 2. ...
- Websocket集群解决方案
最近在项目中在做一个消息推送的功能,比如客户下单之后通知给给对应的客户发送系统通知,这种消息推送需要使用到全双工的websocket推送消息. 所谓的全双工表示客户端和服务端都能向对方发送消息.不使用 ...