#Python基础 pandas索引设置
一:XMIND
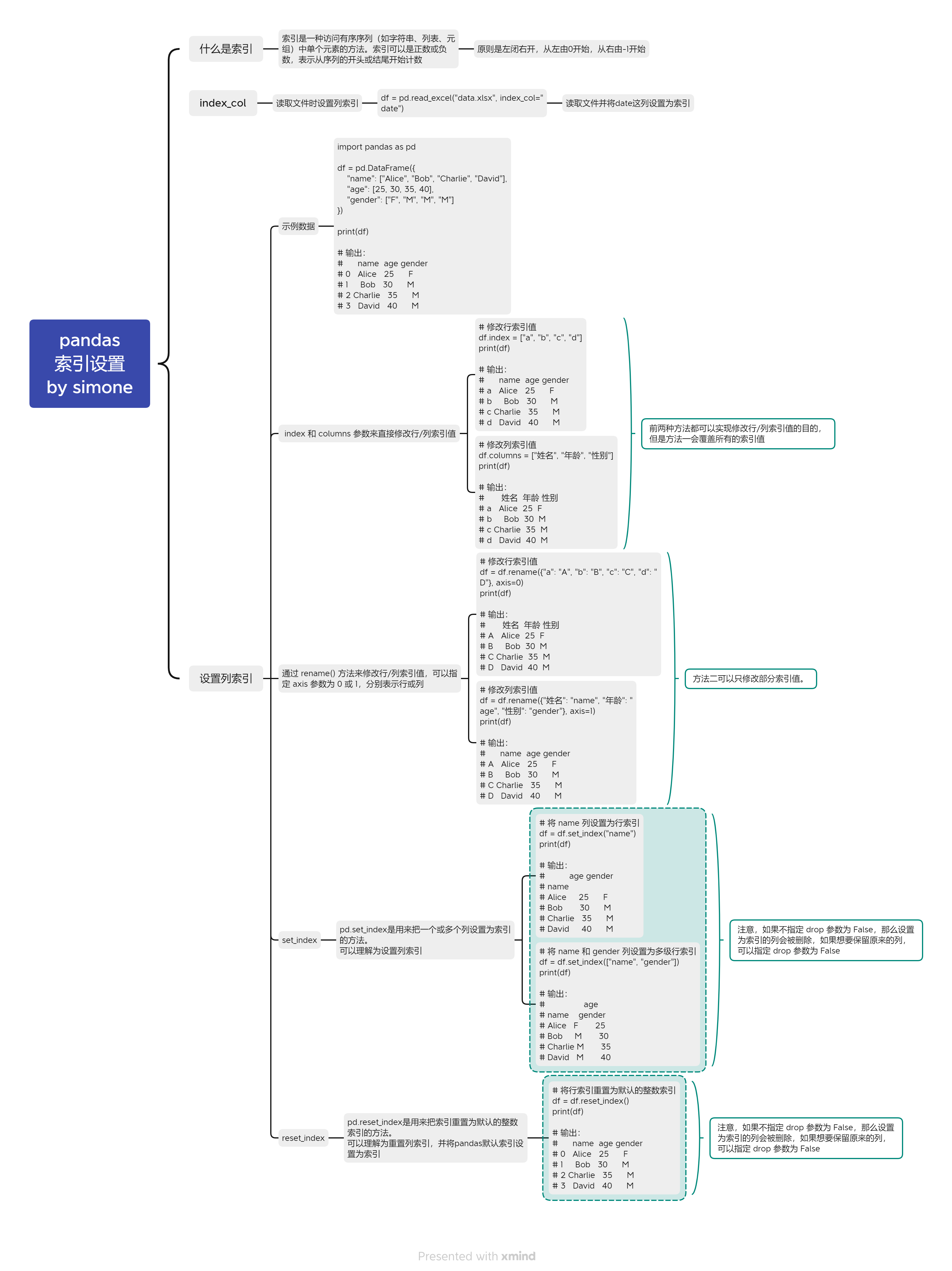
二:设置索引
示例数据,假设我们有一个DataFrame对象,如下:
import pandas as pd
df = pd.DataFrame({
"name": ["Alice", "Bob", "Charlie", "David"],
"age": [25, 30, 35, 40],
"gender": ["F", "M", "M", "M"]
})
print(df)
# 输出:
# name age gender
# 0 Alice 25 F
# 1 Bob 30 M
# 2 Charlie 35 M
# 3 David 40 M
2.1 读取时设置索引 index_col
df = pd.read_excel("data.xlsx", index_col="date")
在读取文件时,我们可以指定索引,上面代码指定了"date"这一列为行索引
2.2 重置/指定索引
2.2.1 index 和 columns 参数来直接修改行/列索引值
# 修改行索引值
df.index = ["a", "b", "c", "d"]
print(df) # 输出:
# name age gender
# a Alice 25 F
# b Bob 30 M
# c Charlie 35 M
# d David 40 M # 修改列索引值
df.columns = ["姓名", "年龄", "性别"]
print(df) # 输出:
# 姓名 年龄 性别
# a Alice 25 F
# b Bob 30 M
# c Charlie 35 M
# d David 40 M
2.2.2 rename() 方法,传入一个字典,映射原来的索引值和新的索引值
# 修改行索引值
df = df.rename({"a": "A", "b": "B", "c": "C", "d": "D"}, axis=0)
print(df) # 输出:
# 姓名 年龄 性别
# A Alice 25 F
# B Bob 30 M
# C Charlie 35 M
# D David 40 M # 修改列索引值
df = df.rename({"姓名": "name", "年龄": "age", "性别": "gender"}, axis=1)
print(df) # 输出:
# name age gender
# A Alice 25 F
# B Bob 30 M
# C Charlie 35 M
# D David 40 M
2.2.3 set_index() 方法,传入列名或列名列表
# 将 name 列设置为行索引
df = df.set_index("name")
print(df) # 输出:
# age gender
# name
# Alice 25 F
# Bob 30 M
# Charlie 35 M
# David 40 M # 将 name 和 gender 列设置为多级行索引
df = df.set_index(["name", "gender"])
print(df) # 输出:
# age
# name gender
# Alice F 25
# Bob M 30
# Charlie M 35
# David M 40
2.2.4 reset_index,行索引重置为默认的整数索引,可以使用 reset_index() 方法
pd.reset_index是用来把索引重置为默认的整数索引的方法。可以理解为重置列索引,并将pandas默认索引设置为索引
# 将行索引重置为默认的整数索引
df = df.reset_index()
print(df) # 输出:
# name age gender
# 0 Alice 25 F
# 1 Bob 30 M
# 2 Charlie 35 M
# 3 David 40 M
#Python基础 pandas索引设置的更多相关文章
- Python基础 — Pandas
Pandas -- 简介 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的. Pandas ...
