#测试两种不同的SVM,rbf的核真是太棒了(一种会拐弯的边界)
from sklearn import datasets
import numpy as np X, y = datasets.make_blobs(n_features=2, centers=2)
from sklearn.svm import LinearSVC
from sklearn.svm import SVC #测试两种不同的SVM,rbf的核真是太棒了 #svm = LinearSVC()
svm = SVC(kernel='rbf')
svm.fit(X, y)
'''
>>> y
array([1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0,
0, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0,
1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0,
1, 1, 1, 1, 0, 0, 0, 0])
>>> X[:5]
array([[ -7.16607012, 8.67278838],
[ -1.9444707 , 4.79203099],
[ -8.13823925, 8.61203039],
[ -8.46098709, 11.73701048],
[ -0.72791284, 6.20893784]])
>>>
''' '''
Now that we have fit the support vector machine,
we will plot its outcome at each point in the
graph.
This will show us the approximate decision boundary:
''' from itertools import product
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y', 'outcome']) #寻找X轴、y轴的最小值和最大值
xmin, xmax = np.percentile(X[:, 0], [0, 100]) #等同 X[:,0].min()
ymin, ymax = np.percentile(X[:, 1], [0, 100])
'''
>>> X[:,0].min()
-10.02996504991013
>>> xmin
-10.02996504991013
>>> X[:,0].max()
1.6856669658909862
>>> xmax
1.6856669658909862
>>> X[:,1].min()
3.3455301726833886
>>> X[:,1].max()
11.737010478926441
'''
#对X,y取值范围内的任何一点,都用SVC进行预测,布成一张网
#下面的20指的是,在哪个取值范围内,选取多少个点
decision_boundary = []
for xpt, ypt in product(np.linspace(xmin-2.5, xmax+2.5, 50),np.linspace(ymin-2.5, ymax+2.5, 50)):
#zz = svm.predict([xpt, ypt])
p = Point(xpt, ypt, svm.predict([xpt, ypt]))
decision_boundary.append(p) import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(7, 5))
import numpy as np
colors = np.array(['r', 'b'])
for xpt, ypt, pt in decision_boundary:
ax.scatter(xpt, ypt, color=colors[pt[0]], alpha=.15,s=50)
#pt是一个数组,只有一个元素,就是预测的分类(0或1)
#特别注意,这是背景色,注意alpha=.15,背景很淡
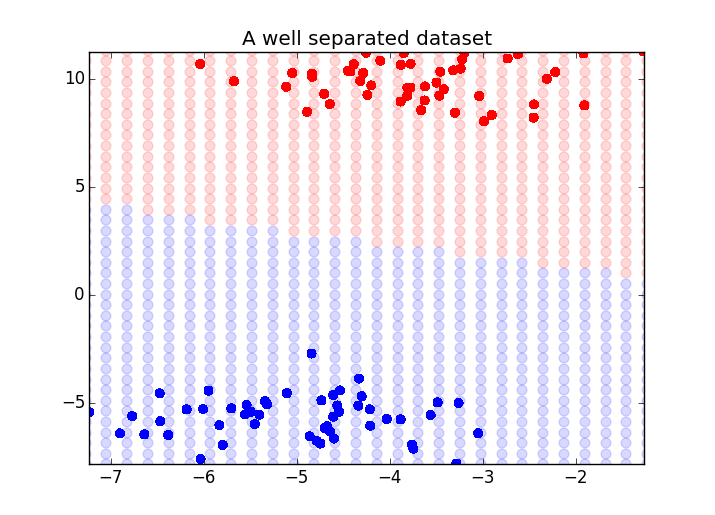
ax.scatter(X[:, 0], X[:, 1], color=colors[y], s=30) #y是原始值,原始分类
ax.set_ylim(ymin, ymax)
ax.set_xlim(xmin, xmax)
ax.set_title("A well separated dataset")
f.show() #另外一个边界不清晰的例子
X, y = datasets.make_classification(n_features=2,n_classes=2,n_informative=2,n_redundant=0)
svm.fit(X, y)
xmin, xmax = np.percentile(X[:, 0], [0, 100])
ymin, ymax = np.percentile(X[:, 1], [0, 100])
test_points = np.array([[xx, yy] for xx, yy in product(np.linspace(xmin, xmax),np.linspace(ymin, ymax))])
test_preds = svm.predict(test_points) import matplotlib.pyplot as plt
f, ax = plt.subplots(figsize=(7, 5))
import numpy as np
colors = np.array(['r', 'b'])
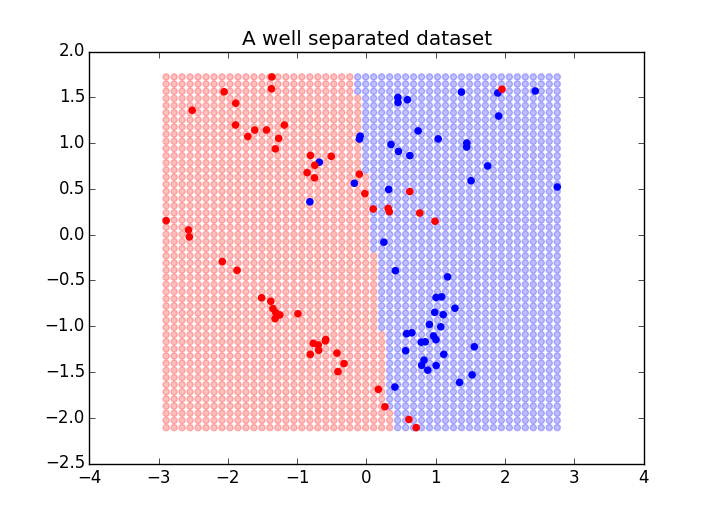
ax.scatter(test_points[:, 0], test_points[:, 1],color=colors[test_preds], alpha=.25)
ax.scatter(X[:, 0], X[:, 1], color=colors[y])
ax.set_title("A well separated dataset")
f.show()


#测试两种不同的SVM,rbf的核真是太棒了(一种会拐弯的边界)的更多相关文章
- Java中的==符号与equals()的使用(测试两个变量是否相等)
Java 程序中测试两个变量是否相等有两种方式:一种是利用 == 运算符,另一种是利用equals()方法. 当使用 == 来判断两个变量是否相等时,如果两个变量是基本类型变量,且都是数值类型(不一定 ...
