重磅!Vertica集成Apache Hudi指南
1. 摘要
本文演示了使用外部表集成 Vertica 和 Apache Hudi。 在演示中我们使用 Spark 上的 Apache Hudi 将数据摄取到 S3 中,并使用 Vertica 外部表访问这些数据。
2. Apache Hudi介绍
Apache Hudi 是一种变更数据捕获 (CDC) 工具,可在不同时间线将事务记录在表中。 Hudi 代表 Hadoop Upserts Deletes and Incrementals,是一个开源框架。 Hudi 提供 ACID 事务、可扩展的元数据处理,并统一流和批处理数据处理。
以下流程图说明了该过程。 使用安装在 Apache Spark 上的 Hudi 将数据处理到 S3,并从 Vertica 外部表中读取 S3 中的数据更改。

3. 环境准备
- Apache Spark 环境。 使用具有 1 个 Master 和 3 个 Worker 的 4 节点集群进行了测试。 按照在多节点集群上设置 Apache Spark 中的说明安装 Spark 集群环境。 启动 Spark 多节点集群。
- Vertica 分析数据库。 使用 Vertica Enterprise 11.0.0 进行了测试。
- AWS S3 或 S3 兼容对象存储。 使用 MinIO 作为 S3 存储桶进行了测试。
- 需要以下 jar 文件。将 jar 复制到 Spark 机器上任何需要的位置,将这些 jar 文件放在 /opt/spark/jars 中。
- Hadoop - hadoop-aws-2.7.3.jar
- AWS - aws-java-sdk-1.7.4.jar
- 在 Vertica 数据库中运行以下命令来设置访问存储桶的 S3 参数:
SELECT SET_CONFIG_PARAMETER('AWSAuth', 'accesskey:secretkey');
SELECT SET_CONFIG_PARAMETER('AWSRegion','us-east-1');
SELECT SET_CONFIG_PARAMETER('AWSEndpoint',’<S3_IP>:9000');
SELECT SET_CONFIG_PARAMETER('AWSEnableHttps','0');
endpoint可能会有所不同,具体取决于 S3 存储桶位置选择的 S3 对象存储。
4. Vertica和Apache Hudi集成
要将 Vertica 与 Apache Hudi 集成,首先需要将 Apache Spark 与 Apache Hudi 集成,配置 jars,以及访问 AWS S3 的连接。 其次,将 Vertica 连接到 Apache Hudi。 然后对 S3 存储桶执行 Insert、Append、Update 等操作。
按照以下部分中的步骤将数据写入 Vertica。
在 Apache Spark 上配置 Apache Hudi 和 AWS S3
配置 Vertica 和 Apache Hudi 集成
4.1 在 Apache Spark 上配置 Apache Hudi 和 AWS S3
在 Apache Spark 机器中运行以下命令。
这会下载 Apache Hudi 包,配置 jar 文件,以及 AWS S3
/opt/spark/bin/spark-shell \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"\--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1
导入Hudi的读、写等所需的包:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
使用以下命令根据需要配置 Minio 访问密钥、Secret key、Endpoint 和其他 S3A 算法和路径。
spark.sparkContext.hadoopConfiguration.set("fs.s3a.access.key", "*****")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.secret.key", "*****")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.endpoint", "http://XXXX.9000")
spark.sparkContext.hadoopConfiguration.set("fs.s3a.path.style.access", "true")
sc.hadoopConfiguration.set("fs.s3a.signing-algorithm","S3SignerType")
创建变量来存储 MinIO 的表名和 S3 路径。
val tableName = “Trips”
val basepath = “s3a://apachehudi/vertica/”
准备数据,使用 Scala 在 Apache spark 中创建示例数据
val df = Seq(
("aaa","r1","d1",10,"US","20211001"),
("bbb","r2","d2",20,"Europe","20211002"),