- Python基础 | pandas中dataframe的整合与形变(merge & reshape)
目录 行的union pd.concat df.append 列的join pd.concat pd.merge df.join 行列转置 pivot stack & unstack melt ...
- 【python】pandas 索引操作
选择.修改数据(单层索引) 推荐使用.at..iat..loc..iloc 操作 句法 结果 备注 选择列 df[col] Series 基于列名(列的标签),返回Series 用标签选择行 df.l ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- Python 基础教程 —— Pandas 库常用方法实例说明
目录 1. 常用方法 pandas.Series 2. pandas.DataFrame ([data],[index]) 根据行建立数据 3. pandas.DataFrame ({dic}) ...
- python基础(四):切片和索引
Python中的序列有元组.列表和字符串,因此我们都可以通过索引和切片的方式,来获取其中的元素. 索引 Python中的索引,对于正向索引,都是从0开始的.但是对于反向索引,确实从-1开始的.如图所示 ...
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python模块-pandas
目录 数据读取 数据探索 数据清洗 数据清洗 类型转换 缺失值 重复值 值替换 修改表结构 新增列 删除列 删除行 修改列名 数据分组(数值变量) 数据分列(分类变量) 设置索引 排序 数据筛选/切片 ...
- python基础整理4——面向对象装饰器惰性器及高级模块
面向对象编程 面向过程:根据业务逻辑从上到下写代码 面向对象:将数据与函数绑定到一起,进行封装,这样能够更快速的开发程序,减少了重复代码的重写过程 面向对象编程(Object Oriented Pro ...
随机推荐
- AtCoder-abc230_g GCD Permutation 容斥
J - GCD Permutation 传送门: J - GCD Permutation 知识点:素数筛.容斥定理.gcd 题意:长度为n的一个排列a中,求满足\(gcd(i,j)!=1 且 gcd( ...
- 为什么对1e9 + 7取模
在刷题的时候,很多题目答案都要求结果对1e9 + 7取模 刚开始我非常不理解,为什么要取模,取模难道结果不会变吗? 答案是结果会变,但因为原本需要得出的答案可能超出int64的范围,比如他叫你计算50 ...
- appium 遇到连接设备状态是offline
1.查看连接手机设备 adb derivces 时,手机状态是offline状态(无法正常连接). 解决法: 1.adb kill-server 终止adb调试服务 2.adb start-serve ...
- lua脚本概述
1.lua脚本非常简单,轻量级,易于c/c++调用 2. 协程 是什么,与线程有啥区别 ??
- H5-生成二维码
<div class="poster-qr"> <div class="qrWrapper"> <!-- 放置二维码的容器 --& ...
- JS中我们为什么要new个实例而不直接执行
正常情况:<script> function sayHello() { alert("hello") } sayHello();直接调用他 </script> ...
- Django笔记十二之defer、only指定返回字段
本篇笔记为Django笔记系列之十二,首发于公号[Django笔记] 本篇笔记将介绍查询中的 defer 和 only 两个函数的用法,笔记目录如下: defer only 1.defer defer ...
- [Java/LeetCode]算法练习:二进制间距(868/simple)
1 题目描述 题目来源: https://leetcode-cn.com/problems/binary-gap/ 给定一个正整数 n,找到并返回 n 的二进制表示中两个 相邻 1 之间的 最长距离 ...
- mysql 求分组中位数、环比、同比、中位数的环比
说明 中位数.环比.同比概念请自行百度,本文求 字段A中位数.根据字段B分组后字段A中位数.字段A环比.字段A同比.字段A中位数的环比.字段A中位数的同比. 一.表结构如下图 查询条件为 capi ...
- 3.@RequestParma和@PathVariable的用法和区别
前言 我相信很多程序员都会在自己的项目中使用到Restful风格来安全便捷地进行接口的编写,因此本文这篇博客来简要介绍一下controller方法中的两个注解:@RequestParma和@PathV ...