- Java-Runoob-高级教程-实例-字符串:10. Java 实例 - 测试两个字符串区域是否相等-uncheck
ylbtech-Java-Runoob-高级教程-实例-字符串:10. Java 实例 - 测试两个字符串区域是否相等 1.返回顶部 1. Java 实例 - 测试两个字符串区域是否相等 Java ...
- FMX有两种消息处理的实现方式,一种是用TMessageManager来实现自定义的消息,另外一种象TEdit中的实现,直接声明消息方法(firemonkey messaging)
看FMX代码,发现有两种消息处理的实现方式,一种是用TMessageManager来实现自定义的消息,另外一种象TEdit中的实现,直接声明消息方法. 早前,看过文章说TMessageManage ...
- 最棒的7种R语言数据可视化
最棒的7种R语言数据可视化 随着数据量不断增加,抛开可视化技术讲故事是不可能的.数据可视化是一门将数字转化为有用知识的艺术. R语言编程提供一套建立可视化和展现数据的内置函数和库,让你学习这门艺术.在 ...
- 503是一种HTTP状态码。英文名503 Service Unavailable与404(404 Not Found)是同属一种网页状态出错码。前者是服务器出错的一种返回状态,后者是网页程序没有相关的结果后返回的一种状态,需要优化网站的时候通常需要制作404出错页以便网站整体优化。
goldCat1 商城 消息 | 百度首页 新闻网页贴吧知道音乐图片视频地图百科文库 进入词条搜索词条帮助 近期有不法分子冒充官方收费编辑词条,百度百科严正声明:百科词条人人可编辑,词条创建和修改均免 ...
- 使用timeit模块 测试两种方式生成列表的所用的时间
from timeit import Timer def test(): li=[] for i in range(10000): li.append(i) def test2(): li=[i fo ...
- 最近两周我们接触到的两种线上抓娃娃机的技术实现方案(一种RTSP/一种RTMP)
线上抓娃娃机需求 最近线上抓娃娃机的项目火爆了,陆陆续续几十款线上抓娃娃机上架,还有一大波正在开发上线中,各大视频云提供商都在蹭热度发布自己的线上抓娃娃机方案,综合了一下,目前线上抓娃娃机的视频需求无 ...
- 【基础】这15种CSS居中的方式,你都用过哪几种?
简言 CSS居中是前端工程师经常要面对的问题,也是基本技能之一.今天有时间把CSS居中的方案汇编整理了一下,目前包括水平居中,垂直居中及水平垂直居中方案共15种.如有漏掉的,还会陆续的补充进来,算做是 ...
- 研究一下TForm.WMPaint过程(也得研究WM_ERASEBKGND)——TForm虽然继承自TWinControl,但是自行模仿了TCustomControl的全部行为,一共三种自绘的覆盖方法,比TCustomControl还多一种
先擦除背景: procedure TCustomForm.WMEraseBkgnd(var Message: TWMEraseBkgnd); begin if not IsIconic(Handle) ...
随机推荐
- mac 下面配置gradle
最近刚开始用gradle,先向大家介绍一下怎么配置gradle的环境变量吧: 1.下载最新安装包gradle-xxx-all.zip:http://www.gradle.org,并解压到/Users/ ...
- libvirt/qemu特性之numa
博客地址:http://blog.csdn.net/halcyonbaby 内容系本人学习.研究和总结,如有雷同,实属荣幸! Numa 查看主机node情况 使用virsh命令查看 virsh # c ...
- mogon操作数据库
返回的本来就是promise redis是内存数据库,更适合放session等一些东西.而mongo不是.
- R语言基础入门之二:数据导入和描述统计
by 写长城的诗 • October 30, 2011 • Comments Off This post was kindly contributed by 数据科学与R语言 - go there t ...
- 为mac编写swift脚本
代码示例: #!/usr/bin/env xcrun swift print("Hello World") 可以用Sublime Text编写,安装Swift包后有语法着色功能.然 ...
- MySQL 索引知识整理(创建高性能的索引)
前言: 索引优化应该是对查询性能优化的最有效的手段了.索引能够轻易将查询性能提高几个数量级. // 固态硬盘驱动器有和机械硬盘启动器,有着完全不同的性能特性: 然而即使是固态硬盘,索引的原则依然成立, ...
- 使用Fluentd + MongoDB构建实时日志收集系统
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方. 目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, Couch ...
- es6基础入门变量的解构赋值
let [a, b, c] = [1, 2, 3]; let [foo, [[bar], baz]] = [1, [[2], 3]]; foo bar baz let [ , , third] = [ ...
- spring发布RMI服务(-)
spring发布RMI服务 最近交流了一个项目,需要从RMI.WebService.接口文件中采集数据到大数据平台,下面自己测试了通过Spring发布RMI服务. 说明:RMI服务要求服务端和客户端都 ...
- Python - 批量改变文件名
import osimport sysimport datetime path = "E:\python_test"datename = '2016-02-11'a = datet ...