("ccc","r3","d3",30,"India","20211003"),
("ddd","r4","d4",40,"Europe","20211004"),
("eee","r5","d5",50,"India","20211005"),
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")
将数据写入 AWS S3 并验证此数据
df.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
使用 Scala 运行以下命令以验证是否从 S3 存储桶中正确读取数据。
spark.read.format("hudi").load(basePath).createOrReplaceTempView("dta")
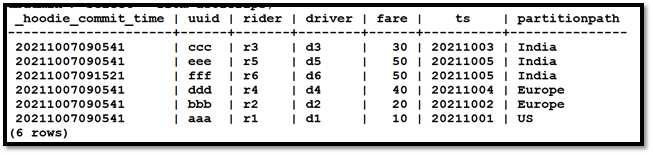
spark.sql("select _hoodie_commit_time, uuid, rider, driver, fare,ts, partitionpath from dta order by uuid").show()
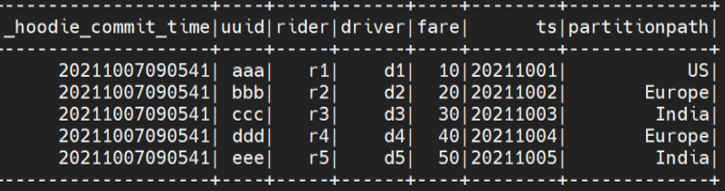
4.2 配置 Vertica 和 Apache HUDI 集成
在 vertica 中创建一个外部表,其中包含来自 S3 上 Hudi 表的数据。 我们创建了“旅行”表。
CREATE EXTERNAL TABLE Trips
(
_hoodie_commit_time TimestampTz,
uuid varchar,
rider varchar,
driver varchar,
fare int,
ts varchar,
partitionpath varchar
)
AS COPY FROM
's3a://apachehudi/parquet/vertica/*/*.parquet' PARQUET;
运行以下命令以验证正在读取外部表:

4.3 如何让 Vertica 查看更改的数据
以下部分包含为查看 Vertica 中更改的数据而执行的一些操作的示例。
4.3.1 写入数据
在这个例子中,我们使用 Scala 在 Apache spark 中运行了以下命令并附加了一些数据:
val df2 = Seq(
("fff","r6","d6",50,"India","20211005")
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")
运行以下命令将此数据附加到 S3 上的 Hudi 表中:
df2.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
4.3.2 更新数据
在这个例子中,我们更新了一条 Hudi 表的记录。 需要导入数据以触发并更新数据:
val df3 = Seq(
("aaa","r1","d1",100,"US","20211001"),
("eee","r5","d5",500,"India","20211001")
).toDF("uuid", "rider", "driver","fare","partitionpath","ts")
运行以下命令将数据更新到 S3 上的 HUDI 表:
df3.write.format("org.apache.hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
以下是 spark.sql 的输出:
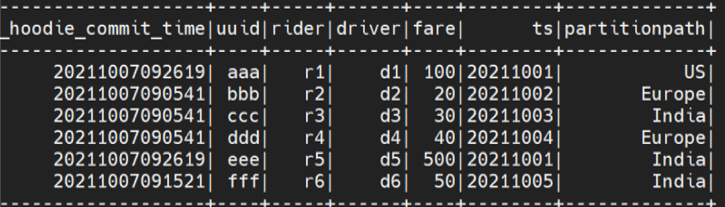
以下是 Vertica 输出:
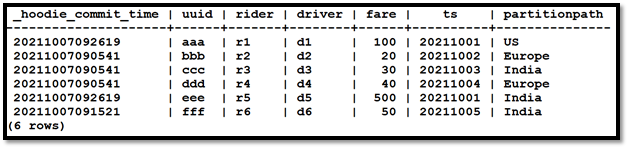
4.3.3 创建和查看数据的历史快照
执行以下指向特定时间戳的 spark 命令:
val dd = spark.read
.format("hudi")
.option("as.of.instant", "20211007092600")
.load(basePath)
使用以下命令将数据写入 S3 中的 parquet:
dd.write.parquet("s3a://apachehudi/parquet/p2")
在此示例中,我们正在读取截至“20211007092600”日期的 Hudi 表快照。
dd.show
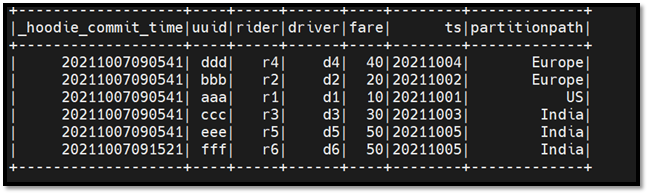
通过在 parquet 文件上创建外部表从 Vertica 执行命令。
重磅!Vertica集成Apache Hudi指南的更多相关文章
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 在AWS Glue中使用Apache Hudi
1. Glue与Hudi简介 AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务.对于不了解该产品的读 ...
- Apache Hudi 0.8.0版本重磅发布
1. 重点特性 1.1 Flink集成 自从Hudi 0.7.0版本支持Flink写入后,Hudi社区又进一步完善了Flink和Hudi的集成.包括重新设计性能更好.扩展性更好.基于Flink状态索引 ...
- Apache Hudi又双叕被国内顶级云服务提供商集成了!
是的,最近国内云服务提供商腾讯云在其EMR-V2.2.0版本中优先集成了Hudi 0.5.1版本作为其云上的数据湖解决方案对外提供服务 Apache Hudi 在 HDFS 的数据集上提供了插入更新和 ...
- Apache Hudi重磅特性解读之存量表高效迁移机制
1. 摘要 随着Apache Hudi变得越来越流行,一个挑战就是用户如何将存量的历史表迁移到Apache Hudi,Apache Hudi维护了记录级别的元数据以便提供upserts和增量拉取的核心 ...
- Apache Hudi 0.6.0版本重磅发布
1. 下载信息 源码:Apache Hudi 0.6.0 Source Release (asc, sha512) 二进制Jar包:nexus 2. 迁移指南 如果您从0.5.3以前的版本迁移至0.6 ...
- Apache Hudi与Apache Flink集成
感谢王祥虎@wangxianghu 投稿 Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目.是当前最 ...
- 重磅!解锁Apache Flink读写Apache Hudi新姿势
感谢阿里云 Blink 团队Danny Chan的投稿及完善Flink与Hudi集成工作. 1. 背景 Apache Hudi 是目前最流行的数据湖解决方案之一,Data Lake Analytics ...
- Apache Hudi集成Spark SQL抢先体验
Apache Hudi集成Spark SQL抢先体验 1. 摘要 社区小伙伴一直期待的Hudi整合Spark SQL的PR正在积极Review中并已经快接近尾声,Hudi集成Spark SQL预计会在 ...
随机推荐
- 从Spring容器的角度理解Dubbo扩展点的加载时机
对于Dubbo提供的扩展点,主程序执行的过程中并没有显示调用加载的过程,无论是自激活的Filter还是自适应的ThreadPool.那么这样的扩展点在程序运行的哪个节点调用的呢?跟踪之前性能监控扩展点 ...
- logstash获取nginx日志的配置
nginx部分配置直接用json,省去很多麻烦 log_format json '{"@timestamp":"$time_iso8601",' '" ...
- [Java]Thinking in Java 练习2.12
题目 对HelloDate.java的简单注释文档的示例执行javadoc,然后通过Web浏览器查看结果. 代码 1 //: HW/Ex2_2.java 2 import java.util.*; 3 ...
- [旧][Android] LayoutInflater 工作流程
备注 原发表于2016.06.20,资料已过时,仅作备份,谨慎参考 前言 感觉很长时间没写文章了,这个星期因为回家和处理项目问题,还是花了很多时间的.虽然知道很多东西如果只是看一下用一次,很快就会遗忘 ...
- SRv6规模部署,离不开测试技术保驾护航!
什么是SRv6? SRv6技术就是采用现有的IPv6转发技术,通过扩展IPv6报文的头域,实现类似标签转发的处理.SRv6将一些IPv6地址定义成实例化的SID(Segment ID),每个SID有着 ...
- 关于Dll、Com组件、托管dll和非托管dll
转自:https://blog.csdn.net/black_bad1993/article/details/53906252 Com组件 1.线程模型是干嘛用的?解决"多个线程" ...
- linux centos7下 c++编程
在Linux下与在windos下编程没啥区别,可以在windos上实现后,然后更改一些,移植到linux中 yum install gcc yum install gcc-c++ vi main.cp ...
- Docker入坑系列(二)
Docker入坑系列(二) 上一篇我们为Docker创造了一个良好的生活环境,这一篇我们就开始让Docker活起来. 安装Docker ok,原文地址在这里. 当然,我只是自己翻译了一下而已- -跟着 ...
- Qt:QCustomPlot使用教程(三)——用户交互
0.说明 本节翻译总结自:Qt Plotting Widget QCustomPlot - User Interactions 本节内容是使用QCustomPlot实现绘图和用户交互功能. 本文代码中 ...
- 在win10操作系统中pycharm启动时无法打开的解决方法
''' 当打开pycharm时报错 Error launching Pycharm Failed to load JVM DLL C:\Program Files\Jetbrains\Pycharm ...